Correlazione e causalità: la coppia che non c’era
Una correlazione spuria si verifica quando una variabile nascosta o un fattore di confusione viene ignorato.
“Ma per misurare causa ed effetto, devi assicurarti che la semplice correlazione, per quanto allettante possa essere, non venga scambiata per una causa. Negli anni ’90, la popolazione di cicogne in Germania è aumentata e anche i tassi di natalità in casa dei tedeschi sono aumentati. Dobbiamo dare credito alle cicogne di aver trasportato i bambini?”
Neil deGrasse Tyson, astrofisico americano.
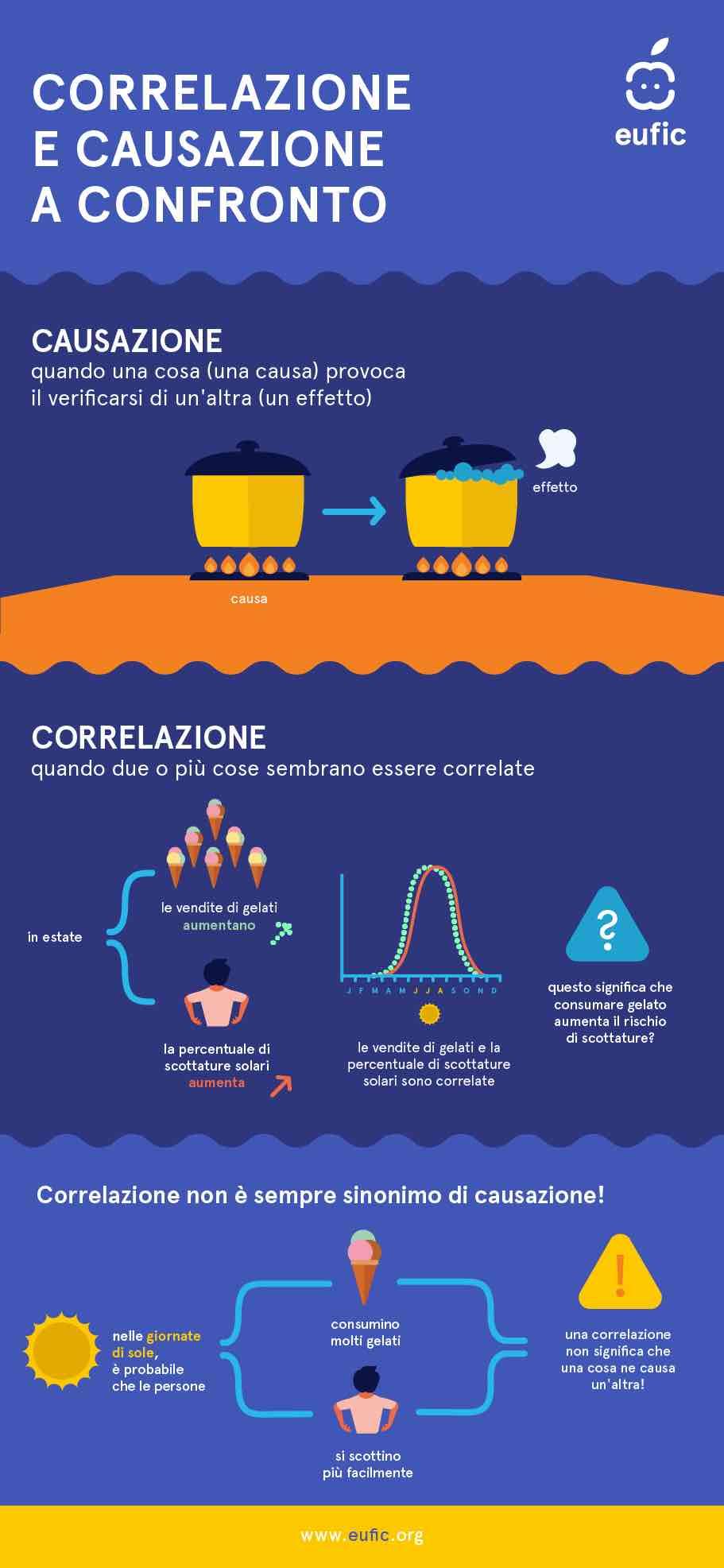
Uno dei principi fondamentali della statistica è: la correlazione non è causalità. La correlazione tra le variabili mostra uno schema nei dati e che queste variabili tendono a “muoversi insieme”. È abbastanza comune trovare correlazioni affidabili per due variabili, solo per scoprire che non sono affatto legate causalmente.
Prendete, per esempio, l’errore di omicidio del gelato. Questa teoria tenta di stabilire una correlazione tra l’aumento delle vendite di gelati con il tasso di omicidi. Quindi diamo la colpa all’innocuo gelato per l’aumento dei tassi di criminalità? L’esempio mostra quando due o più variabili sono correlate, le persone sono tentate di concludere una relazione tra loro. In questo caso, le correlazioni tra gelato e omicidio sono mere coincidenze statistiche.
Anche l’apprendimento automatico non è stato risparmiato da tali errori. Una differenza significativa tra le statistiche e l’apprendimento automatico è che mentre il primo si concentra sui parametri del modello, l’apprendimento automatico si concentra meno sui parametri e più sulle previsioni. I parametri nell’apprendimento automatico sono validi solo quanto la loro capacità di prevedere un risultato.
Spesso i risultati statisticamente significativi dei modelli di apprendimento automatico indicano correlazioni e causalità di fattori, quando in realtà è coinvolto un intero assortimento di vettori. Una correlazione spuria si verifica quando una variabile in agguato o un fattore di confusione viene ignorato e il pregiudizio cognitivo costringe un individuo a semplificare eccessivamente la relazione tra due incidenti completamente non correlati. Come nel caso della fallacia del gelato-omicidio, le temperature più calde (le persone consumano più gelato, ma occupano anche più spazi pubblici e sono soggette a crimini) è la variabile confondente che viene spesso ignorata.
La relazione errata correlazione-causalità sta diventando più significativa con l’aumento dei dati. Uno studio intitolato “The Diluvio of Spurious Correlations in Big Data” ha mostrato che le correlazioni arbitrarie aumentano con i set di dati in continua crescita. Lo studio ha affermato che tali correlazioni appaiono a causa della loro dimensione e non della loro natura. Lo studio ha rilevato che le correlazioni possono essere trovate in grandi database generati casualmente, il che implica che la maggior parte delle correlazioni sono spurie.
In ‘Il libro del perché. The New Science of Cause and Effect’, gli autori Judea Pearl e Dana Mackenzie hanno sottolineato che l’apprendimento automatico soffre di problemi di inferenza causale. Il libro dice che il deep learning è bravo a trovare schemi ma non può spiegare la sua relazione, una sorta di scatola nera. I Big Data sono visti come il proiettile d’argento per tutti i problemi di data science. Tuttavia, gli autori postulano che “i dati sono profondamente stupidi” perché possono solo raccontare un evento e non necessariamente perché è successo. I modelli causali, d’altra parte, compensano gli svantaggi di cui soffrono l’apprendimento profondo e il data mining. L’autore Pearl, vincitore del premio Turing e sviluppatore di reti bayesiane, pensa che il ragionamento causale potrebbe aiutare le macchine a sviluppare un’intelligenza simile a quella umana ponendo domande controfattuali.
IA causale
Negli ultimi tempi, il concetto di IA causale ha guadagnato molto slancio. Con l’intelligenza artificiale utilizzata in quasi tutti i campi, compresi i settori critici come l’assistenza sanitaria e la finanza, fare affidamento esclusivamente sui modelli predittivi dell’intelligenza artificiale potrebbe portare a risultati devastanti. L’IA causale può aiutare a identificare relazioni precise tra causa ed effetto. Cerca di modellare l’impatto degli interventi e dei cambiamenti di distribuzione utilizzando una combinazione di apprendimento e apprendimento basati sui dati che non fanno parte della descrizione statistica di un sistema.
Recentemente, i ricercatori dell’Università di Montreal, del Max Planck Institute for Intelligent Systems e di Google Research hanno dimostrato che le rappresentazioni causali aiutano a costruire la robustezza dei modelli di apprendimento automatico. Il team ha notato che la scoperta di relazioni causali richiede l’acquisizione di conoscenze solide oltre la distribuzione dei dati osservati e si estende a situazioni che coinvolgono il ragionamento.