L’idea chiave era quella di utilizzare reti neurali profonde per rappresentare la rete Q e addestrare questa rete a prevedere la ricompensa totale.
Le reti DQN o Deep-Q sono state proposte per la prima volta da DeepMind nel 2015 nel tentativo di portare i vantaggi dell’apprendimento profondo nell’apprendimento per rinforzo (RL), l’apprendimento per rinforzo si concentra sull’addestramento degli agenti a intraprendere qualsiasi azione in una fase particolare in un ambiente per massimizzare ricompense. L’apprendimento per rinforzo cerca quindi di addestrare il modello a migliorare se stesso e le sue scelte osservando le ricompense attraverso le interazioni con l’ambiente. Una semplice dimostrazione di tale apprendimento è mostrata nella figura sottostante.
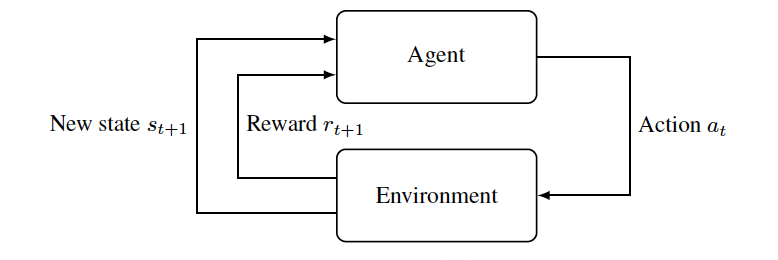
Ad esempio, immagina di addestrare un bot a giocare a un gioco come Ludo. Il bot giocherà con altri giocatori e ognuno di loro, incluso il bot, avrà quattro gettoni e un dado (che sarà il loro ambiente). La macchina dovrebbe quindi scegliere quale gettone pescare per muovere (cioè scegliere un’azione) in base a ciò che tutti gli altri hanno giocato e quanto il bot è vicino alla vittoria (lo stato). Il bot vorrà giocare in modo da vincere la partita (cioè massimizzare la sua ricompensa).
Cosa ha a che fare il Q-Learning con RL?
In Q-learning, viene costruita una tabella di memoria Q[s,a] per memorizzare i valori Q per ogni possibile combinazione di s e a (che denotano rispettivamente lo stato e l’azione). L’agente apprende una funzione Q-Value, che fornisce il rendimento totale atteso in un dato stato e coppia di azioni. L’agente deve quindi agire in modo da massimizzare questa funzione Q-Value.
L’agente può fare una singola mossa, a, e vedere la ricompensa che riceve, R. Quindi, R+Q(s’,a’) diventa il bersaglio che l’agente vorrebbe da Q(s,a).
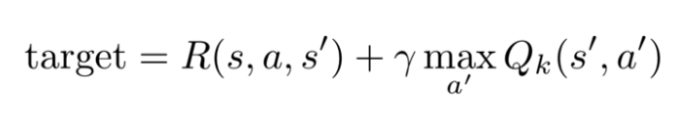
Dove γ indica un fattore di sconto per questa funzione. Ciò fa sì che i premi perdano il loro valore nel tempo, a causa del quale i premi più immediati sono più preziosi. Ad esempio, se tutti i valori Q sono uguali a 1, intraprendere un’altra azione e segnare 2 punti sposterebbe Q(s,a) più vicino a 3 (1+2). Man mano che l’agente continua a giocare, i valori Q convergeranno man mano che i premi continuano a diminuire di valore (specialmente se γ è inferiore a uno). Questo può essere visualizzato come il seguente algoritmo:

DQN
La memoria e il calcolo richiesti per l’algoritmo del valore Q sarebbero troppo alti. Pertanto, viene invece utilizzato un approssimatore di funzione Q-Learning di rete profonda. Questo algoritmo di apprendimento è chiamato Deep Q-Network (DQN). L’idea chiave in questo sviluppo era quindi quella di utilizzare reti neurali profonde per rappresentare la rete Q e addestrare questa rete a prevedere la ricompensa totale.
I precedenti tentativi di portare le reti neurali profonde nell’apprendimento per rinforzo non hanno avuto successo principalmente a causa delle instabilità. Le reti neurali profonde sono soggette a sovradattamento nei modelli di apprendimento per rinforzo, il che impedisce loro di essere generalizzate. Secondo DeepMind, gli algoritmi DQN affrontano queste instabilità fornendo dati di addestramento diversi e non correlati, archiviando tutte le esperienze dell’agente e campionando e riproducendo casualmente le esperienze.
In un articolo del 2013 , DeepMind ha testato DQN insegnandogli a imparare a giocare a sette giochi sulla console Atari 2600. In ogni fase temporale, l’agente osservava i pixel grezzi sullo schermo e un segnale di ricompensa corrispondente al punteggio del gioco e quindi selezionava una direzione del joystick. 2015 del DeepMind carta ampliato questo attraverso la formazione di agenti DQN separati per cinquanta Atari 2600 giochi (senza una preventiva conoscenza di come sono giocati questi giochi). DQN si è comportato altrettanto bene degli umani in quasi la metà di questi giochi, il che è stato un risultato migliore di ogni precedente tentativo di combinare l’apprendimento per rinforzo con le reti neurali.
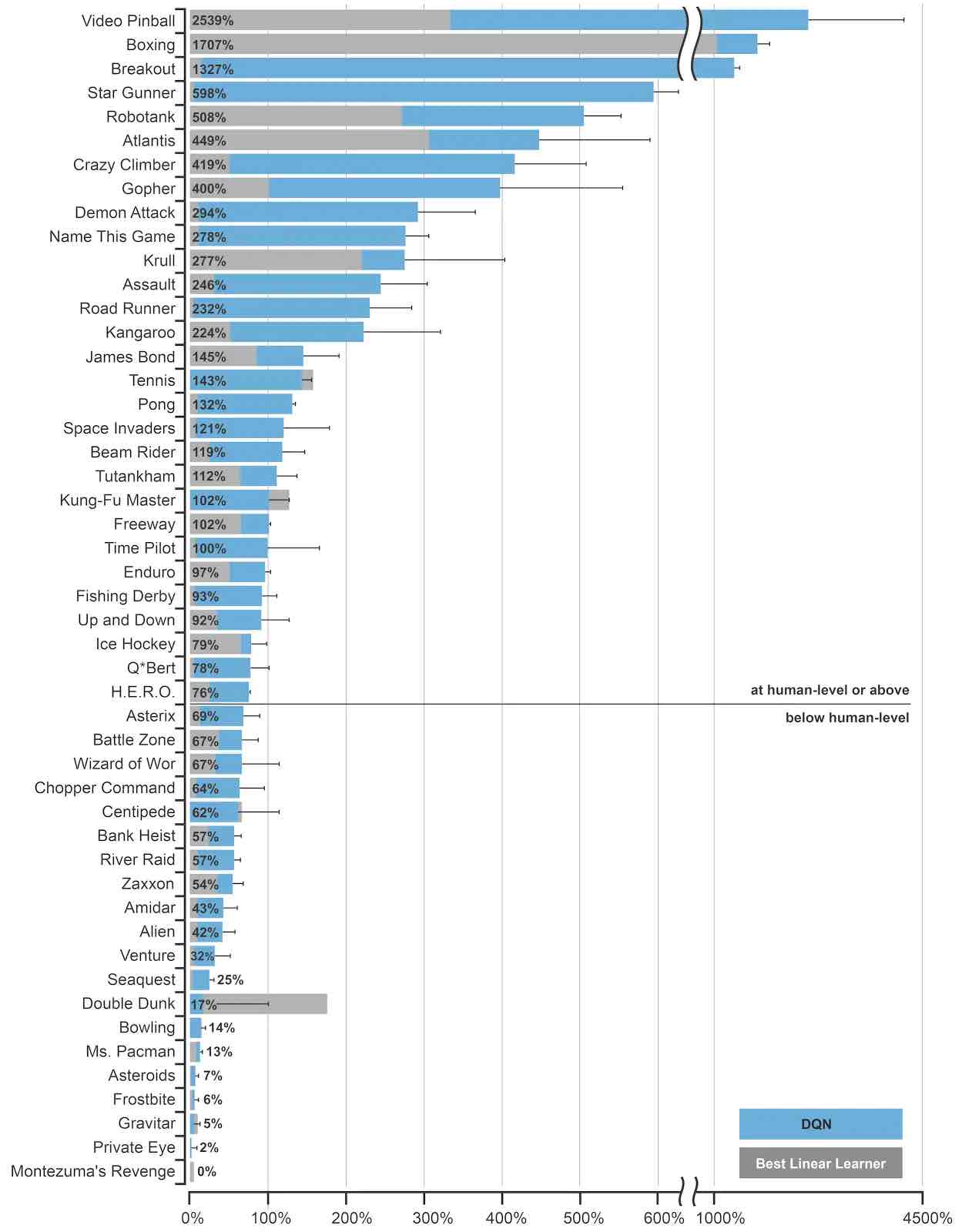
Fonte: DeepMind
DeepMind ha reso il suo codice sorgente DQN e l’ emulatore Atari 2600 disponibili gratuitamente per chiunque voglia lavorare e sperimentare se stesso. Il gruppo di ricerca ha anche migliorato il suo algoritmo DQN, inclusa l’ulteriore stabilizzazione delle sue dinamiche di apprendimento, la priorità delle esperienze riprodotte e la normalizzazione, nonché l’aggregazione e il ridimensionamento degli output. Con questi miglioramenti, DeepMind afferma che DQN può raggiungere prestazioni a livello umano in quasi tutti i giochi Atari e che una singola rete neurale può apprendere più di questi giochi.
Secondo DeepMind, l’obiettivo principale è sfruttare le capacità di DQN e utilizzarlo in applicazioni reali. Indipendentemente da quanto presto raggiungiamo questa fase, è abbastanza sicuro affermare che i modelli di apprendimento per rinforzo di DQN ampliano l’ambito dell’apprendimento automatico e la capacità delle macchine di affrontare una serie diversificata di sfide.