Questo robot ha utilizzato l’algoritmo Dreamer per imparare a camminare in 60 minuti
l’algoritmo Dreamer potrebbe imparare da piccole quantità di interazione attraverso la pianificazione in un modello del mondo appreso e, a sua volta, superare il puro apprendimento per rinforzo nei videogiochi.
Un team di ricercatori dell’Università della California, Berkeley, ha introdotto un approccio per insegnare ai robot come camminare in meno di 60 minuti. Questa tecnica è diversa dalle pratiche convenzionali di apprendimento per rinforzo profondo in modo tale che in questa tecnica i robot possono essere addestrati senza simulatori. Chiamato “DayDreamer: World Models for Physical Robot Learning”, questo progetto è guidato da Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg e Pieter Abbeel. Secondo gli autori, l’algoritmo Dreamer potrebbe imparare da piccole quantità di interazione attraverso la pianificazione in un modello del mondo appreso e, a sua volta, superare il puro apprendimento per rinforzo nei videogiochi.
DayDreamer: un approccio diverso all’apprendimento per rinforzo
Una delle sfide fondamentali con cui la robotica ha lottato è assorbire nei robot la capacità di risolvere compiti complessi in scenari del mondo reale. L’apprendimento per rinforzo profondo (RL) è un metodo popolare che consente ai robot di apprendere attraverso tentativi ed errori. Gli algoritmi attuali basati sull’apprendimento per rinforzo richiedono troppa interazione con un ambiente simulato per apprendere comportamenti di successo, il che li rende poco pratici per molte attività del mondo reale.
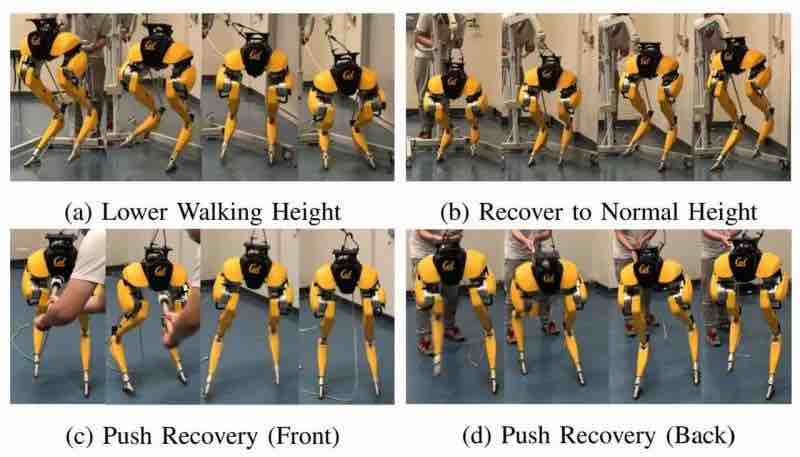
Per il progetto daydreamer, i ricercatori hanno applicato l’algoritmo Dreamer a quattro robot per apprendere direttamente nel mondo reale. Sono stati in grado di superare sfide come diversi spazi d’azione, modalità sensoriali e strutture di ricompensa.
I principali contributi della squadra sono:
A1 Quadraped – I ricercatori hanno addestrato il robot direttamente nell’impostazione di apprendimento per rinforzo end-to-end senza simulatori. Hanno addestrato da zero il robot Unitree A1, composto da 12 motori a trasmissione diretta. Entro 10 minuti, il robot potrebbe adattarsi e imparare a resistere a stimoli esterni come spingere e tirare.
UR5 Multi-Object visual pick and place – I bracci robotici sono addestrati per raccogliere e posizionare le palline. Il processo consiste nel localizzare la palla dalle immagini della telecamera in terza persona, afferrarla e spostarla nel cestino designato. Dreamer è stato in grado di raggiungere una velocità di raccolta media di 2,5 oggetti al minuto in 8 ore.
XArm visual pick and place – Per XArm, il team ha utilizzato una telecamera RealSense in terza persona con modalità RGB e di profondità, nonché input propriocettivi per il braccio robotico, richiedendo al modello mondiale di apprendere la fusione del sensore insieme a input propriocettivi per il braccio robotico , che ha bisogno del modello mondiale per imparare la fusione dei sensori. Qui viene utilizzato un oggetto morbido al posto della palla, che è una sfida da simulare. XArm riesce a completare l’attività in 10 ore.
Navigazione Sphero – Questa attività consisteva nel robot chiamato Sphero Ollie che navigava verso una posizione designata attraverso azioni continue, con l’unico input sensoriale che erano immagini RGB dall’alto verso il basso. Il robot identifica la sua posizione dai pixel e deduce il suo orientamento con l’aiuto di una sequenza di immagini passate e controlla il robot da motori sotto-azionati che accumulano slancio nel tempo. Lo Spero ollie apprende questo compito in meno di 2 ore.
DayDreamer contro Cheetah del MIT
Prima dei creatori di DayDreamer, un altro gruppo del MIT Improbable AI Lab ha lavorato a un progetto simile. Questo team ha sviluppato mini-Cheetah, l’allora robot quadruplo più veloce.
Il controller di Cheetah si basa su un’architettura di rete neurale che utilizza l’apprendimento per rinforzo per allenarsi in una simulazione che viene successivamente trasferita nel mondo reale. Le prestazioni del ghepardo sono misurate rispetto a due parametri di riferimento: (i) un curriculum adattivo sui comandi di velocità e (ii) una strategia di identificazione del sistema online per il trasferimento da simulazione a reale sfruttata dal lavoro precedente.
Questo modello potrebbe accumulare 100 giorni di esperienza su diversi terreni in tre ore di tempo effettivo. Sebbene questo sia tre volte il tempo di formazione richiesto per il modello Dreamer, è un’impresa sostanziale nel campo dell’apprendimento per rinforzo.
Il futuro della robotica basata sull’intelligenza artificiale
Secondo i ricercatori, l’approccio del modello Dreamer può risolvere le attività di locomozione, manipolazione e navigazione dei robot senza modificare gli iperparametri. Dreamer ha insegnato a un robot quadrupede a rotolare dalla schiena, alzarsi e camminare per 1 ora da zero, cosa che in precedenza richiedeva un addestramento approfondito sulla simulazione seguito dal trasferimento nel mondo reale o generatori di traiettoria parametrizzati e fornite politiche di ripristino.
Sebbene Dreamer mostri risultati promettenti, l’apprendimento sull’hardware per molte ore crea usura sui robot che potrebbero richiedere l’intervento o la riparazione dell’uomo. Inoltre, è necessario più lavoro per esplorare i limiti di Dreamer e quelli delle linee di base allenandosi per un tempo più lungo.