
Gli umani scelgono, l’IA no
” L’intelligenza artificiale sarà la migliore per gli esseri umani entro il 2060, dicono gli esperti “. Bene.
In primo luogo, come ha detto Yogi Berra, “È difficile fare previsioni, in particolare sul futuro”. Dov’è la mia macchina volante?
In secondo luogo, il titolo si legge come clickbait, ma sorprendentemente sembra essere abbastanza vicino al sondaggio reale , che ha chiesto ai ricercatori dell’IA quando arriverà “l’intelligenza artificiale di alto livello”, definita come “quando le macchine senza aiuto possono svolgere ogni compito meglio e in modo più economico rispetto ai lavoratori umani. ” Qual è un ‘compito’ in questa definizione? “Ogni compito” ha persino senso? Possiamo enumerare tutte le attività?
Terzo e più importante, l’intelligenza di alto livello sta solo compiendo compiti? Questa è la vera differenza tra intelligenza artificiale e quella umana: gli umani definiscono gli obiettivi, l’IA cerca di raggiungerli. Il martello sta per spostare il carpentiere? Ognuno di essi ha uno scopo.
Questa differenza tra intelligenza artificiale e umana è cruciale da comprendere, sia per interpretare tutti i titoli folli della stampa popolare, sia, soprattutto, per esprimere giudizi pratici e informati sulla tecnologia.
Il resto di questo post esamina alcuni tipi di intelligenza artificiale, tipi di intelligenza umana, e data la loro diversa, plausibile e non plausibile rischio di intelligenza artificiale. La storia breve: a differenza degli umani, ogni tecnologia AI ha un obiettivo perfettamente matematicamente ben definito, spesso un set di dati etichettato.
Tipi di intelligenza artificiale
Nell’apprendimento supervisionato , si definisce un obiettivo di previsione e si raccoglie un set di allenamento con etichette corrispondenti all’obiettivo. Supponiamo che tu voglia identificare se un’immagine contiene Denzel Washington. Quindi il tuo set di allenamento è un set di immagini, ciascuna etichettata come contenente Denzel Washington o meno. L’etichetta deve essere applicata al di fuori del sistema, probabilmente dalle persone. Se il tuo obiettivo è fare il riconoscimento facciale, il tuo set di dati etichettato è rappresentato da immagini insieme a un’etichetta (la persona nella foto). Ancora una volta, devi raccogliere le etichette in qualche modo, probabilmente con le persone. Se il tuo obiettivo è abbinare una faccia a un’altra faccia, hai bisogno di un’etichetta che indichi se la partita ha avuto successo o meno. Etichette sempre.
Quasi tutto l’apprendimento automatico di cui leggi è l’apprendimento supervisionato. Apprendimento profondo, reti neurali, alberi decisionali, foreste casuali, regressione logistica, tutta la formazione su set di dati etichettati.
Nell’apprendimento senza supervisione , di nuovo si definisce un obiettivo. Una tecnica di apprendimento senza supervisione molto comune è il clustering (ad esempio, il noto clustering di k-significati ). Ancora una volta, l’obiettivo è ben definito: trovare i cluster minimizzando alcune funzioni matematiche di costo. Ad esempio, dove la distanza tra i punti all’interno dello stesso cluster è piccola e la distanza tra i punti non all’interno dello stesso cluster è grande. Tutti questi obiettivi sono così ben definiti che hanno un formalismo matematico:
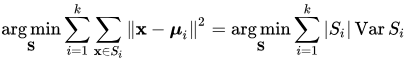
Questa formula sembra molto diversa da come gli umani specificano gli obiettivi. La maggior parte degli umani non capisce affatto questi simboli. Non sono formali. Inoltre, una mentalità “orientata agli obiettivi” in un essere umano è abbastanza insolita da avere un termine speciale.
Nell’apprendimento per rinforzo , si definisce una funzione di ricompensa per premiare (o penalizzare) le azioni che si muovono verso un obiettivo. Questa è la tecnologia che le persone hanno utilizzato di recente per giochi come gli scacchi e Go, in cui potrebbero essere necessarie molte azioni per raggiungere un determinato obiettivo (come scacco matto), quindi è necessaria una funzione di ricompensa che dia suggerimenti lungo il cammino. Ancora una volta, non solo un obiettivo ben definito, ma anche una funzione di ricompensa sulla strada verso l’obiettivo ben definita.
Questi sono tipi di intelligenza artificiale (“machine learning”) che sono attualmente caldi a causa dei recenti enormi guadagni di precisione, ma ce ne sono molti altri che le persone hanno studiato.
Gli algoritmi genetici sono un altro modo di risolvere i problemi ispirati alla biologia. Uno prende una popolazione di costrutti matematici (essenzialmente funzioni) e seleziona quelli che si comportano meglio su un problema. Sebbene le persone si emozionino per l’analogia biologica, la funzione di fitness che definisce il “migliore” è una funzione matematica concreta, completamente specificata, scelta da un essere umano.
C’è arte generata dal computer . Ad esempio, deep dream ( gallery ) è un modo per generare immagini da reti neurali di deep learning. Ciò sembrerebbe più umano e meno orientato agli obiettivi, ma in realtà le persone continuano a dirigere. Gli autori hanno descritto l’obiettivo ad alto livello: “Qualunque cosa tu veda lì, ne voglio di più!” A seconda dello strato della rete richiesto, le funzioni amplificate potrebbero essere di basso livello (come linee, forme, bordi, colori, vedere gli addax di seguito) o di livello superiore (come gli oggetti).
Foto originale di addax di Zachi Evenor, foto elaborata da Google
I sistemi esperti sono un modo per prendere decisioni usando le regole if-then su un corpus di conoscenze formalmente espresso. Erano in qualche modo popolari negli anni ’80. Questi sono un tipo di ” Good Old Fashioned Artificial Intelligence ” (GOFAI), un termine per AI basato sulla manipolazione di simboli.
Un’altra differenza comune tra l’intelligenza umana e quella artificiale è che gli umani imparano a lungo, mentre l’IA è spesso riqualificata dall’inizio per ogni problema. Questa differenza, tuttavia, viene ridotta. Il trasferimento dell’apprendimento è il processo di formazione di un modello e quindi l’utilizzo o l’ottimizzazione del modello per l’uso in un contesto diverso. Questa è una pratica industriale nella visione artificiale, in cui le reti neurali di apprendimento profondo sono state addestrate utilizzando le funzionalità delle reti precedenti ( esempio ).
Un interessante progetto di ricerca sull’apprendimento a lungo termine è NELL , l’apprendimento delle lingue senza fine. NELL esegue la scansione del Web raccogliendo testo e cercando di estrarre credenze (fatti) come ” airtran è un sistema di trasporto “, insieme a una sicurezza. Striscia dal 2010 e a luglio 2017 ha accumulato oltre 117 milioni di credenze candidate, di cui 3,8 milioni sono altamente fiduciosi (almeno 0,9 su 1,0).
In ogni caso sopra, gli umani non solo specificano un obiettivo, ma devono specificarlo in modo inequivocabile, spesso anche formalmente con la matematica.
Tipi di intelligenza umana
Quali sono i tipi di intelligenza umana? È difficile persino creare un elenco. Gli psicologi lo studiano da decenni. I filosofi hanno lottato con esso per millenni.
Il QI (il quoziente di intelligenza) viene misurato con test verbali e visivi, a volte astratti. Si basa sull’idea che esiste un’intelligenza generale (a volte chiamata ” fattore g “) comune a tutte le capacità cognitive. Questa idea non è accettata da tutti e il QI stesso è oggetto di accesi dibattiti. Ad esempio, alcuni credono che le persone con la stessa abilità latente ma appartenenti a diversi gruppi demografici possano essere misurate in modo diverso, denominate Differential Item Functioning o semplicemente bias di misurazione.
Le persone descrivono l’ intelligenza fluida (la capacità di risolvere nuovi problemi) e l’intelligenza cristallizzata (la capacità di usare conoscenza ed esperienza).
Il concetto di intelligenza emotiva appare nella stampa popolare: la capacità di una persona di riconoscere le proprie emozioni e quelle degli altri e usare il pensiero emotivo per guidare il comportamento. Non è chiaro quanto questo sia accettato dalla comunità accademica.
Più largamente accettati sono i tratti della personalità dei Cinque Grandi : apertura all’esperienza, coscienza, estroversione, gradevolezza e nevroticismo. Questa non è intelligenza (o è?), Ma mostra una forte differenza con l’intelligenza informatica. La “personalità” è un insieme di tratti o modelli comportamentali stabili che predicono il comportamento di una persona. Qual è la personalità di un’intelligenza artificiale? L’idea non sembra applicarsi.
Con umorismo, arte o ricerca di significato, ci allontaniamo sempre di più da problemi ben definiti, sempre più vicini all’umanità.
Rischi di intelligenza artificiale
L’intelligenza artificiale può superare l’intelligenza umana?
Un rischio che cattura la stampa popolare è The Singularity . Lo scrittore e matematico Verner Vinge fornisce una descrizione avvincente in un saggio del 1993: “ Entro trent’anni avremo i mezzi tecnologici per creare un’intelligenza sovrumana. Poco dopo, l’era umana sarà finita. “
Esistono almeno due modi per interpretare questo rischio. Il modo comune è che una massa critica magica provocherà un cambiamento di fase nell’intelligenza artificiale. Non ho mai capito questo argomento. “Altro” non significa “diverso”. L’argomento è qualcosa come “Mentre imitiamo da vicino il cervello umano, accadrà qualcosa di quasi umano (o superumano)”. Forse?
Sì, la disponibilità di molta potenza di calcolo e molti dati ha comportato un cambiamento di fase nei risultati dell’IA . Il riconoscimento vocale, la traduzione automatica, la visione artificiale e altri domini problematici sono stati completamente trasformati. Nel 2012, quando i ricercatori di Toronto hanno riapplicato le reti neurali alla visione artificiale, i tassi di errore su un noto set di dati hanno iniziato a calare rapidamente, fino a quando nel giro di pochi anni i computer hanno battuto gli umani. Ma i computer stavano facendo lo stesso compito ben definito di prima, solo meglio.
Tassi di errore della sfida del riconoscimento visivo su larga scala di ImageNet . 0,1 è un tasso di errore del 10%. Dopo che le reti neurali sono state riapplicate nel 2012, i tassi di errore sono diminuiti rapidamente. Hanno battuto Andrej Karpathy entro il 2015.
L’osservazione più avvincente è: “La possibilità di una singolarità potrebbe essere piccola, ma le conseguenze sono così gravi che dovremmo pensare attentamente.”
Un altro modo di interpretare il rischio della singolarità è che l’intero sistema avrà un cambiamento di fase. Tale sistema include computer, tecnologia, reti e persone che fissano obiettivi. Questo sembra più corretto e del tutto plausibile. Internet è stato un cambiamento di fase, così come i telefoni cellulari. Sotto questa interpretazione, ci sono molti rischi plausibili di AI.
Un rischio plausibile è la distorsione algoritmica . Se gli algoritmi sono coinvolti in decisioni importanti, vorremmo che fossero affidabili. (In un post precedente , abbiamo discusso su come misurare l’equità algoritmica.)
Tay, un chatbot Microsoft, è stato insegnato da Twitter a essere razzista e odiare le donne entro 24 ore. Ma Tay non ha davvero capito nulla, ha semplicemente “imparato” e imitato.
Il software di riconoscimento facciale di Amazon Rekognition, ha erroneamente abbinato 28 membri del Congresso degli Stati Uniti (principalmente persone di colore) con noti criminali. La risposta di Amazon è stata che l’ACLU (che ha condotto il test) ha utilizzato un taglio inaffidabile con solo l’80% di confidenza. (Hanno raccomandato il 95 percento.)
La ricercatrice del MIT Joy Buolamwini ha mostrato che i tassi di errore nell’identificazione di genere in diversi sistemi di visione computerizzata erano molto più alti per le persone con pelle scura.
Tutti questi risultati inaffidabili derivano almeno in parte dai dati di addestramento. Nel caso di Tay, gli utenti di Twitter hanno deliberatamente alimentato dati odiosi. Nei sistemi di visione artificiale, potrebbero esserci stati meno dati per le persone di colore.
Un altro rischio plausibile è l’ automazione . Man mano che l’intelligenza artificiale diventa più efficiente in termini di costi nel risolvere problemi come guidare auto o diserbare terreni agricoli, le persone che erano solite svolgere tali compiti potrebbero essere escluse dal lavoro. Questo è il rischio di intelligenza artificiale più capitalismo: le imprese cercheranno ciascuna di essere redditizie. Possiamo affrontarlo solo a livello sociale, il che rende molto difficile.
Un rischio finale sono i cattivi obiettivi , eventualmente aggravati dalla concentrazione. Questo è memorabilmente illustrato dal problema delle graffette, descritto per la prima volta da Nick Bostrom nel 2003: “Sembra anche perfettamente possibile avere una superintelligenza il cui unico obiettivo è qualcosa di completamente arbitrario, tale da produrre il maggior numero possibile di graffette e chi vorrebbe resistere con tutte le sue forze a qualsiasi tentativo di modificare questo obiettivo. Nel bene e nel male, gli intellettuali artificiali non hanno bisogno di condividere le nostre tendenze motivazionali umane. ” Esiste persino un gioco web ispirato a questa idea.
Comprendi i tuoi obiettivi
Come affrontiamo alcuni dei rischi plausibili sopra? Una risposta completa è un altro post completo (o libro o vita). Ma citiamo un pezzo: capire gli obiettivi che hai dato alla tua IA . Poiché tutta l’IA sta semplicemente ottimizzando una funzione matematica ben definita, questo è il linguaggio che usi per dire quale problema vuoi risolvere.
Significa che dovresti iniziare a leggere integrali e algoritmi di discesa gradiente? Sento che i tuoi occhi si chiudono. Non necessariamente!
Gli obiettivi sono una negoziazione tra ciò di cui la tua azienda ha bisogno (linguaggio umano) e come può essere misurata e ottimizzata (linguaggio AI). Hai bisogno di persone che parlino da entrambe le parti. Spesso si tratta di un’azienda o di un proprietario di un prodotto in collaborazione con uno scienziato di dati o un ricercatore quantitativo.
Lasciami fare un esempio. Supponiamo di voler raccomandare il contenuto usando un modello. Scegli di ottimizzare il modello per aumentare il coinvolgimento con il contenuto, misurato dai clic. Voila, ora capisci una delle ragioni per cui Internet è pieno di clickbait: l’obiettivo è sbagliato. In realtà ti preoccupi di più dei clic. Le aziende modificano l’obiettivo senza toccare l’IA, cercando di filtrare i contenuti che non soddisfano le politiche. Questa è una strategia ragionevole. Un’altra strategia potrebbe essere quella di aggiungere una pesante penalità al set di dati di addestramento se l’IA raccomanda che in seguito i contenuti risultino contrari alla politica. Ora stiamo iniziando a riflettere davvero su come il nostro obiettivo influisce sull’intelligenza artificiale.
Questo esempio spiega anche perché i sistemi di contenuti possono essere così nervosi: fai clic su un video su YouTube, su un pin su Pinterest o su un libro su Amazon, e il sistema consiglia immediatamente una grande pila di cose che sono quasi esattamente le stesse. Perché? Il clic viene generalmente misurato a breve termine, quindi il sistema ottimizza per un impegno a breve termine. Questa è una sfida di raccomandazione ben nota, incentrata sulla definizione matematica di un buon obiettivo. Forse una parte dell’obiettivo dovrebbe essere se la raccomandazione è irritante o se esiste un impegno a lungo termine.
Un altro esempio: se il tuo modello è accurato, ma il tuo set di dati o le tue misurazioni non considerano le minoranze sottorappresentate nella tua attività, potresti avere prestazioni scarse per loro. Il tuo obiettivo potrebbe essere davvero preciso per tutti i tipi di persone diverse.
Un terzo esempio: se il tuo modello è preciso, ma non capisci perché, ciò potrebbe costituire un rischio per alcune applicazioni critiche, come l’assistenza sanitaria o la finanza. Se devi capire perché, potresti dover usare un modello comprensibile all’uomo (“scatola bianca”) o una tecnologia di spiegazione per il modello che hai. La comprensione può essere un obiettivo.
Conclusione: dobbiamo capire l’IA
L’intelligenza artificiale non può sostituire completamente gli umani , nonostante ciò che leggi sulla stampa popolare. La più grande differenza tra intelligenza umana e artificiale è che solo gli umani scelgono obiettivi . Finora, gli AI non lo fanno.
Se riesci a toglierti una cosa dell’intelligenza artificiale: comprendi i suoi obiettivi . Qualsiasi tecnologia AI ha un obiettivo perfettamente ben definito, spesso un set di dati etichettato. Nella misura in cui la definizione (o il set di dati) è difettosa, lo saranno anche i risultati.
