Microsoft ha annunciato oggi il rilascio di SynapseML (precedentemente MMLSpark), una libreria open source progettata per semplificare la creazione di pipeline di machine learning. Con SynapseML, gli sviluppatori possono creare sistemi “scalabili e intelligenti” per risolvere le sfide in tutti i domini, tra cui analisi del testo, traduzione ed elaborazione vocale, afferma Microsoft.
“Negli ultimi cinque anni, abbiamo lavorato per migliorare e stabilizzare la libreria SynapseML per i carichi di lavoro di produzione. Gli sviluppatori che utilizzano Azure Synapse Analytics saranno lieti di apprendere che SynapseML è ora generalmente disponibile su questo servizio con supporto aziendale [su Azure Synapse Analytics]”, ha scritto l’ingegnere del software Microsoft Mark Hamilton in un post sul blog.
La creazione di pipeline di machine learning può essere difficile anche per lo sviluppatore più esperto. Per cominciare, la composizione di strumenti da diversi ecosistemi richiede un codice considerevole e molti framework non sono progettati pensando ai cluster di server.
Nonostante ciò, c’è una crescente pressione sui team di data science per utilizzare più modelli di machine learning. Sebbene l’adozione e l’analisi dell’IA continuino a crescere , si stima che l’ 87% dei progetti di data science non arrivi mai in produzione. Secondo il recente sondaggio di Algorithmia , il 22% delle aziende impiega da uno a tre mesi per implementare un modello in modo che possa fornire valore aziendale, mentre il 18% impiega più di tre mesi.
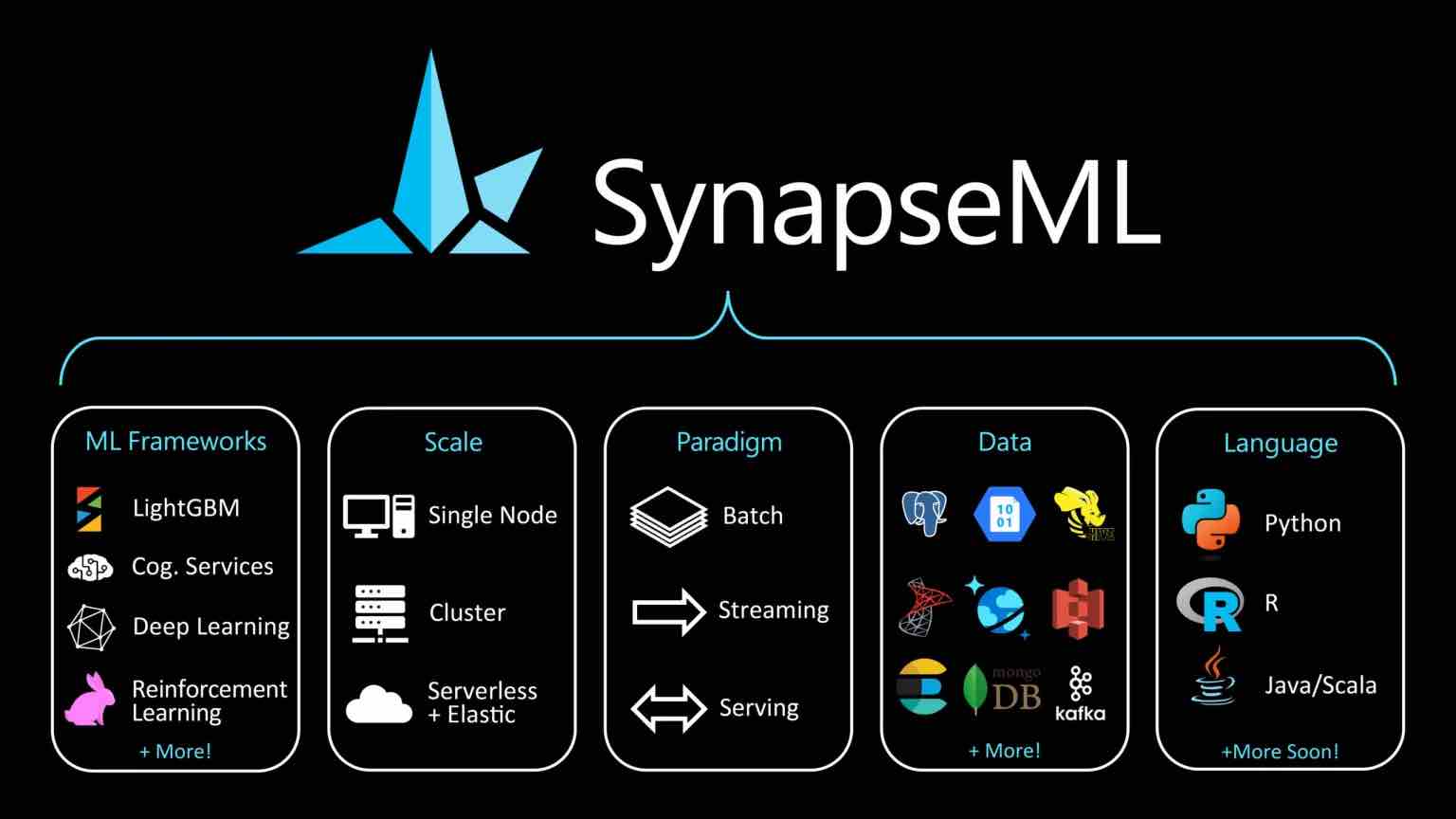
SynapseML mira ad affrontare la sfida unificando i framework di machine learning esistenti e gli algoritmi sviluppati da Microsoft in un’API, utilizzabile su Python, R, Scala e Java. SynapseML consente agli sviluppatori di combinare framework per casi d’uso che richiedono più di un framework, come la creazione di motori di ricerca, durante l’addestramento e la valutazione di modelli su cluster ridimensionabili di computer.
Come spiega Microsoft sul sito Web del progetto , SynapseML espande Apache Spark , il motore open source per l’elaborazione dei dati su larga scala, in diverse nuove direzioni. “[Gli strumenti in SynapseML] consentono agli utenti di creare modelli potenti e altamente scalabili che abbracciano più ecosistemi [di machine learning]. SynapseML offre anche nuove funzionalità di rete all’ecosistema Spark. Con il progetto HTTP su Spark, gli utenti possono incorporare qualsiasi servizio Web nei loro modelli SparkML e utilizzare i loro cluster Spark per flussi di lavoro di rete di grandi dimensioni.
SynapseML consente inoltre agli sviluppatori di utilizzare modelli di diversi ecosistemi di apprendimento automatico attraverso l’Open Neural Network Exchange (ONNX), un framework e runtime sviluppati congiuntamente da Microsoft e Facebook. Con l’integrazione, gli sviluppatori possono eseguire una varietà di modelli classici e di apprendimento automatico con solo poche righe di codice.
Oltre a ciò, SynapseML introduce nuovi algoritmi per la raccomandazione personalizzata e l’ apprendimento contestuale del bandito di rinforzo utilizzando il framework Vowpal Wabbit, una libreria di sistema di apprendimento automatico open source originariamente sviluppata presso Yahoo! Ricerca. Inoltre, l’API offre funzionalità per “IA responsabile senza supervisione”, inclusi strumenti per comprendere lo squilibrio del set di dati (ad esempio, se le caratteristiche del set di dati “sensibili” come razza o genere sono sovra o sottorappresentate) senza la necessità di dati di formazione etichettati e spiegabilità dashboard che spiegano perché i modelli fanno determinate previsioni e come migliorare i set di dati di addestramento.
Laddove non esistono set di dati etichettati, l’apprendimento non supervisionato, noto anche come apprendimento auto-supervisionato, può aiutare a colmare le lacune nella conoscenza del dominio. Ad esempio, SEER recentemente annunciato da Facebook , un modello non supervisionato, addestrato su un miliardo di immagini per ottenere risultati all’avanguardia su una serie di benchmark di visione artificiale. Sfortunatamente, l’apprendimento non supervisionato non elimina il potenziale di parzialità o difetti nelle previsioni del sistema. Alcuni esperti teorizzano che la rimozione di questi pregiudizi potrebbe richiedere un addestramento specializzato di modelli non supervisionati con set di dati aggiuntivi e più piccoli curati per “non insegnare” i pregiudizi.
“Il nostro obiettivo è liberare gli sviluppatori dal fastidio di preoccuparsi dei dettagli di implementazione distribuita e consentire loro di distribuirli in una varietà di database, cluster e linguaggi senza dover modificare il loro codice”, ha continuato Hamilton.