CHIRURGHI ROBOT CHE IMPARANO DAI VIDEO
L’apprendimento tramite imitazione è naturale per l’uomo. Nell’era di Internet, quasi tutte le abilità possono essere apprese guardando i video online. Tuttavia, insegnare alle macchine a imparare dall’imitazione è stato un obiettivo di vecchia data dei ricercatori delle macchine.
Per studiare la capacità di replicare questa capacità su macchine, Google, i laboratori Intel AI e l’Università della California, Berkeley ha collaborato per presentare Motion2Vec, un algoritmo che apprende rappresentazioni incentrate sul movimento delle abilità di manipolazione da dimostrazioni video per l’apprendimento delle imitazioni. La rappresentazione appresa è stata quindi applicata alla segmentazione della sutura chirurgica e pone l’imitazione in simulazione e reale sul robot da Vinci.
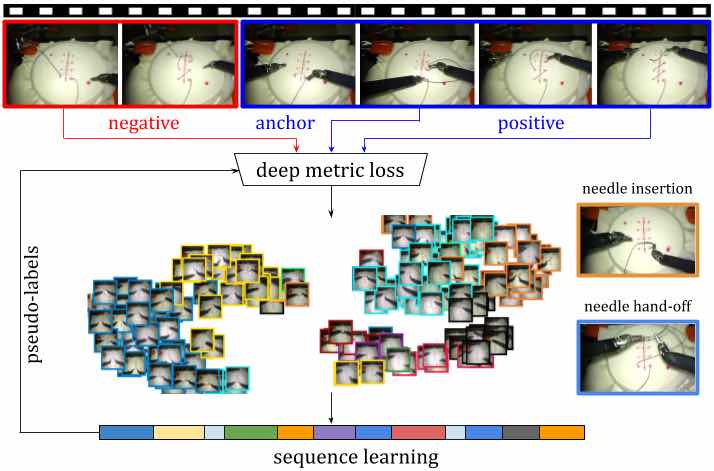
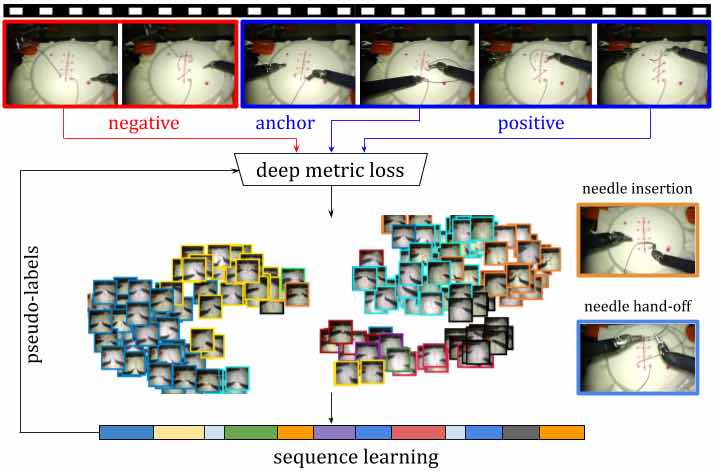
Panoramica di Motion2Vec
Per la dimostrazione del modello Motion2Vec, i ricercatori hanno scelto il robot Da Vinci per le attività chirurgiche. Ad esempio, un video di sutura può essere segmentato dal modello in base ai loro timestamp in segmenti di azione come l’inserimento dell’ago, l’estrazione dell’ago, il trasferimento dell’ago e così via. Questo tipo di decomposizione può essere visto nei modelli utilizzati per il riconoscimento vocale.
Il modello Motion2Vec accumula tutti i segmenti dai fotogrammi video in uno spazio di incorporamento in modo semi-supervisionato. Per ottenere pseudo-etichette per l’addestramento senza etichetta attraverso l’esecuzione di inferenze su RNN che viene addestrato iterativamente per una determinata parametrizzazione della rete siamese, che è stata utilizzata raccogliere segmenti di azione e immagini simili con le stesse etichette discrete in uno spazio di incorporamento.
L’obiettivo principale di questo lavoro è quello di estrarre rappresentazioni distrutte dalle dimostrazioni video in modo semi-supervisionato per la segmentazione e l’imitazione.
Lo spazio di incorporamento profondo riflette gli attributi rilevanti per l’attività degli oggetti nei video e come possono essere mappati sull’effettore finale del robot. La rete siamese, che viene utilizzata in tutti gli esperimenti, è pre-addestrata sul set di dati ImageNet e prende immagini RGB 320 × 240 a 3 canali ricampionate come input. Due strati convoluzionali di profondità 512 ciascuno vengono aggiunti sopra lo strato ‘Mixed-5d’ seguito da uno strato di softmax spaziale, uno strato completamente collegato di 2048 neuroni e uno strato incorporato di 32 dimensioni.
Per insegnare al modello a imparare per imitazione, gli autori hanno usato il set di dati JIGSAWS. Questo set di dati contiene dimostrazioni video di tre attività chirurgiche, ovvero sutura, passaggio degli aghi e legatura dei nodi. Poiché ogni chirurgo ha il proprio stile di sutura, i ricercatori hanno assicurato che il set di dati di sutura avesse stili diversi. Includevano i dati di 8 chirurghi e utilizzavano i loro livelli di abilità variabili per eseguire compiti 5 volte ciascuno sul braccio del robot.
Le dimostrazioni nel contesto sono una coppia di video con le informazioni dalle telecamere stereo insieme ai dati cinematici dell’effettore finale dei bracci del robot insieme alle etichette per ogni segmento di azione in ciascun fotogramma video tra un insieme distinto di 11 sub di sutura -tasks come annotato dagli esperti.
I ricercatori hanno anche curato i dettagli cambiando il punto di vista della telecamera, l’illuminazione e lo sfondo solo leggermente con tutte le dimostrazioni. Poiché lo stile di sutura, tuttavia, è significativamente diverso per ogni chirurgo, quindi i ricercatori hanno utilizzato un totale di 78 dimostrazioni dal set di dati di sutura. I video sono stati sottoposti a downsampling a 3 frame al secondo con una durata media di 3 minuti per video.
I risultati mostrano che nonostante i fotogrammi video non osservati nel set di test, il modello Motion2Vec è stato in grado di associare questi fotogrammi a segmenti complessi come l’inserimento e l’estrazione dell’ago pur essendo invariante con il livello di abilità dei chirurghi nelle osservazioni.
L’apprendimento tramite imitazione è un’area attiva di ricerca e finora abbiamo visto esperimenti come insegnare a un braccio robotico a dipingere o scegliere o posizionare oggetti. Con questo lavoro su Motion2Vec in particolare, i ricercatori ritengono che in futuro porterà a numerose altre opportunità di ricerca .