Resilienza> Precisione: perché la “resilienza del modello” dovrebbe essere la vera metrica per rendere operativi i modelli
Di Ingo Mierswa , fondatore, presidente e chief data scientist di RapidMiner .
La scienza dei dati ha compiuto notevoli progressi negli ultimi due anni e molte organizzazioni stanno utilizzando modelli di analisi avanzata o apprendimento automatico per ottenere informazioni più approfondite sui processi e, in alcuni casi, anche per prevedere i probabili risultati per il futuro. Per altre “scienze”, spesso non è chiaro se un progetto avrà successo o meno e ci sono state segnalazioni secondo cui ben l’87% dei progetti di scienza dei dati non è mai entrato in produzione. Sebbene non ci si possa aspettare un tasso di successo del 100%, ci sono alcuni modelli nei progetti di data science che portano a tassi di successo più elevati di quanto dovrebbe essere ritenuto accettabile sul campo. Questi modelli problematici sembrano esistere indipendentemente da qualsiasi settore o caso d’uso particolare, il che suggerisce che esiste un problema universale nella scienza dei dati che deve essere affrontato.
Misurare il successo dell’apprendimento automatico
I data scientist che creano modelli di machine learning (ML) si affidano a criteri matematici ben definiti per misurare le prestazioni di tali modelli. Quale di questi criteri viene applicato dipende principalmente dal tipo di modello. Supponiamo che un modello debba prevedere classi o categorie per nuove situazioni, ad esempio se un cliente sta per abbandonare o meno. In situazioni come queste, i data scientist utilizzerebbero misurazioni come l’accuratezza (la frequenza con cui il modello è corretto) o la precisione (la frequenza con cui i clienti agitano effettivamente se prevediamo l’abbandono).
I data scientist necessitano di criteri oggettivi come questo perché parte del loro lavoro consiste nell’ottimizzare quei criteri di valutazione per produrre il modello migliore. Infatti, oltre alla preparazione dei dati per essere pronti per la modellazione, la costruzione e la messa a punto di questi modelli è il luogo in cui i data scientist trascorrono la maggior parte del loro tempo .
Lo svantaggio di questo è che i data scientist in realtà non si concentrano molto sulla messa in produzione di quei modelli, il che è un problema per più di un motivo. Innanzitutto, i modelli che non producono risultati di successo non possono essere utilizzati per generare un impatto sul business per le organizzazioni che li implementano. In secondo luogo, poiché queste organizzazioni hanno speso tempo e denaro per sviluppare, addestrare e rendere operativi modelli che non hanno prodotto risultati con successo se confrontati con dati del “mondo reale”, è più probabile che non ritengano il ML e altri strumenti di data science inutili per la loro organizzazione e rifiutare di andare avanti con le future iniziative di data science.
La verità è che i data scientist semplicemente si divertono a modificare i modelli e dedicano molto tempo a questo. Ma senza impatto sul business, questo tempo non viene speso saggiamente, il che è particolarmente doloroso data la scarsità di risorse che i data scientist nel mondo di oggi sono.
Il premio Netflix e il fallimento della produzione
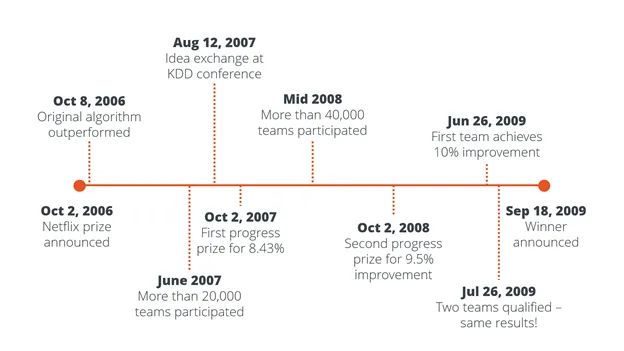
Negli ultimi anni abbiamo assistito a questo fenomeno di investimento eccessivo nella costruzione di modelli e non nell’operatività dei modelli. Il Premio Netflix era una competizione aperta per il miglior algoritmo di filtraggio collaborativo per prevedere le valutazioni degli utenti per i film. Se dovessi dare una valutazione alta a un nuovo film, probabilmente ti è piaciuto questo film, quindi utilizzando questo sistema di valutazione, Netflix ti consiglierà determinati titoli e se ti piacciono i contenuti consigliati, probabilmente rimarrai più a lungo come cliente di Netflix. Il primo premio era la somma di 1 milione di dollari, dato al team che è stato in grado di migliorare l’algoritmo di Netflix di almeno il 10%.
La sfida è iniziata nel 2006 e nei tre anni successivi, i contributi di oltre 40.000 team di data science a livello globale hanno portato a un notevole miglioramento di oltre il 10% per il successo della raccomandazione del titolo. Tuttavia, i modelli della squadra vincente non sono mai stati resi operativi . Netflix ha affermato che “l’aumento della precisione non sembra giustificare lo sforzo necessario per portare quei modelli in produzione”.
Perché ottimale non è sempre ottimale
L’accuratezza del modello e altri criteri della scienza dei dati sono stati a lungo utilizzati come metrica per misurare il successo di un modello prima di metterlo in produzione. Come abbiamo visto, molti modelli non arrivano nemmeno a questo stadio, il che è uno spreco di risorse, sia in termini di energia che di tempo speso.
Ma ci sono più problemi con questa cultura di investimenti eccessivi nel ritocco dei modelli. Il primo è un overfitting involontario dei dati di test, che si tradurrà in modelli che sembrano buoni per il data scientist responsabile, ma che in realtà hanno prestazioni inferiori una volta in produzione, a volte anche causando danni. Ciò accade per due motivi:
C’è una ben nota discrepanza tra l’errore di test e quello che vedrai in produzione
L’impatto sul business e i criteri di performance della data science sono spesso correlati, ma i modelli “ottimali” non sempre offrono l’impatto maggiore
Il primo punto sopra è anche chiamato ” adattamento eccessivo al set di prova “. È un fenomeno ben noto, soprattutto tra i partecipanti a concorsi di data science come quelli di Kaggle . Per queste competizioni, puoi vedere una versione più forte di questo fenomeno già tra le classifiche pubbliche e private. In effetti, un partecipante potrebbe vincere la classifica pubblica in una competizione Kaggle senza nemmeno leggere i dati . Allo stesso modo, il vincitore della classifica privata e della competizione complessiva potrebbero non aver prodotto un modello in grado di mantenere le sue prestazioni su un set di dati diverso da quello su cui è stato valutato.
La precisione non è uguale all’impatto sul business
Per troppo tempo abbiamo accettato questa pratica, che porta al lento adattamento dei modelli ai set di dati di test. Di conseguenza, quello che sembra il modello migliore risulta essere nel migliore dei casi mediocre:
Misurazioni come l’accuratezza predittiva spesso non equivalgono all’impatto aziendale
Un miglioramento della precisione dell’1% non può essere tradotto in un migliore risultato aziendale dell’1%
Ci sono casi in cui un modello a bassa performance supera gli altri, per quanto riguarda l’impatto sul business
Devono essere presi in considerazione anche altri fattori come la manutenzione, la velocità del punteggio o la robustezza rispetto ai cambiamenti nel tempo (chiamata “resilienza”).
Quest’ultimo punto è particolarmente importante. I modelli migliori non solo vinceranno le competizioni o avranno un bell’aspetto nel laboratorio di data science, ma manterranno la produzione e si comportano bene su una varietà di set di test. Questi modelli sono quelli che chiamiamo modelli resilienti.
Deriva e importanza della resilienza
Tutti i modelli si deteriorano nel tempo. L’unica domanda è quanto velocemente ciò avvenga e quanto bene il modello si comporta ancora nelle circostanze mutate. La ragione di questo deterioramento è il fatto che il mondo non è statico. Pertanto, anche i dati a cui si applica il modello cambiano nel tempo. Se questi cambiamenti avvengono lentamente, chiamiamo questa “deriva del concetto”. Se i cambiamenti avvengono all’improvviso, chiamiamo questo “cambiamento di concetto”. Ad esempio, i clienti possono cambiare il loro comportamento di consumo lentamente nel tempo, essendo stati influenzati dalle tendenze e / o dal marketing. I modelli di propensione potrebbero non funzionare più a un certo punto. Questi cambiamenti possono essere drasticamente accelerati in determinate situazioni. COVID-19, ad esempio,
Un modello resiliente potrebbe non essere il miglior modello basato su misure come l’accuratezza o la precisione, ma funzionerà bene su una gamma più ampia di set di dati. Per questo motivo, funzionerà anche meglio per un periodo di tempo più lungo ed è quindi in grado di fornire un impatto aziendale duraturo.
I modelli lineari e altri tipi di modelli semplici sono spesso più resistenti perché è più difficile adattarli a uno specifico set di test o momento nel tempo. Modelli più potenti possono e devono essere utilizzati come “sfidanti” per un modello più semplice, consentendo ai data scientist di vedere se può resistere anche nel tempo. Ma questo dovrebbe essere impiegato al punto finale, non all’inizio del viaggio di modellazione.
Sebbene un KPI formale per misurare la resilienza non sia stato ancora introdotto nel campo della scienza dei dati, ci sono diversi modi in cui i data scientist possono valutare quanto siano resilienti i loro modelli:
Deviazioni standard più piccole in una corsa di convalida incrociata significano che le prestazioni del modello dipendevano meno dalle specifiche dei diversi set di test
Anche se i data scientist non eseguono convalide incrociate complete, possono utilizzare due diversi set di dati per i test e la convalida. Una minore discrepanza tra i tassi di errore per i set di dati di test e di convalida indica una maggiore resilienza
Se il modello è adeguatamente monitorato in produzione, è possibile vedere i tassi di errore nel tempo. La coerenza dei tassi di errore nel tempo è un buon segno per la resilienza del modello.
Se la soluzione scelta per il monitoraggio del modello tiene conto della deriva, i data scientist dovrebbero anche prestare attenzione al modo in cui il modello è influenzato da tale deriva di input.
Cambiare la cultura della scienza dei dati
Dopo che un modello è stato distribuito nella fase di operazionalizzazione, ci sono ancora minacce alla precisione di un modello. Gli ultimi due punti sopra relativi alla resilienza del modello richiedono già un adeguato monitoraggio dei modelli in produzione. Come punto di partenza per un cambiamento di cultura nella scienza dei dati, le aziende sono ben consigliate di investire nel monitoraggio appropriato dei modelli e di iniziare a ritenere i data scientist responsabili della mancanza di prestazioni dopo che i modelli sono stati messi in produzione. Questo cambierà immediatamente la cultura da una cultura della costruzione di modelli a una cultura che crea e sostiene il valore per il campo della scienza dei dati.
Come ci hanno dimostrato i recenti eventi mondiali, il mondo cambia rapidamente. Ora più che mai, abbiamo bisogno di costruire modelli resilienti, non solo accurati, per catturare un impatto aziendale significativo nel tempo. Kaggle, ad esempio, sta ospitando una sfida per galvanizzare i data scientist di tutto il mondo per aiutare a costruire soluzioni modello da utilizzare nella lotta globale contro COVID-19. Prevedo che i modelli di maggior successo prodotti come risultato di questa sfida saranno i più resilienti, non i più accurati, poiché abbiamo visto con quanta rapidità i dati COVID-19 possono cambiare in un solo giorno.
La scienza dei dati dovrebbe riguardare la ricerca della verità, non la produzione del modello “migliore”. Mantenendoci uno standard più elevato di resilienza rispetto all’accuratezza, i data scientist saranno in grado di fornire un maggiore impatto aziendale per le nostre organizzazioni e contribuire a plasmare positivamente il futuro.