Questo nuovo metodo di apprendimento semi-supervisionato sta guadagnando terreno
Le reti neurali profonde sono il modello più utilizzato per le applicazioni di visione artificiale, in gran parte a causa della loro scalabilità. Le reti neurali profonde generalmente derivano le loro prestazioni superiori attraverso meccanismi di apprendimento supervisionato sottostanti.
L’apprendimento supervisionato è un tipo di metodi di apprendimento profondo che utilizza set di dati etichettati. Sebbene l’apprendimento supervisionato offra vantaggi in termini di prestazioni superiori, ha un costo elevato, poiché l’etichettatura dei dati richiede lavoro umano. Inoltre, il costo è significativamente più alto quando l’etichettatura dei dati deve essere eseguita da un esperto, come un medico.
In tale scenario, l’apprendimento semi-supervisionato ( SSL ) si rivela una potente alternativa. SSL è un metodo in cui l’apprendimento avviene con un piccolo numero di dati etichettati e un insieme relativamente più ampio di dati non etichettati. Questo metodo riduce la necessità di etichettare tutti i dati come nel caso dell’apprendimento supervisionato.
Recentemente, un documento accettato dalla conferenza NeurIPS 2020, parla dell’utilizzo di un metodo SSL chiamato FixMatch per ottenere prestazioni allo stato dell’arte su vari benchmark SSL come CIFAR-10 anche con pochissimi dati etichettati.
Cos’è l’algoritmo FixMatch?
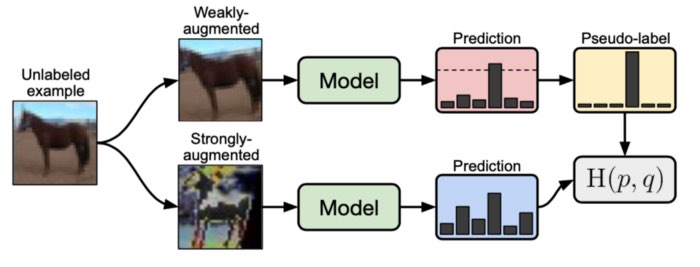
FixMatch Algorithm è essenzialmente un metodo SSL che combina diversi meccanismi per produrre etichette artificiali per dati privi di etichetta. In particolare, questo algoritmo utilizza la regolarizzazione della consistenza e la pseudoetichettatura per questo scopo, nonché un insieme separato di aumento debole e forte.
Innanzitutto, nel processo FixMatch, il valore previsto di un’immagine senza etichetta con un aumento debole viene calcolato dall’algoritmo FixMatch. Introdurre un debole aumento dell’immagine significa cambiare leggermente con metodi come la rotazione e il capovolgimento. Solo l’immagine con una probabilità di previsione superiore a una certa soglia viene trattata come pseudo etichette. Successivamente, lo stesso modello viene utilizzato per generare i valori previsti per la generazione dell’immagine con un forte aumento, in cui vengono applicati cambiamenti più grandi come la modifica della temperatura dell’immagine.
Viene quindi calcolata un’etichetta artificiale sull’immagine aumentata debole e la perdita calcolata viene applicata all’output del modello per l’immagine fortemente aumentata. Questo introduce una forma di coerenza. Questa consistenza viene quindi regolarizzata.
La regolarizzazione della coerenza è un metodo in cui i dati aumentati deboli e forti vengono utilizzati separatamente e l’obiettivo finale è costringere il modello SSL a imparare a produrre lo stesso output per diverse “versioni” di un’immagine. Aumenta la precisione dell’etichetta temporanea limitando il valore previsto. Quindi, anche se i dati vengono convertiti, il valore previsto non viene modificato. Inoltre, l’affidabilità di questo valore previsto è assicurata incorporando la differenza tra i valori previsti di entrambe le immagini aumentate nella funzione obiettivo.
Le prestazioni di FixMatch contro le sue controparti
Il documento (a cui si fa riferimento sopra) ha mostrato che FixMatch ha ottenuto buoni risultati rispetto ai benchmark standard come CIFAR-10 e CIFAR-100. Ad esempio, su CIFAR-10 con quattro etichette per classe, FixMatch ha ottenuto una precisione del 99,43% su CIFAR-10 con 250 etichette e un’accuratezza dell’88,61% con 40 campioni, con quattro etichette per classe.
Come proteggere i modelli di deep learning dagli attacchi del contraddittorio
Le prestazioni di FixMatch nella maggior parte dei casi sono risultate migliori rispetto alle sue controparti come Π Model, Mean Teacher, Pseudo-Label, MixMatch, UDA. Solo ReMixMatch è riuscito a superare FixMatch in termini di prestazioni sul benchmark CIFAR-100.
Guardando avanti
In ritardo, ci sono stati rapidi progressi in SSL. A differenza di altri complicati algoritmi di apprendimento, FixMatch è molto più semplice e raggiunge risultati all’avanguardia su diversi set di dati e su diversi benchmark standard.
Questo algoritmo può anche ottenere un’elevata precisione con una sola etichetta per classe. Inoltre, utilizzando le perdite di entropia incrociata standard sui dati etichettati e non etichettati, l’oggetto di addestramento di FixMatch può essere scritto in poche righe di codice.
Si ritiene che un algoritmo SSL così semplice ma ad alte prestazioni possa consentire l’implementazione conveniente dell’apprendimento automatico in diversi domini in cui ottenere un set completo di dati etichettati è costoso.