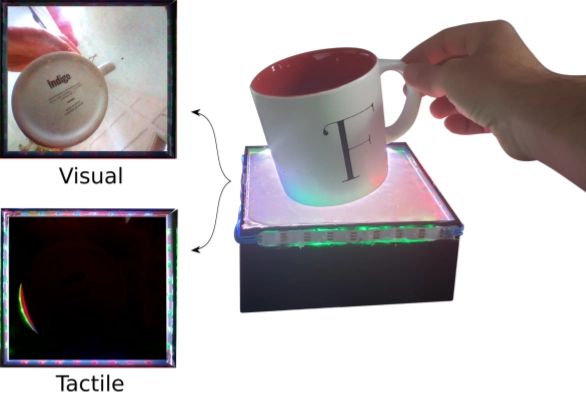
I ricercatori sviluppano un framework AI che prevede il movimento degli oggetti da immagini e dati tattili
Recenti ricerche sull’IA hanno evidenziato le sinergie tra tatto e visione. Uno consente la misurazione della superficie 3D e delle proprietà inerziali, mentre l’altro fornisce una visione olistica dell’aspetto proiettato degli oggetti. Basandosi su questo lavoro, i ricercatori della Samsung, della McGill University e della York University hanno studiato se un sistema di intelligenza artificiale potesse prevedere il movimento di un oggetto dalle misurazioni visive e tattili del suo stato iniziale.
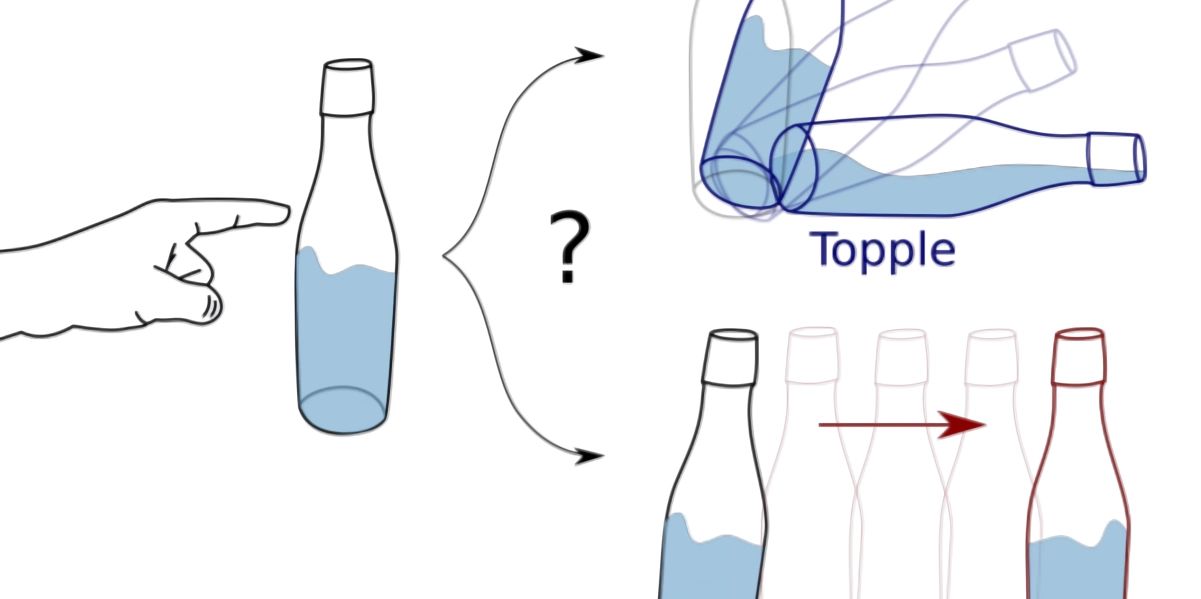
“Ricerche precedenti hanno dimostrato che è difficile prevedere la traiettoria degli oggetti in movimento, a causa delle proprietà geometriche e di attrito sconosciute e delle distribuzioni di pressione indeterminate sulla superficie interagente”, hanno scritto i ricercatori in un documento che descrive il loro lavoro. “Per alleviare queste difficoltà, ci concentriamo sull’apprendimento di un predittore addestrato per catturare gli elementi più informativi e stabili di una traiettoria di movimento”.
I ricercatori hanno sviluppato un sensore – See-Through-your-Skin – che, secondo loro, può acquisire immagini fornendo misurazioni tattili dettagliate. Oltre a questo, hanno creato un framework chiamato Generative Multimodal Perception che sfrutta i dati visivi e tattili quando disponibili per apprendere una rappresentazione che codifica le informazioni sulla posa, la forma e la forza dell’oggetto e fare previsioni sulla dinamica degli oggetti. E per anticipare lo stato di riposo di un oggetto durante le interazioni fisiche, hanno utilizzato ciò che chiamano previsioni dello stato di riposo insieme a un set di dati visuotactile dei movimenti in scene dinamiche, inclusi oggetti in caduta libera su una superficie piana, che scivolano su un piano inclinato e sono perturbati dal loro riposo. posa.
Negli esperimenti, i ricercatori affermano che il loro approccio è stato in grado di prevedere le misurazioni visive e tattili grezze della configurazione a riposo di un oggetto con elevata precisione, con le previsioni che corrispondono strettamente alle etichette di verità del terreno. Inoltre, affermano che il loro framework ha appreso una mappatura tra le modalità di posa visiva, tattile e 3D in modo tale da poter gestire le modalità mancanti come quando le informazioni tattili non erano disponibili nell’input, nonché prevedere i casi in cui un oggetto era caduto dalla superficie di sensore, risultando in immagini di output vuote.
“Se un oggetto precedentemente invisibile viene lasciato cadere nella mano di un essere umano, siamo in grado di inferire la categoria dell’oggetto e di indovinare alcune delle sue proprietà fisiche, ma l’inferenza più immediata è se si fermerà al sicuro nel nostro palmo o se noi abbiamo bisogno di regolare la nostra presa sull’oggetto per mantenere il contatto “, hanno scritto i coautori. “[Nel nostro lavoro] scopriamo che la previsione dei movimenti degli oggetti in scenari fisici trae vantaggio dallo sfruttamento di entrambe le modalità: le informazioni visive catturano le proprietà degli oggetti come la forma e la posizione 3D, mentre le informazioni tattili forniscono indicazioni critiche sulle forze di interazione e sul conseguente movimento degli oggetti e contatti. “