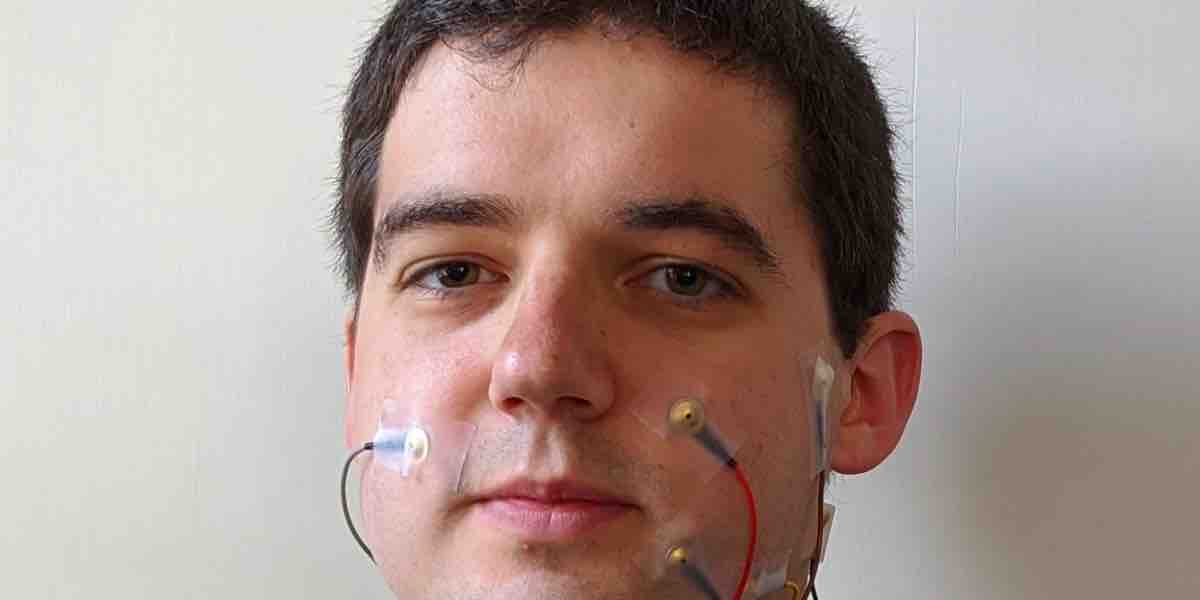
I ricercatori della UC Berkeley rilevano il “discorso silenzioso” con elettrodi e IA
Quando si tratta delle aspettative dei clienti, la pandemia ha cambiato tutto
Scopri come accelerare il servizio clienti, ottimizzare i costi e migliorare il self-service in un mondo incentrato sul digitale.
I ricercatori della UC Berkeley affermano di essere i primi ad addestrare l’intelligenza artificiale utilizzando parole e sensori dalla bocca silenziosa che raccolgono l’attività muscolare. Il linguaggio silenzioso viene rilevato utilizzando l’elettromiografia (EMG), con elettrodi posizionati sul viso e sulla gola. Il modello si concentra su ciò che i ricercatori chiamano voce digitale per prevedere le parole e generare un discorso sintetico.
I ricercatori ritengono che il loro metodo possa abilitare una serie di applicazioni per le persone che non sono in grado di produrre un discorso udibile e potrebbero supportare il rilevamento del parlato per assistenti AI o altri dispositivi che rispondono ai comandi vocali.
“La voce digitale del discorso silenzioso ha una vasta gamma di potenziali applicazioni”, si legge nel documento del team. “Ad esempio, potrebbe essere utilizzato per creare un dispositivo analogo a un auricolare Bluetooth che consente alle persone di continuare le conversazioni telefoniche senza disturbare le persone intorno a loro. Un tale dispositivo potrebbe anche essere utile in ambienti in cui l’ambiente è troppo rumoroso per catturare un discorso udibile o dove è importante mantenere il silenzio “.
Un altro esempio di intelligenza artificiale in grado di catturare le parole dal discorso silenzioso – l’ IA che legge le labbra – può alimentare gli strumenti di sorveglianza o supportare casi d’uso per le persone non udenti.
Per la loro previsione del discorso silenzioso, i ricercatori della UC Berkeley hanno utilizzato un approccio “in cui gli obiettivi di output audio vengono trasferiti dalle registrazioni vocalizzate alle registrazioni silenziose delle stesse espressioni”. Un decodificatore WaveNet viene quindi utilizzato per generare previsioni vocali audio.
Rispetto a una linea di base addestrata con dati EMG vocalizzati, l’approccio offre una riduzione dal 64% al 4% dei tassi di errore di parola nelle trascrizioni di frasi dai libri e una riduzione dell’errore del 95% dalla linea di base. Per alimentare ulteriore lavoro in quest’area, i ricercatori hanno reso open source un set di dati di quasi 20 ore di dati EMG facciali.
Un documento sul modello intitolato “Digital Voicing of Silent Speech” di David Gaddy e Dan Klein ha ricevuto il premio Best Paper all’evento Empirical Methods in Natural Language Processing (EMNLP) tenutosi online la scorsa settimana. La società Hugging Face ha ricevuto il premio Best Demo Paper dagli organizzatori per il suo lavoro sulla libreria Transformers open source . In altri lavori EMNLP, i membri del progetto open source Masakhane per la traduzione delle lingue africane hanno pubblicato un caso di studio sulla traduzione automatica a basse risorse e ricercatori cinesi hanno introdotto un modello di rilevamento del sarcasmo che ha ottenuto prestazioni all’avanguardia su un Twitter multimodale set di dati.