Questo modello AI genera “teste parlanti” per i video utilizzando una singola immagine 2D
In notizie recenti, un nuovo studio dei ricercatori di Nvidia introduce una tecnica basata sull’intelligenza artificiale per generare teste parlanti per videoconferenze combinando una singola immagine 2D e punti chiave 3D di apprendimento non supervisionato. Questa tecnica consente diverse manipolazioni come la rotazione della testa di una persona, il trasferimento del movimento e la ricostruzione video.
Produrre teste parlanti
Questo modello impara a utilizzare un’immagine sorgente che contiene l’aspetto della persona di destinazione insieme a un video di guida (molte volte ottenuto da un’altra persona) che determina il movimento nel video di output. Questi due input vengono quindi utilizzati per sintetizzare un video parlante della persona. Questo modello utilizza la rappresentazione canonica dei punti chiave in cui le informazioni specifiche dell’identità e relative al movimento vengono scomposte senza supervisione.
Poiché solo le rappresentazioni dei punti chiave vengono inviate per ricostruire il video sorgente all’estremità ricevente, oltre a superare le precedenti sperimentazioni simili nei test utilizzando set di dati di benchmark, questa AI raggiunge anche video di qualità H.264 ma utilizzando solo un decimo della larghezza di banda. Questo modello riduce ulteriormente il requisito di larghezza di banda utilizzando uno schema di codifica entropica.
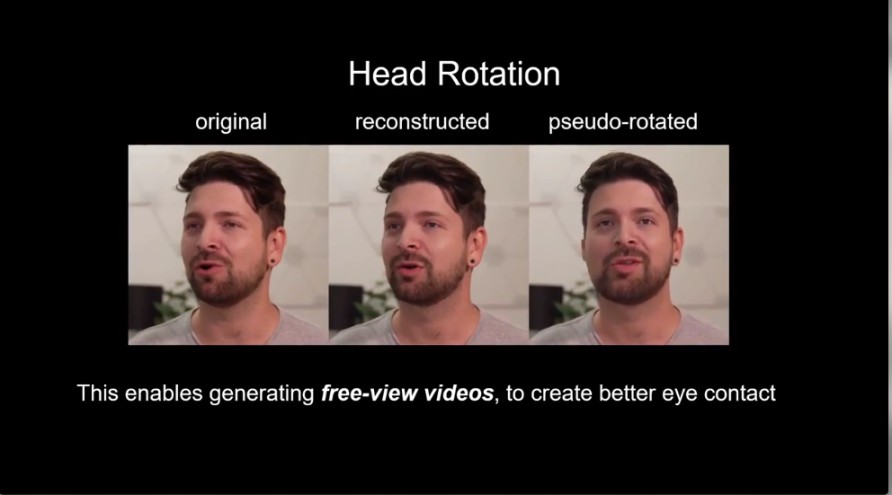
Considerando i limiti dei modelli precedenti, gli autori scrivono che anche i metodi con testa parlante one-shot basati su 2D esistenti sono dotati di una propria serie di limitazioni. Uno dei limiti chiave è l’assenza di modelli grafici 3D, che, a loro volta, possono solo sintetizzare la testa parlante dal punto di vista originale e non possono renderlo da una prospettiva nuova.
Il modello affronta questa limitazione di un punto di vista fisso ottenendo la sintesi locale libera della vista, che è un metodo per sintetizzare la visualizzazione completa utilizzando immagini distribuite liberamente nella scena.
Rispetto al metodo basato sulla grafica 3D, la cui acquisizione è difficile e costosa, i metodi 2D sono molto più economici.
I modelli 2D sono meglio attrezzati per gestire la sintesi di sottigliezze come capelli e barba, mentre l’acquisizione di geometrie 3D dettagliate di queste regioni è un compito impegnativo.
I metodi basati su 2D possono sintetizzare direttamente accessori come occhiali, cappelli e sciarpe, che possono essere presenti senza i loro modelli 3D.
Oltre a sintetizzare risultati più realistici, questa ricerca delinea molti altri vantaggi:
Modificando la trasformazione del punto chiave, il modello genera video a visualizzazione libera
Le trasformazioni dei punti chiave ottengono un rapporto di compressione migliore rispetto ai metodi esistenti
Riduce drasticamente i requisiti di larghezza di banda, il che potrebbe cambiare per sempre il futuro delle videoconferenze.
Il documento completo può essere trovato qui .
Tecniche simili da Nvidia
Ci sono stati alcuni tentativi in precedenza da parte di Nvidia di utilizzare l’IA per la generazione e la manipolazione di video. Due di loro, in particolare, sono: