La maggior parte dei leader IT ha sentito parlare di apprendimento profondo, ma pochi capiscono davvero come funzioni questa nuova tecnologia.
L’apprendimento profondo è esploso nella coscienza pubblica nel 2016 quando il software AlphaGo di Google, basato sull’apprendimento approfondito, ha battuto il campione del mondo umano nel gioco da tavolo Go. Da allora, l’apprendimento approfondito ha iniziato a comparire nelle notizie e nella letteratura sui prodotti con maggiore frequenza, ma poche organizzazioni lo stanno attualmente utilizzando.
Il rapporto dell’indagine O’Reilly del 2018 In che modo le aziende stanno mettendo in atto l’intelligenza artificiale attraverso l’apprendimento approfondito è emerso che solo il 28% degli oltre 3.300 intervistati utilizzava attualmente un apprendimento approfondito. Tuttavia, il 92% riteneva che l’apprendimento approfondito avrebbe avuto un ruolo nei loro progetti futuri, con il 54% che avrebbe svolto un ruolo importante o sostanziale in quelle iniziative.
Poiché le aziende pianificano di andare avanti con questi progetti, la sfida numero uno che li trattiene è la mancanza di persone qualificate. Il rapporto ha osservato: “I leader dell’IA hanno a lungo parlato della necessità di rendere l’apprendimento approfondito accessibile agli sviluppatori senza un dottorato di ricerca. Questo è essenziale per progredire; L’IA deve diventare accessibile agli esperti di dominio di altre discipline. ”
Il seguente slideshow non scalfisce nemmeno la superficie di ciò che serve per diventare un esperto di deep learning. Fornisce tuttavia una panoramica di alto livello dell’argomento e illustra le nozioni di base su cui i CIO, i responsabili IT e i leader aziendali devono comprendere questa tecnologia emergente.
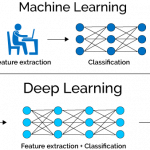
1. IL Deep Learning è un sottoinsieme dell’apprendimento automatico.
A volte le persone usano i termini intelligenza artificiale (AI), apprendimento automatico, apprendimento profondo e calcolo cognitivo come se volessero dire la stessa cosa. In realtà solo due di questi termini – AI e calcolo cognitivo – sono sinonimi.
L’intelligenza artificiale (e il calcolo cognitivo) è una categoria ampia che implica insegnare ai computer a pensare nel modo in cui la gente pensa.
L’apprendimento automatico è la sottocategoria di intelligenza artificiale che implica insegnare ai computer a migliorare in vari compiti senza essere programmati esplicitamente; essenzialmente, consente ai computer di migliorare le loro prestazioni senza che gli umani dicano loro cosa fare.
L’apprendimento approfonditoo deep learning è un tipo specializzato di apprendimento automatico che utilizza un approccio gerarchico. È un insieme di algoritmi, la matematica, che si è dimostrato particolarmente efficace nel risolvere alcuni tipi di problemi informatici difficili da definire con una programmazione esplicita.
2. L’apprendimento profondo è abbastanza nuovo.
Nel suo studio Deep Learning: A Critical Appraisal, il professore della New York University Gary Marcus ha spiegato: “Sebbene l’apprendimento profondo abbia radici storiche decennali, né il termine” apprendimento profondo “né l’approccio erano popolari solo cinque anni fa”. hanno lavorato su modi per far apprendere macchine dall’invenzione dei primi computer, l’approccio unico di deep learning è diventato popolare solo nel 2012, quando diversi ricercatori hanno pubblicato articoli sull’argomento.
Negli anni successivi, la tecnica è stata applicata a molti problemi diversi, e si è dimostrata straordinariamente abile nell’addestrare i computer a fare una varietà di cose che sono sempre state facili per l’uomo ma abbastanza difficili da insegnare alle macchine. Molti ricercatori dell’intelligenza artificiale ritengono che l’apprendimento approfondito continuerà ad essere molto influente nei prossimi anni, ma altri, incluso Marcus, ritengono che l’apprendimento approfondito sia di utilità limitata e dovrà essere integrato da molte altre tecniche man mano che la ricerca dell’IA progredisce.
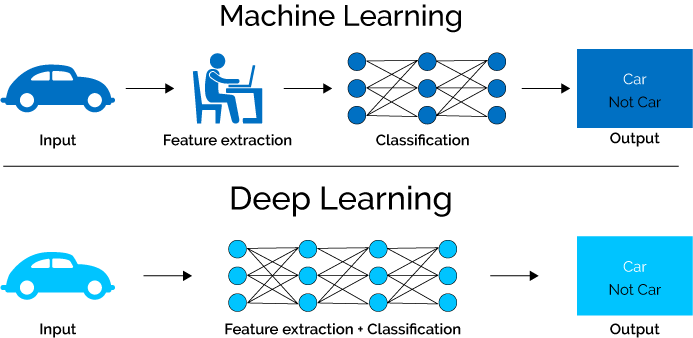 3. L’apprendimento profondo è “profondo” perché ha molti livelli.
3. L’apprendimento profondo è “profondo” perché ha molti livelli.
Il nome “deep learning” si riferisce al modo in cui funzionano questi algoritmi, che è quello di elaborare i dati attraverso molti livelli. Prendono un input, creano un output e quindi usano quell’output come input per il successivo livello di apprendimento. Inizia facendo astrazioni o generalizzazioni molto piccole per poi passare a generalizzazioni più ampie.
Ad esempio, immagina di voler utilizzare tecniche di deep learning per insegnare a un computer a riconoscere le immagini dei gatti domestici. Nelle fasi iniziali, il sistema potrebbe provare a classificare tutti gli animali come gatti. Quindi, dopo aver analizzato molte immagini, potrebbe iniziare a classificare tutte le creature piccole e indistinte come gatti. Con il passare del tempo – e con molti livelli diversi di apprendimento – il sistema potrebbe diventare alla fine altrettanto bravo delle persone nel riconoscere le immagini dei gatti.
4. L’apprendimento profondo rende possibile la visione artificiale e altre forme popolari di IA.
L’esempio della diapositiva precedente è particolarmente appropriato perché la visione artificiale è una delle applicazioni in cui l’apprendimento approfondito eccelle davvero. Infatti, quando il sondaggio O’Reilly chiedeva alle persone quali applicazioni di deep learning le interessassero maggiormente, la visione del computer era la risposta numero uno. Altri usi popolari per l’apprendimento approfondito includono l’elaborazione del parlato naturale, la riproduzione di giochi, la traduzione, i motori di raccomandazione, l’estrazione di testo, la previsione e l’analisi.
La cosa che questi casi d’uso hanno in comune è che è difficile per le persone scrivere regole logiche che diranno al computer cosa cercare. Nell’esempio dell’immagine del gatto, qualcuno potrebbe essere in grado di dire al sistema che i gatti hanno quattro zampe (di solito) o che hanno la pelliccia (di solito), ma quel tipo di logica non può dare al sistema tutte le informazioni di cui ha bisogno per fare il tipo di analisi intuitiva che le persone fanno sempre quando identificano i gatti. Lo stesso problema si verifica nell’elaborazione del linguaggio naturale. Insegnare al sistema le regole della grammatica non può che portarti così lontano perché ci sono così tante eccezioni a ogni regola.
L’apprendimento approfondito supera questi limiti facendo in modo che il computer capisca da solo quali funzioni nei dati di addestramento sono importanti per l’attività in corso, sia che si tratti di identificare immagini, interpretare l’audio o di capire quale film si potrebbe desiderare di guardare in seguito.
5. L’apprendimento approfondito può essere supervisionato o non supervisionato.
Nell’ambito del machine learning, le persone parlano spesso di apprendimento supervisionato e non supervisionato. Si è tentati di presumere che la supervisione significhi che le persone siano coinvolte, e senza sorveglianza significa che il computer impara da solo.
Ma non è proprio ciò che significa supervisione e senza supervisione. In qualsiasi attività di apprendimento automatico, dovrai addestrare il tuo modello fornendogli molti dati. Nell’esempio di analisi dell’immagine, è necessario fornire al proprio sistema una serie di immagini, incluse alcune immagini di gatti. Nell’apprendimento approfondito supervisionato, tutte le immagini sarebbero etichettate, sia come “gatto” e “non-gatto” o come “gatto”, “cane”, “albero”, “auto”, ecc. Nel corso del tempo, avrebbe imparato a dire ai gatti a parte le altre immagini.
Nell’apprendimento approfondito senza supervisione, mostreresti al computer molte immagini senza etichette. La macchina non sarebbe in grado di capire da sola l’etichetta “gatto”, ma sarebbe in grado di raggruppare tutte le immagini simili. Questo apprendimento non supervisionato può essere molto utile nei casi in cui tutti i dati di test non sono etichettati (come nell’esempio di immagine cat) o quando non si sa cosa si sta cercando (come in molte applicazioni di data mining).
6. L’apprendimento profondo di solito funziona su una rete neurale artificiale.
Un altro termine che compare frequentemente nelle discussioni sull’apprendimento profondo è “rete neurale artificiale” o ANN. Come suggerisce il nome, si tratta di sistemi informatici che sono approssimativamente modellati sul cervello umano. Il cervello ha molti neuroni interconnessi che trasmettono segnali tra loro, e le reti neurali artificiali hanno molti nodi interconnessi, chiamati anche neuroni, che trasmettono dati l’un l’altro. Nel caso dell’apprendimento profondo, questi nodi sono disposti a strati, con i neuroni che passano informazioni da uno strato all’altro.
Potresti anche sentire parlare di due tipi specializzati di reti neurali: reti neurali ricorrenti (RNN) e reti generative avversarie (GAN).
Gli RNN si basano sulla memoria per fornire contesto per l’input corrente che stanno elaborando. Quindi, ad esempio, se si insegnasse a un computer a leggere la scrittura a mano in corsivo, un RNN sarebbe migliore di altri tipi di reti neurali perché prenderebbe in considerazione le lettere precedenti per determinare quale etichetta dare a una lettera corrente.
Un GAN coinvolge due reti neurali diverse, in cui si presentano le potenziali risposte a una determinata domanda e l’altra valuta quelle soluzioni. Con il passare del tempo, entrambe le reti neurali nel GAN diventano più efficienti nel generare e valutare le risposte.
7. Apprendimento profondo richiede enormi quantità di risorse.
Parte del motivo per cui l’apprendimento approfondito è diventato popolare solo di recente è che richiede enormi quantità di potenza di calcolo. Fino agli ultimi anni, i sistemi abbastanza potenti da eseguire i calcoli simultanei multipli coinvolti non esistevano o erano proibitivi. Ora, tuttavia, i sistemi con unità di elaborazione grafica (GPU) estremamente avanzate, che sono molto utili per l’elaborazione di carichi di lavoro di apprendimento approfondito, sono molto più accessibili. Inoltre, i fornitori di cloud computing rendono questi sistemi disponibili su base pay-as-you-go, il che li mette alla portata di quasi tutte le organizzazioni.
L’apprendimento approfondito richiede anche enormi volumi di dati per la formazione e le riserve sempre crescenti di big data delle aziende sono perfette per questo scopo.
8. L’apprendimento approfondito è già migliore degli umani in alcuni compiti.
L’apprendimento approfondito ha già dimostrato di essere migliore degli umani giocando a Go, oltre che con altri videogiochi. Un sistema chiamato LipNet è migliore nella lettura delle labbra rispetto alla persona media, e l’apprendimento approfondito è anche migliore degli umani nel modificare la progettazione del sito web per migliorare i tassi di conversione dell’e-commerce.
Inoltre, molti sistemi di analisi sono molto migliori degli umani nel fare previsioni e trovare correlazioni in dati apparentemente disparati. Ad esempio, un gruppo di ricercatori ha addestrato un sistema di apprendimento approfondito su Google Street View e i dati degli elettori per stabilire che “se il numero di berline incontrate durante un viaggio di 15 minuti attraverso una città è superiore al numero di camioncini, la città è probabile voto per un democratico durante le prossime elezioni presidenziali (88% di possibilità); altrimenti, è probabile che voti repubblicano (82%). “Quel documento, pubblicato nel 2017, ha utilizzato i risultati delle elezioni del 2008.
Ciò non significa che i sistemi di deep learning siano comunque bravi in ogni cosa. Ad esempio, l’apprendimento approfondito non è molto adatto per trarre inferenze aperte o per distinguere la causalità dalla correlazione. Per almeno il futuro prevedibile, questi tipi di ragionamento richiedono l’intervento umano o altri tipi di intelligenza artificiale.
9. TensorFlow di Google è il framework di deep learning più popolare.
Quando il sondaggio O’Reilly chiedeva alla gente quali strumenti di deep learning stessero usando, il TensorFlow di Google era il chiaro favorito, utilizzato dal 61% degli intervistati. TensorFlow è anche popolare tra i fornitori di cloud computing e Amazon e Google offrono entrambi i servizi basati su TensorFlow. Il sondaggio ha inoltre rilevato che il 70% degli intervistati considera i servizi cloud importanti per le loro applicazioni di deep learning.
Il secondo framework di deep learning più popolare è Keras, che è stato utilizzato da meno della metà di molte persone (25%) rispetto a TensorFlow. Altre opzioni includono PyTorch (20%), Caffe (6%), MXNet (4%) e CNTK (3%).
10. Diverse organizzazioni offrono corsi di apprendimento approfondito.
Finora, solo l’11% degli intervistati nel sondaggio O’Reilly ha affermato che le loro organizzazioni avevano assunto persone appositamente per progetti di apprendimento approfondito. Parte del problema può essere che il numero di esperti di deep learning è molto più piccolo del numero di posti di lavoro disponibili.
Gli sviluppatori e gli altri professionisti IT interessati a saperne di più sull’apprendimento approfondito hanno molte opzioni di formazione disponibili. Molte università ora offrono corsi di apprendimento approfondito, sia online che in classe. Ci sono anche lezioni online disponibili attraverso siti web come Coursera (che è stato co-fondato da Andrew Ng, uno dei maggiori esperti di machine learning) e aziende che offrono formazione in prima persona.