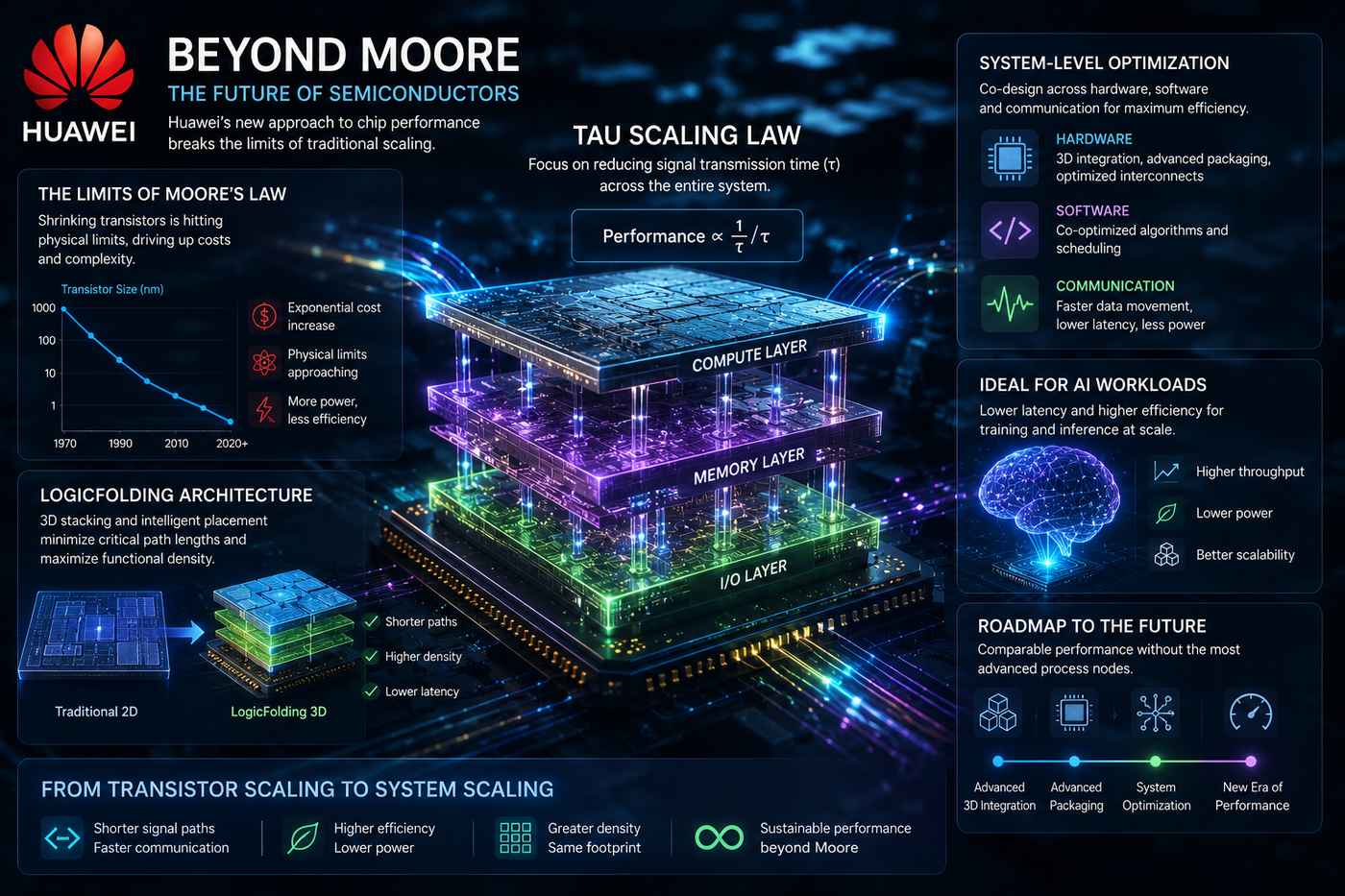
Per oltre mezzo secolo l’industria dei semiconduttori ha seguito la Legge di Moore, secondo la quale il numero di transistor presenti in un chip tende a raddoppiare periodicamente, aumentando le prestazioni e riducendo i costi di elaborazione. Oggi però questo modello si sta scontrando con limiti fisici sempre più difficili da superare. Ridurre ulteriormente le dimensioni dei transistor richiede investimenti enormi, tecnologie produttive estremamente avanzate e processi di fabbricazione che stanno raggiungendo le soglie della fisica atomica.
In questo scenario Huawei sta sviluppando un approccio alternativo che mira a migliorare le prestazioni dei chip senza dipendere esclusivamente dalla miniaturizzazione dei transistor. La strategia si basa su un nuovo modello teorico denominato Tau Scaling Law, progettato per ridurre i tempi necessari alla trasmissione dei segnali all’interno dei circuiti, dei chip e dei sistemi di calcolo complessi.
L’idea centrale consiste nel considerare il sistema nel suo insieme anziché focalizzarsi esclusivamente sul singolo transistor. Secondo questa visione, una parte significativa delle prestazioni moderne dipende infatti dalla velocità con cui dati e segnali si spostano tra differenti componenti hardware. Ridurre queste distanze e ottimizzare le comunicazioni interne può generare miglioramenti significativi anche senza ricorrere ai nodi produttivi più avanzati.
Per raggiungere questo obiettivo Huawei ha sviluppato una nuova architettura chiamata LogicFolding. Il concetto prevede una disposizione tridimensionale delle logiche di elaborazione, con percorsi più brevi per le connessioni critiche e una maggiore densità funzionale all’interno dello stesso volume fisico. In pratica, invece di espandere i circuiti su un piano bidimensionale tradizionale, le diverse componenti vengono organizzate in strutture verticali che consentono di ridurre la lunghezza delle interconnessioni e migliorare l’efficienza complessiva.
L’architettura interviene non soltanto sul layout fisico dei circuiti ma anche sulla progettazione coordinata tra hardware, software e sistemi di comunicazione. Questo approccio permette di affrontare uno dei principali problemi delle moderne piattaforme di intelligenza artificiale, dove una parte crescente dei consumi energetici e delle latenze deriva dallo spostamento dei dati piuttosto che dall’elaborazione vera e propria.
La strategia assume particolare rilevanza nel settore dell’intelligenza artificiale, dove la richiesta di potenza computazionale continua ad aumentare. I modelli generativi e i sistemi di inferenza avanzati richiedono infrastrutture sempre più grandi, rendendo essenziale migliorare non soltanto la capacità di calcolo ma anche l’efficienza energetica e la velocità delle comunicazioni tra processori, acceleratori e memoria.
Secondo la roadmap presentata dall’azienda, le future generazioni di chip basate su questi principi potrebbero raggiungere livelli di densità e prestazioni comparabili a quelli ottenibili con processi produttivi molto più avanzati. L’obiettivo è ridurre la dipendenza dalla sola evoluzione litografica e spostare l’attenzione verso tecniche di integrazione tridimensionale, packaging avanzato e ottimizzazione dell’intero ecosistema hardware.
L’iniziativa rappresenta uno dei tentativi più ambiziosi degli ultimi anni di individuare un percorso alternativo alla tradizionale corsa ai nanometri. Se questo approccio dovesse dimostrare risultati concreti su larga scala, potrebbe contribuire a ridefinire le priorità dell’industria dei semiconduttori, dove il progresso non verrebbe più misurato soltanto dalla dimensione dei transistor ma dalla capacità di migliorare l’efficienza dell’intero sistema di elaborazione.