C’è una differenza sostanziale tra usare l’intelligenza artificiale per scrivere più contenuti e usarla per far funzionare l’infrastruttura tecnica che decide se quei contenuti verranno trovati. Un caso documentato su un sito reale, un progetto in Next.js 15 con CMS Sanity e deploy su Vercel, aiuta a vedere questa differenza in concreto, perché mette a confronto lo stato di partenza, gli interventi effettuati da un agente che opera direttamente sul codice e i numeri misurati a distanza di settimane. Il punto interessante non sono solo i risultati, ma il fatto che parte del lavoro non sia un audit una tantum, bensì un ciclo che ogni giorno osserva, individua problemi e tenta di correggerli.
Lo strumento al centro dell’esperimento è un agente che lavora da terminale sul codebase: legge i file, individua i problemi, scrive le modifiche e le porta su git. Per la SEO tecnica questo comprime un percorso che normalmente richiede settimane (l’audit, l’apertura del ticket, lo sviluppo, il rilascio) in un paio di giorni, a condizione che ci sia qualcuno con competenza tecnica a supervisionare l’output. Il presupposto di tutta l’operazione è proprio questo: l’automazione non sostituisce il giudizio, lo esegue più in fretta.
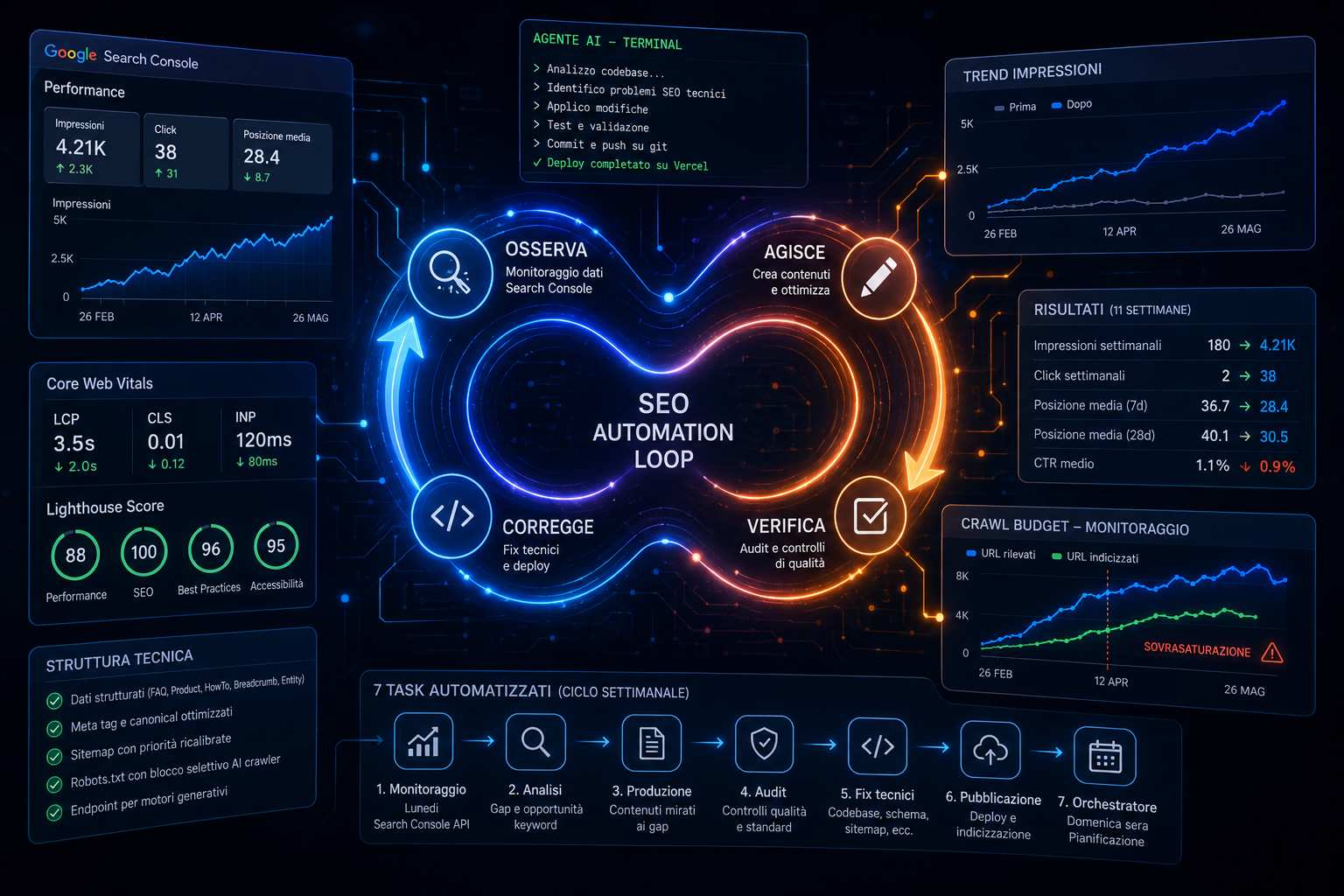
La fotografia iniziale del sito era poco incoraggiante. In tre mesi aveva accumulato poche centinaia di impressioni su Google Search Console e una manciata di click, con un solo articolo che da solo generava circa il settanta per cento del traffico. L’audit tecnico aveva fatto emergere un Largest Contentful Paint di 5,5 secondi su mobile, ben dentro la zona critica dei Core Web Vitals, alcune pagine chiave prive di intestazione principale, l’assenza completa di dati strutturati sui post del blog, oltre la metà degli articoli senza un’architettura di link interni e nessun collegamento esterno autorevole sui contenuti più importanti. Lo stack era solido; il problema stava nell’ottimizzazione del codice e dei contenuti.
La prima fase è consistita in una serie di interventi tecnici mirati. Sul fronte delle prestazioni, l’agente ha analizzato il componente principale della homepage e ha individuato le cause della lentezza: l’immagine più pesante caricata senza priorità, animazioni che gravavano sulla GPU, un percorso di rendering critico non ottimizzato. In poche iterazioni ha applicato priorità e preload sull’immagine determinante, rimosso gli effetti superflui, convertito le immagini in formato WebP e introdotto il caricamento differito per ciò che sta sotto la prima schermata. Il risultato si è stabilizzato attorno a un LCP di 3,5 secondi e a un punteggio di performance salito da 67 a 88, con uno spostamento cumulativo del layout praticamente azzerato e un punteggio SEO di Lighthouse a cento. Vale la pena notare un dettaglio onesto del racconto: una prima misurazione molto favorevole è stata poi parzialmente erosa da modifiche successive al codice e corretta in seguito, segno che in questi sistemi la regressione è una possibilità concreta e va monitorata.
Accanto alle prestazioni, l’agente ha costruito un meccanismo di generazione automatica dei dati strutturati, con builder distinti per le pagine di domande frequenti, i prodotti, i tutorial passo-passo, i breadcrumb e il grafo delle entità che descrive la persona, il servizio professionale e il sito. La logica è a configurazione zero: se un articolo contiene una sezione di domande frequenti con la struttura attesa, il relativo schema viene prodotto senza intervento manuale. Sempre in questa fase è stata recuperata l’architettura di interlinking sui post che ne erano privi, con due collegamenti contestuali per articolo (uno verso il contenuto pilastro del cluster e uno verso una pagina di conversione) un’operazione che a mano avrebbe richiesto diverse ore e che è stata completata in circa novanta minuti. Sono stati infine sistemati in blocco i meta tag per i robot, la sitemap con priorità ricalibrate, un robots.txt con blocco selettivo di una serie di crawler AI e un endpoint pensato per l’ottimizzazione verso i motori generativi.
La parte più istruttiva, però, è la seconda fase, quella in cui il sistema smette di essere un consulente e diventa un ciclo che si autoalimenta. Sette task automatizzati operano su cadenza settimanale e comunicano tra loro attraverso output strutturati: il monitoraggio interroga ogni lunedì l’API di Search Console e annota quali keyword salgono e quali scendono, un componente di scrittura produce contenuti mirati ai gap rilevati, un auditor verifica che ciò che va online rispetti gli standard e mette in bozza quello che non li supera, e la domenica sera un orchestratore sintetizza tutto e fissa le priorità della settimana successiva. La differenza rispetto alla gestione manuale non è la velocità dei singoli interventi, ma l’esistenza di un anello di retroazione che chiude il ciclo tra osservazione, azione e verifica. È la distanza che passa tra un termostato e il doversi alzare ogni ora a controllare la temperatura.
Questo stesso automatismo ha prodotto, e poi dovuto risolvere, il suo problema più serio. Una pubblicazione molto aggressiva, un articolo al giorno per oltre un mese, ha saturato il crawl budget: una quota elevata di URL risultava rilevata ma non indicizzata, perché Googlebot spendeva risorse su contenuti nuovi che il dominio non aveva ancora l’autorevolezza per giustificare. Il sistema ha reagito senza intervento umano diretto: il monitoraggio ha colto l’anomalia nel tasso di indicizzazione, l’orchestratore ha imposto un rallentamento a tre articoli a settimana fino al recupero, la produzione si è adeguata e l’auditor ha iniziato a segnalare i contenuti duplicati da consolidare, mentre in parallelo venivano rilasciati i fix sul codice relativi a sitemap, canonical e webhook di rigenerazione. L’unica azione manuale è stata la sottomissione prioritaria di alcuni URL per accelerare la nuova scansione. Il rientro è risultato lento e ancora in corso alla data dell’ultima rilevazione, con una percentuale di indicizzazione degli URL prioritari ben sotto l’obiettivo operativo. L’episodio è esemplare in entrambe le direzioni: dimostra che un’automazione mal calibrata produce danni SEO reali e misurabili, ma anche che un monitoraggio continuo li intercetta in giorni anziché in settimane.
Sul piano dei risultati di visibilità, nell’arco delle undici settimane le impressioni settimanali sono passate da circa centottanta a oltre quattromila e i click da una manciata a qualche decina, con la posizione media in miglioramento sia sulla finestra dei sette giorni sia su quella dei ventotto. Un dato va letto con la stessa onestà con cui è stato riportato nel caso originale: il tasso di click si è diluito mentre le impressioni crescevano, segno che il sistema stava intercettando query più ampie e meno mirate per intento, un aspetto che resta da affinare. È anche utile ricordare le tempistiche tipiche: gli interventi tecnici sui Core Web Vitals e sui dati strutturati mostrano effetti in due-quattro settimane dalla nuova scansione, mentre quelli sui contenuti, come l’interlinking e l’espansione degli articoli, ne richiedono quattro-otto, e nessun miglioramento è isolabile da un singolo fattore, perché automazione, nuovi contenuti, ottimizzazioni tecniche e maturazione organica del dominio agiscono insieme.
La conclusione più solida riguarda la ripartizione del valore. Una stima retrospettiva, dichiaratamente basata su un singolo caso e quindi non generalizzabile, attribuisce all’esecuzione automatizzata circa il trenta per cento dei miglioramenti: i fix ripetitivi, governati da regole chiare e con criteri di successo oggettivi, che un agente porta a termine in ore invece che in settimane. Il restante settanta per cento resta in capo a decisioni umane (quali keyword presidiare, quale angolo dare ai contenuti, come posizionarsi rispetto ai concorrenti, quando rallentare la pubblicazione) perché l’agente esegue la strategia, non la inventa. Ne discendono due indicazioni pratiche che valgono oltre il singolo progetto: i task di verifica contano più di quelli di produzione, dato che senza un controllo automatico una parte non trascurabile di contenuti sotto standard finirebbe online; e il valore non sta nei singoli componenti ma nel ciclo che li mette in comunicazione. Sette automazioni isolate producono rumore; sette automazioni che si parlano producono un sistema che si corregge da solo. La differenza, in altre parole, non è tecnologica ma architetturale.