Recentemente è stato stabilito con la versione GPT-3 di OpenAI che i modelli più grandi hanno prestazioni migliori. Non solo GPT, ma anche altri modelli NLP come T5 hanno dato risultati migliori rispetto ai lavori precedenti. Storicamente, i sistemi di PNL hanno faticato ad imparare da alcuni esempi. Ma, con GPT-3, i ricercatori hanno dimostrato che il ridimensionamento dei modelli linguistici migliora notevolmente le prestazioni agnostiche, con pochi scatti, a volte persino raggiungendo la competitività con i precedenti approcci di perfezionamento all’avanguardia. Mentre il ridimensionamento è stato collegato per aumentare le prestazioni senza supervisione o almeno semi-supervisionate, lo stesso non si può dire nel caso delle applicazioni di visione artificiale.
Per esplorare il concetto di “big is better”, con i modelli CV, i ricercatori di Google Brain hanno condotto esperimenti con il modello SimCLR modificato: SimCLRv2.
Hanno scoperto che meno etichette, più l’uso agnostico di dati senza etichetta beneficia di una rete più grande!
Come funzionano le reti più grandi?
Importante
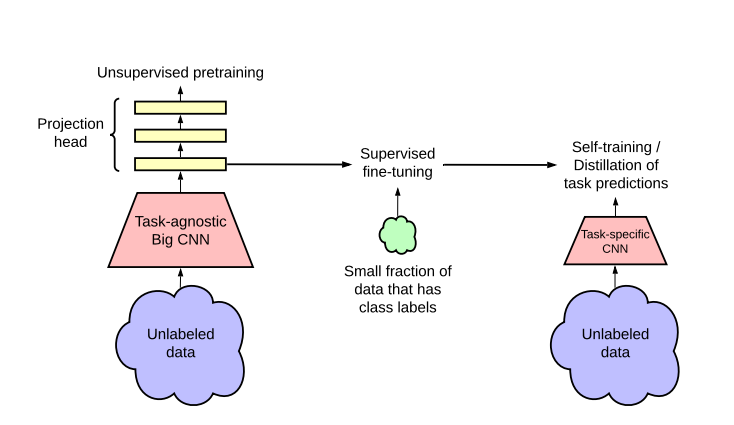
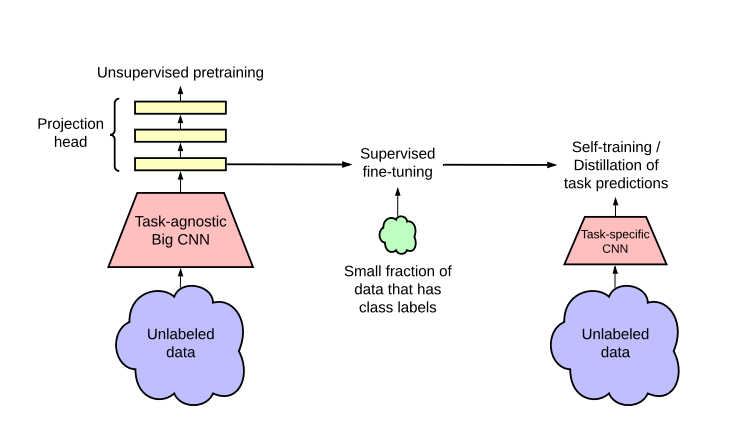
Imparare da pochi esempi etichettati e sfruttare al meglio una grande quantità di dati senza etichetta è un problema di vecchia data nell’apprendimento automatico. Un approccio alternativo per le attività di visione artificiale è quello di sfruttare i dati senza etichetta durante l’apprendimento supervisionato come una forma di regolarizzazione.
In questo lavoro , il framework di apprendimento semi-supervisionato proposto sfrutta i dati senza etichetta in due modi:
uso agnostico nella pre-formazione senza supervisione e
uso specifico dell’attività di auto-allenamento / distillazione
Un approccio all’apprendimento semi-supervisionato prevede un pre-training senza supervisione o auto-supervisionato, seguito da una messa a punto supervisionata.
Sebbene abbia ricevuto poca attenzione nella visione artificiale, questo approccio è diventato predominante nella PNL, dove si allena prima un modello linguistico di grandi dimensioni su testo senza etichetta (ad esempio, Wikipedia), quindi si sintonizza il modello su alcuni esempi etichettati.
FISSALO
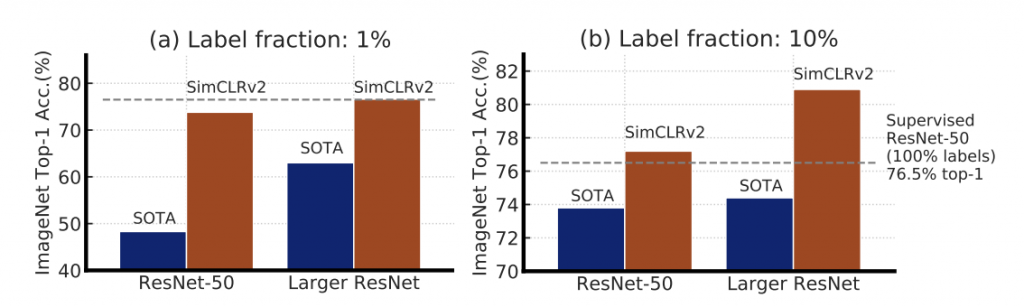
Come mostrato nei grafici sopra, l’accuratezza Top-1 dei precedenti metodi SOTA e SimCLRv2 su ImageNet utilizzando solo l’1% o il 10% delle etichette. La linea tratteggiata indica ResNet-50 completamente supervisionato addestrato con il 100% di etichette.
I risultati mostrano che modelli più grandi sono più efficienti in termini di etichette sia per l’apprendimento supervisionato che semi-supervisionato, ma i guadagni sembrano essere maggiori per l’apprendimento semi-supervisionato.
Cosa significa questo per i laboratori più piccoli?
Secondo un rapporto dei laboratori AI21 , i costi stimati dell’addestramento di modelli BERT di dimensioni diverse sui corpora Wikipedia e Book (15 GB) per una singola sessione di allenamento sono i seguenti:
OpenAI rilascia GPT-3, il modello più grande finora
$ 2,5k – $ 50k (parametri 110 M)
$ 10k – $ 200k (parametri 340 M)
$ 80.000 – $ 1,6 milioni (1,5 parametri B)
A prezzo di listino, l’addestramento della variante di 11 miliardi di parametri di T5 costa ben oltre $ 1,3 milioni per una singola corsa. E, con l’aumentare delle corse, i costi di formazione potrebbero arrivare a nord di $ 10 milioni.
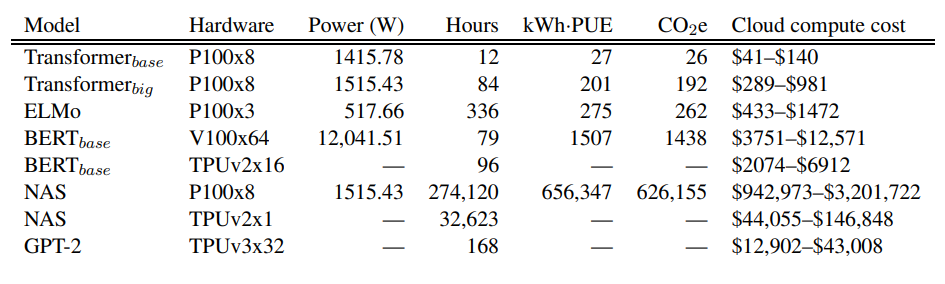
Un approccio simile ma più rigoroso è stato adottato da Emma Strubell e dai suoi colleghi in un lavoro pubblicato l’anno scorso. I risultati del loro lavoro possono essere visti come segue:
FISSALO
Con ogni nuova ricerca, l’idea di reti più grandi migliori sta guadagnando più credibilità. Ma chi può permettersi di sperimentare reti così grandi per verificare eventuali guadagni di precisione? Sicuramente non singoli ricercatori o laboratori di IA di avvio. Aziende come Google e OpenAI (supportate da Microsoft) godono del vantaggio di elevate risorse di calcolo, che possono permettersi di giocare (sperimentare).
Le organizzazioni più piccole non hanno le risorse per replicare i successi delle organizzazioni più grandi. Abbiamo visto il mese scorso come Uber è stato costretto a chiudere i suoi laboratori di intelligenza artificiale a causa di circostanze sfavorevoli. L’aspetto R&S dell’intelligenza artificiale non sembra commercialmente fattibile a breve termine, quindi i gruppi di ricerca più piccoli non avranno altro che fare affidamento sulle API rilasciate da artisti del calibro di OpenAI. Oltre a questo c’è anche una tendenza in calo nei costi di cloud computing. Ad esempio, i prezzi di AWS sono stati ridotti di oltre 65 volte dal suo lancio nel 2006 e fino al 73% tra il 2014 e il 2017.
Quindi possiamo tranquillamente presumere che questa tendenza continuerà e che i calcoli diventeranno accessibili. La compattezza delle reti è anche un’area attiva di ricerca. Anche nel caso del precedente lavoro di ricercatori Google con SimCLRv2, si dimostra che le rappresentazioni generali apprese in modo agnostico possono essere distillate in una rete più specializzata e compatta utilizzando esempi senza etichetta. Detto questo, non si può negare il fatto che la natura intrinseca dell’innovazione del deep learning è truccata contro i gruppi più piccoli.