Una delle tecniche di apprendimento automatico più potenti è l’apprendimento dell’insieme. L’insieme di apprendimento è l’uso di più modelli di machine learning per migliorare l’affidabilità e l’accuratezza delle previsioni. Tuttavia, in che modo l’uso di più modelli di machine learning porta a previsioni più accurate? Che tipo di tecniche vengono utilizzate per creare modelli di apprendimento di insieme? Esploreremo la risposta a queste domande, dando uno sguardo alla logica alla base dell’utilizzo di modelli di insieme e ai modi principali di creare modelli di insieme.
Che cos’è l’apprendimento dell’insieme?
In parole semplici, l’insieme di apprendimento è il processo di addestramento di più modelli di apprendimento automatico e di combinazione dei loro risultati. I diversi modelli vengono utilizzati come base per creare un modello predittivo ottimale. La combinazione di una serie diversificata di singoli modelli di machine learning può migliorare la stabilità del modello complessivo, portando a previsioni più accurate. I modelli di ensemble learning sono spesso più affidabili dei modelli individuali e, di conseguenza, spesso si posizionano al primo posto in molte competizioni di machine learning.
Esistono diverse tecniche che un ingegnere può utilizzare per creare un modello di apprendimento complessivo. Semplici tecniche di apprendimento d’insieme includono cose come la media dei risultati di diversi modelli, mentre ci sono anche metodi e algoritmi più complessi sviluppati appositamente per combinare le previsioni di molti studenti / modelli di base insieme.
Perché utilizzare i metodi di formazione Ensemble?
I modelli di machine learning possono essere diversi l’uno dall’altro per una serie di motivi. Diversi modelli di apprendimento automatico possono operare su diversi campioni dei dati della popolazione, possono essere utilizzate diverse tecniche di modellazione e potrebbe essere utilizzata un’ipotesi diversa.
Immagina di giocare a un gioco a quiz con un grande gruppo di persone. Se fai parte di un team da solo, ci sono sicuramente alcuni argomenti di cui hai conoscenza e molti argomenti di cui non hai conoscenza. Ora supponi di giocare in una squadra con altre persone. Proprio come te, avranno una certa conoscenza delle proprie specialità e nessuna conoscenza di altri argomenti. Tuttavia, quando le tue conoscenze vengono combinate, hai ipotesi più accurate per più campi e il numero di argomenti che il tuo team non ha conoscenza degli strizzacervelli. Questo è lo stesso principio che sta alla base dell’apprendimento dell’insieme, combinando le previsioni di diversi membri del team (modelli individuali) per migliorare l’accuratezza e ridurre al minimo gli errori.
Gli statistici hanno dimostrato che quando a una folla di persone viene chiesto di indovinare la risposta giusta per una data domanda con una gamma di possibili risposte, tutte le loro risposte formano una distribuzione di probabilità. Le persone che conoscono veramente la risposta corretta sceglieranno la risposta giusta con fiducia, mentre le persone che scelgono le risposte sbagliate distribuiranno le loro ipotesi attraverso la gamma di possibili risposte errate. Tornando all’esempio di un gioco a quiz, se tu ei tuoi due amici sapete che la risposta giusta è A, tutti e tre voterete A, mentre le altre tre persone della vostra squadra che non conoscono la risposta rischiano di farlo in modo errato indovina B, C, D o E. Il risultato è che A ha tre voti e le altre risposte probabilmente avranno solo uno o due voti al massimo.
Tutti i modelli hanno una certa quantità di errore. Gli errori per un modello saranno diversi dagli errori prodotti da un altro modello, poiché i modelli stessi sono diversi per i motivi sopra descritti. Quando tutti gli errori vengono esaminati, non saranno raggruppati attorno a una risposta o all’altra, ma saranno sparsi. Le ipotesi errate sono essenzialmente distribuite su tutte le possibili risposte sbagliate, annullandosi a vicenda. Nel frattempo, le ipotesi corrette dai diversi modelli saranno raggruppate attorno alla risposta vera e corretta. Quando vengono utilizzati metodi di formazione d’insieme, la risposta corretta può essere trovata con maggiore affidabilità .
Semplici metodi di formazione dell’insieme
I metodi di formazione di un insieme semplice in genere implicano solo l’applicazione di tecniche di riepilogo statistico , come determinare la modalità, la media o la media ponderata di un insieme di previsioni.
La modalità si riferisce all’elemento che si verifica più di frequente all’interno di un insieme di numeri. Per ottenere la modalità, i singoli modelli di apprendimento restituiscono le loro previsioni e queste previsioni sono considerate voti per la previsione finale. La determinazione della media delle previsioni viene eseguita semplicemente calcolando la media aritmetica delle previsioni, arrotondata all’intero intero più vicino. Infine, è possibile calcolare una media ponderata assegnando pesi diversi ai modelli utilizzati per creare previsioni, con i pesi che rappresentano l’importanza percepita di quel modello. La rappresentazione numerica della previsione della classe viene moltiplicata insieme a un peso da 0 a 1.0, le singole previsioni ponderate vengono quindi sommate e il risultato viene arrotondato al numero intero più vicino.
Metodi avanzati di formazione d’insieme
Esistono tre tecniche di formazione di insieme avanzate primarie, ciascuna delle quali è progettata per affrontare un tipo specifico di problema di apprendimento automatico. Le tecniche di “insacco” vengono utilizzate per diminuire la varianza delle previsioni di un modello, con varianza che si riferisce a quanto il risultato delle previsioni differisce quando si basa sulla stessa osservazione. Le tecniche di “potenziamento” vengono utilizzate per combattere i pregiudizi dei modelli. Infine, lo “stacking” viene utilizzato per migliorare le previsioni in generale.
Gli stessi metodi di apprendimento dell’insieme possono generalmente essere divisi in uno di due diversi gruppi: metodi sequenziali e metodi dell’insieme parallelo.
I metodi di insieme sequenziale prendono il nome “sequenziale” perché gli studenti / modelli di base sono generati in sequenza. Nel caso dei metodi sequenziali, l’idea essenziale è che la dipendenza tra gli studenti di base sia sfruttata per ottenere previsioni più accurate. Gli esempi con etichette errate hanno i loro pesi regolati mentre gli esempi etichettati correttamente mantengono gli stessi pesi. Ogni volta che viene generato un nuovo studente, i pesi cambiano e la precisione (si spera) migliora.
A differenza dei modelli di ensemble sequenziali, i metodi di ensemble paralleli generano gli studenti di base in parallelo. Quando si esegue l’apprendimento d’insieme parallelo, l’idea è di sfruttare il fatto che gli studenti di base hanno indipendenza, poiché il tasso di errore generale può essere ridotto facendo la media delle previsioni dei singoli studenti.
I metodi di formazione dell’insieme possono essere di natura omogenea o eterogenea. La maggior parte dei metodi di apprendimento di insieme sono omogenei, il che significa che utilizzano un unico tipo di modello / algoritmo di apprendimento di base. Al contrario, insiemi eterogenei fanno uso di diversi algoritmi di apprendimento, diversificando e variando gli studenti per garantire che l’accuratezza sia la più alta possibile.
Esempi di algoritmi di apprendimento dell’insieme
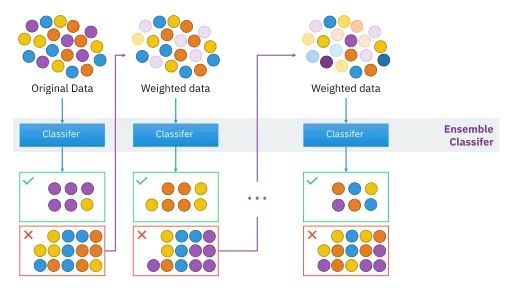
Esempi di metodi di insieme sequenziali includono AdaBoost , XGBoost e il potenziamento dell’albero a gradiente . Questi sono tutti modelli di potenziamento. Per questi modelli di potenziamento, l’obiettivo è convertire gli studenti deboli e con prestazioni insufficienti in studenti più potenti. Modelli come AdaBoost e XGBoost iniziano con molti studenti deboli che ottengono risultati leggermente migliori rispetto a supposizioni casuali. Man mano che la formazione continua, i pesi vengono applicati ai dati e adeguati. Le istanze che sono state classificate in modo errato dagli studenti nei primi round di formazione ricevono più peso. Dopo che questo processo viene ripetuto per il numero desiderato di round di formazione, le previsioni vengono unite tramite una somma ponderata (per le attività di regressione) e un voto ponderato (per le attività di classificazione).
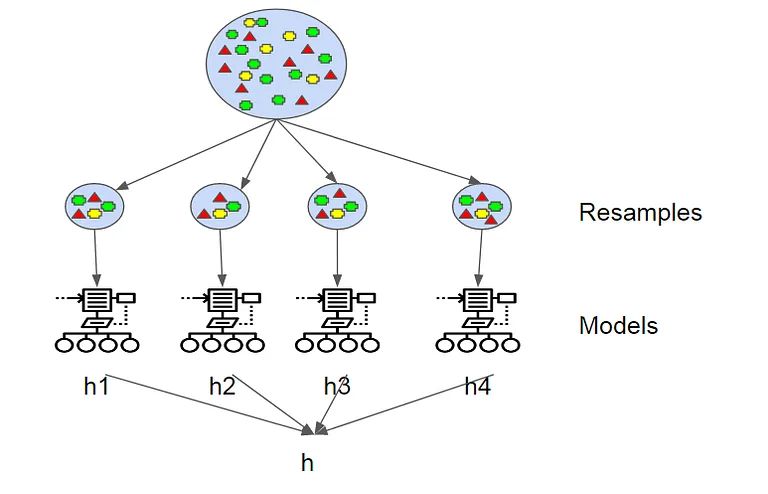
Un esempio di un modello di insieme parallelo è un classificatore Random Forest e Random Forests è anche un esempio di una tecnica di insaccamento. Il termine “insacco” deriva da “aggregazione bootstrap”. I campioni vengono prelevati dal set di dati totale utilizzando una tecnica di campionamento nota come “campionamento bootstrap”, che viene utilizzata dagli studenti di base per fare previsioni. Per le attività di classificazione, gli output dei modelli di base vengono aggregati utilizzando il voto, mentre viene calcolata la media insieme per le attività di regressione. Random Forests utilizza alberi decisionali individuali come studenti di base e ogni albero nell’insieme viene costruito utilizzando un campione diverso dal set di dati. Un sottoinsieme casuale di caratteristiche viene utilizzato anche per generare l’albero. Portando ad alberi decisionali individuali altamente randomizzati, che sono tutti combinati insieme per fornire previsioni affidabili.
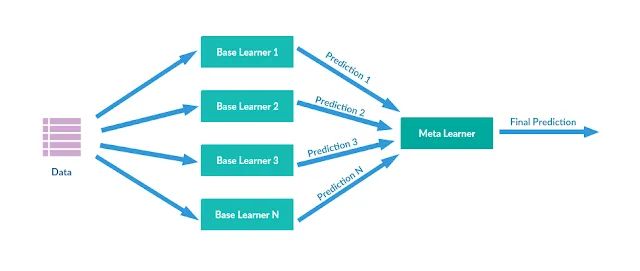
In termini di tecniche di stacking ensemble, più modelli di regressione o classificazione vengono combinati insieme attraverso un meta-modello di livello superiore. I modelli di base di livello inferiore vengono addestrati alimentando l’intero set di dati. Gli output dei modelli di base vengono quindi utilizzati come funzionalità per addestrare il meta-modello. I modelli di insieme di impilamento sono spesso di natura eterogenea.