Gli algoritmi di apprendimento automatico hanno guadagnato fama per essere in grado di scovare informazioni rilevanti da set di dati con molte funzionalità, come tabelle con dozzine di righe e immagini con milioni di pixel. Grazie ai progressi nel cloud computing, è spesso possibile eseguire modelli di machine learning di grandi dimensioni senza notare quanta potenza di calcolo funziona dietro le quinte.
Ma ogni nuova funzionalità che aggiungi al tuo problema aumenta la sua complessità, rendendo più difficile risolverlo con algoritmi di apprendimento automatico. I data scientist utilizzano la riduzione della dimensionalità, un insieme di tecniche che rimuovono le caratteristiche eccessive e irrilevanti dai loro modelli di apprendimento automatico.
La riduzione della dimensionalità abbatte i costi dell’apprendimento automatico e talvolta consente di risolvere problemi complicati con modelli più semplici.
La maledizione della dimensionalità
I modelli di machine learning associano le funzionalità ai risultati. Ad esempio, supponi di voler creare un modello che preveda la quantità di pioggia in un mese. Hai un set di dati di informazioni diverse raccolte da città diverse in mesi separati. I punti dati includono temperatura, umidità, popolazione della città, traffico, numero di concerti tenuti in città, velocità del vento, direzione del vento, pressione dell’aria, numero di biglietti dell’autobus acquistati e quantità di pioggia. Ovviamente, non tutte queste informazioni sono rilevanti per la previsione delle precipitazioni.
Alcune delle funzionalità potrebbero non avere nulla a che fare con la variabile di destinazione. Evidentemente, la popolazione e il numero di biglietti dell’autobus acquistati non influiscono sulle precipitazioni. Altre caratteristiche potrebbero essere correlate alla variabile obiettivo, ma non avere una relazione causale con essa. Ad esempio, il numero di concerti all’aperto potrebbe essere correlato al volume delle precipitazioni, ma non è un buon indicatore della pioggia. In altri casi, come l’emissione di carbonio, potrebbe esserci un collegamento tra l’elemento e la variabile obiettivo, ma l’effetto sarà trascurabile.
In questo esempio, è evidente quali caratteristiche sono preziose e quali sono inutili. in altri problemi, le caratteristiche eccessive potrebbero non essere ovvie e richiedere un’ulteriore analisi dei dati.
Ma perché preoccuparsi di rimuovere le dimensioni extra? Quando hai troppe funzionalità, avrai bisogno anche di un modello più complesso. Un modello più complesso significa che avrai bisogno di molti più dati di addestramento e più potenza di calcolo per addestrare il tuo modello a un livello accettabile.
E poiché l’apprendimento automatico non ha alcuna comprensione della causalità , i modelli cercano di mappare qualsiasi caratteristica inclusa nel loro set di dati alla variabile di destinazione, anche se non esiste una relazione causale. Ciò può portare a modelli imprecisi ed errati.
D’altra parte, ridurre il numero di funzionalità può rendere il tuo modello di machine learning più semplice, più efficiente e meno affamato di dati.
I problemi causati da troppe funzionalità vengono spesso definiti “maledizione della dimensionalità” e non sono limitati ai dati tabulari. Considera un modello di machine learning che classifica le immagini. Se il tuo set di dati è composto da immagini 100 × 100 pixel, lo spazio problematico ha 10.000 funzioni, una per pixel. Tuttavia, anche nei problemi di classificazione delle immagini, alcune delle funzionalità sono eccessive e possono essere rimosse.
La riduzione della dimensionalità identifica e rimuove le funzionalità che danneggiano le prestazioni del modello di apprendimento automatico o che non contribuiscono alla sua precisione. Esistono diverse tecniche di dimensionalità, ognuna delle quali è utile per determinate situazioni.
Selezione delle caratteristiche

Un metodo di riduzione della dimensionalità di base e molto efficiente consiste nell’identificare e selezionare un sottoinsieme delle caratteristiche più rilevanti per la variabile target. Questa tecnica è chiamata “selezione delle caratteristiche”. La selezione delle funzionalità è particolarmente efficace quando si ha a che fare con dati tabulari in cui ogni colonna rappresenta un tipo specifico di informazioni.
Quando si effettua la selezione delle caratteristiche, i data scientist fanno due cose: mantenere le caratteristiche che sono altamente correlate con la variabile target e contribuiscono maggiormente alla varianza del set di dati. Librerie come Scikit-learn di Python hanno molte buone funzioni per analizzare, visualizzare e selezionare le giuste funzionalità per i modelli di machine learning.
Ad esempio, un data scientist può utilizzare grafici a dispersione e mappe di calore per visualizzare la covarianza di diverse caratteristiche. Se due funzionalità sono altamente correlate tra loro, avranno un effetto simile sulla variabile di destinazione e non sarà necessario includerle entrambe nel modello di apprendimento automatico. Pertanto, è possibile rimuoverne uno senza causare un impatto negativo sulle prestazioni del modello.
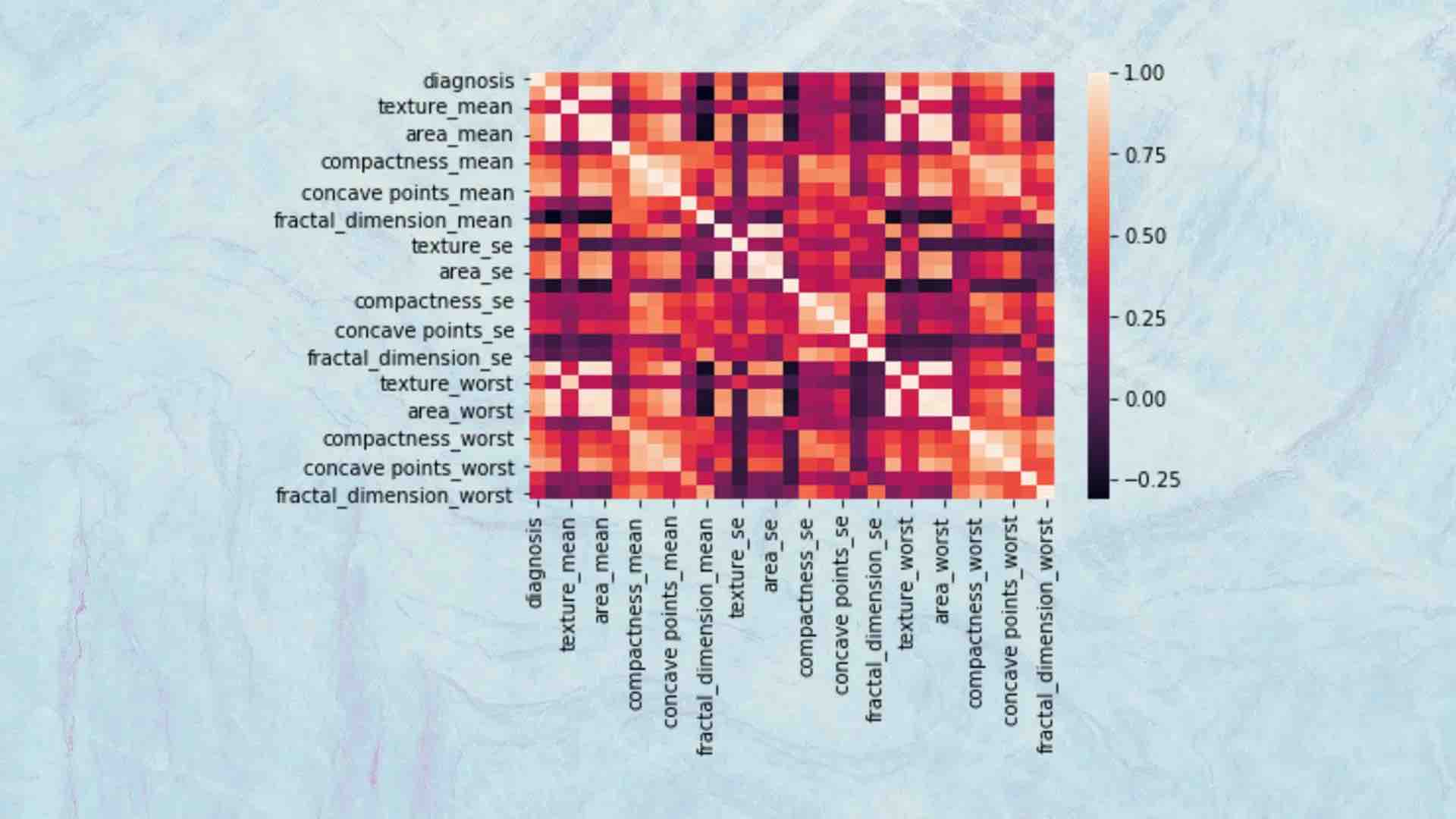
Sopra: le mappe di calore illustrano la covarianza tra le diverse caratteristiche. Sono una buona guida per trovare ed eliminare le caratteristiche eccessive.
Gli stessi strumenti possono aiutare a visualizzare le correlazioni tra le caratteristiche e la variabile di destinazione. Questo aiuta a rimuovere le variabili che non influenzano l’obiettivo. Ad esempio, potresti scoprire che su 25 funzionalità nel tuo set di dati, sette di esse rappresentano il 95 percento dell’effetto sulla variabile di destinazione. Ciò ti consentirà di eliminare 18 funzionalità e rendere il tuo modello di apprendimento automatico molto più semplice senza subire una penalità significativa per la precisione del tuo modello.
Proiezioni tecniche
A volte, non hai la possibilità di rimuovere singole funzionalità. Ma questo non significa che non puoi semplificare il tuo modello di machine learning. Le tecniche di proiezione, note anche come “estrazione delle caratteristiche”, semplificano un modello comprimendo diverse caratteristiche in uno spazio di dimensioni inferiori.
Un esempio comune utilizzato per rappresentare le tecniche di proiezione è lo “swiss roll” (nella foto sotto), un insieme di punti dati che ruotano attorno a un punto focale in tre dimensioni. Questo set di dati ha tre caratteristiche. Il valore di ogni punto (la variabile target) viene misurato in base a quanto è vicino lungo il percorso contorto al centro dello swiss roll. Nell’immagine sotto, i punti rossi sono più vicini al centro e i punti gialli sono più lontani lungo il rotolo.
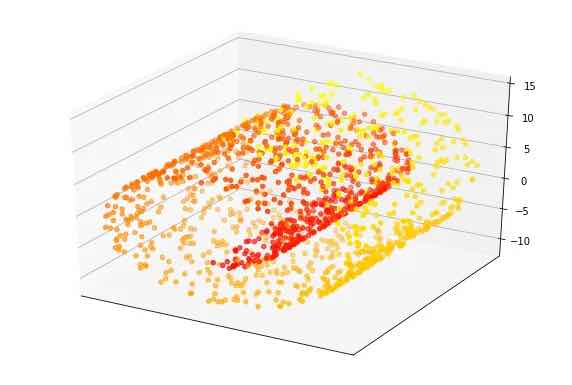
Allo stato attuale, creare un modello di apprendimento automatico che associ le caratteristiche dei punti swiss roll al loro valore è un compito difficile e richiederebbe un modello complesso con molti parametri. Ma con l’aiuto delle tecniche di riduzione della dimensionalità, i punti possono essere proiettati in uno spazio di dimensione inferiore che può essere appreso con un semplice modello di apprendimento automatico.
Esistono varie tecniche di proiezione. Nel caso dell’esempio precedente, abbiamo utilizzato “incorporamento localmente lineare”, un algoritmo che riduce la dimensione dello spazio problematico preservando gli elementi chiave che separano i valori dei punti dati. Quando i nostri dati vengono elaborati con LLE, il risultato è simile all’immagine seguente, che è come una versione srotolata del rotolo svizzero. Come puoi vedere, i punti di ogni colore rimangono insieme. In effetti, questo problema può ancora essere semplificato in una singola funzionalità e modellato con la regressione lineare, l’algoritmo di apprendimento automatico più semplice.

Sebbene questo esempio sia ipotetico, dovrai spesso affrontare problemi che possono essere semplificati se proietti le caratteristiche in uno spazio di dimensioni inferiori. Ad esempio, “analisi delle componenti principali” (PCA), un popolare algoritmo di riduzione della dimensionalità, ha trovato molte applicazioni utili per semplificare i problemi di apprendimento automatico.
Nell’eccellente libro Hands-on Machine Learning with Python , il data scientist Aurelien Geron mostra come è possibile utilizzare PCA per ridurre il set di dati MNIST da 784 funzionalità (28 × 28 pixel) a 150 funzionalità preservando il 95% della varianza. Questo livello di riduzione della dimensionalità ha un enorme impatto sui costi di formazione e gestione delle reti neurali artificiali .

Ci sono alcuni avvertimenti da considerare sulle tecniche di proiezione. Dopo aver sviluppato una tecnica di proiezione, è necessario trasformare i nuovi punti dati nello spazio della dimensione inferiore prima di eseguirli attraverso il modello di apprendimento automatico. Tuttavia, i costi di questa fase di pre-elaborazione non sono paragonabili ai vantaggi di avere un modello più leggero. Una seconda considerazione è che i punti dati trasformati non sono direttamente rappresentativi delle loro caratteristiche originali e ritrasformarli nello spazio originale può essere complicato e in alcuni casi impossibile. Ciò potrebbe rendere difficile interpretare le inferenze fatte dal tuo modello .
Riduzione della dimensionalità nel toolbox del machine learning
Avere troppe funzionalità renderà il tuo modello inefficiente. Ma anche tagliare la rimozione di troppe funzionalità non aiuterà. La riduzione della dimensionalità è uno dei tanti strumenti che i data scientist possono utilizzare per realizzare modelli di machine learning migliori. E come con ogni strumento, devono essere usati con cautela e cura.