Un sistema di machine learning per riscrivere un articolo mentre lo leggi
Una nuova ricerca dal Canada propone un metodo per riscrivere automaticamente un articolo mentre lo leggi, basato sullo “scorrimento” in stile Tinder, o sull’osservazione passiva dell’interazione del lettore con i vari tipi di contenuto che l’articolo contiene.
Il sistema, intitolato Hone As You Read (HARE), è presentato in un documento della Western University in Ontario, Canada, con il codice Python corrispondente su GitHub .
L’idea centrale del progetto è che un articolo può contenere vari tipi di contenuto, evolvendo (molto simile a questo) dal titolo fino a ulteriori dettagli. Le parti successive di un articolo possono contenere diversi tipi di materiale di supporto, casi d’uso, ipotesi o congetture sulle ramificazioni delle notizie.
In HARE, se non ti piace questo tipo di materiale, puoi votarlo paragrafo per paragrafo mentre il sistema apprende le tue preferenze, in modo che nel momento in cui scorri verso il basso, contenuti simili al materiale che hai “downvoted” è già stato rimosso o riscritto. Se non vuoi partecipare attivamente alla formazione del sistema, HARE può dedurre le tue scelte osservando le tue interazioni passive con il documento.
Votazione in stile Tinder per frasi spiacevoli
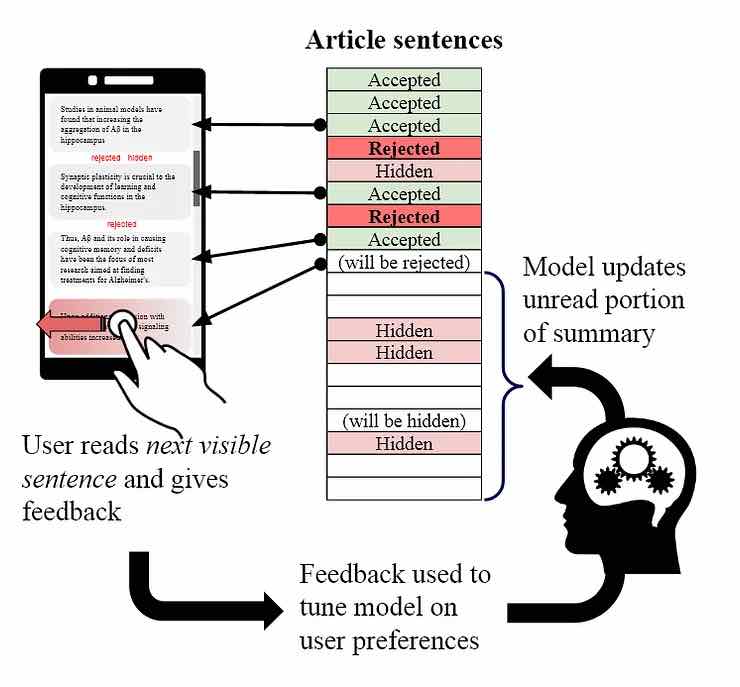
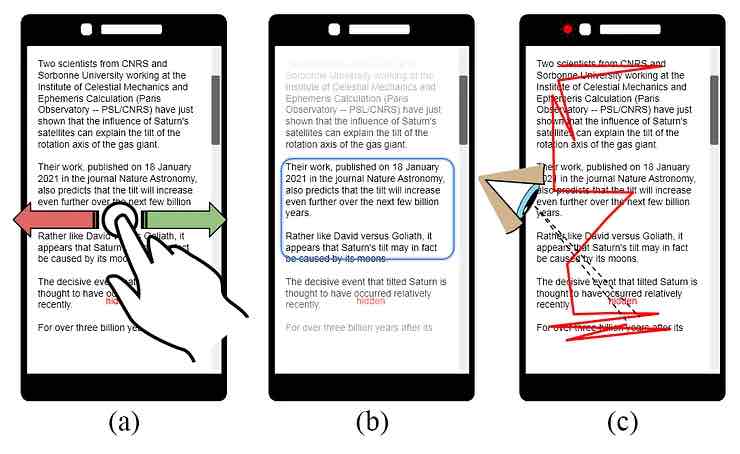
Nell’immagine seguente, vediamo tre possibili tipi di categorizzazione dedotta per HARE, in base al comportamento esplicito o implicito dell’utente. Nel primo caso (a sinistra), l’utente “ scorre attivamente a sinistra ” (o a destra), in un gesto di voto in stile Tinder che esprime approvazione o dispiacere per il contenuto del paragrafo o della frase, o per il suo stile, complessità o tono.
Nel secondo caso (al centro), il sistema utilizza il tempo di permanenza come metrica di interesse dell’utente, in base al posizionamento e alla durata della pausa di scorrimento.
Nel terzo caso (a destra), HARE utilizza la fotocamera dello smartphone per stimare il percorso e il tempo di permanenza della posizione dello sguardo dello spettatore attraverso i paragrafi dei documenti visibili.
I ricercatori sostengono che un maggiore tempo di permanenza su un qualsiasi paragrafo può indicare un maggiore interesse dell’utente, anche se logicamente questo potrebbe non essere il caso in cui lo spettatore sta cercando di assimilare un testo che può essere complicato o semplicemente scritto male.
Pre-elaborazione del contenuto in base alle preferenze dell’utente
L’articolo tratta l’esperienza utente di HARE per articolo, ma chiaramente l’interazione storica dell’utente con i documenti consente la personalizzazione delle esperienze di lettura future, riconoscendo costantemente i tipi di contenuto e applicando le preferenze dell’utente basate su modelli ai nuovi articoli, in modo che la necessità di interazione diminuisce man mano che l’utente vede sempre meno contenuti “indesiderati”.
HARE si caratterizza come un algoritmo di riepilogo, che consente di riscrivere contenuti invisibili più in basso nella pagina in termini di stile o concisione prima che l’utente vi arrivi; ma il documento chiarisce che può anche rimuovere preventivamente i contenuti in base al feedback degli utenti.
A scopo di test, il sistema ha utilizzato un corpus di 11.222 articoli del quotidiano britannico Daily Mail ed è stato valutato tramite una distribuzione di prova sull’app di chat di Telegram. Gli articoli con meno di dieci paragrafi sono stati scartati a scopo di prova.
La metodologia dei ricercatori utilizza il clustering K-Means sugli incorporamenti di frasi SBERT negli articoli, con pesi inizialmente casuali per i concetti trattati.
In un ampio gruppo di algoritmi e approcci, HARE presenta tre modelli di confronto, il primo dei quali (ORACLEGREEDY) ha accesso alle preferenze dell’utente precedente, indicando l’intento che l’algoritmo potrebbe pre-elaborare gli articoli al caricamento, piuttosto che in modo interattivo.
Gli altri modelli, ORACLESORTED e ORACLEUNIFORM, selezionano rispettivamente le frasi in base al livello di interesse o in modo casuale in tutto l’articolo.
Rimozione e riscrittura dei contenuti
Sorprendentemente, ORACLEUNIFORM ha superato il set di controllo, anche se non ha accesso agli interessi degli utenti precedenti. I ricercatori sostengono che ciò è dovuto al fatto che tratta l’intero articolo in una volta sola, “scegliendo solo le frasi più interessanti”. I ricercatori ammettono che ciò potrebbe limitare il contenuto disponibile a quelle frasi che trattano esclusivamente il concetto più importante, rimuovendo logicamente altro testo che potrebbe occuparsi di ramificazioni o valutazione del concetto.
I riepiloghi estrattivi utilizzati in HARE sono LexRank , SumBasic e TextRank .
HARE è stato testato su 13 volontari nel corso di 70 prove e diversi approcci algoritmici, ed è stato in grado di aggiornare i riepiloghi (testo riscritto / asportato) da qualche parte tra 1,3 millisecondi e 100 ms su un laptop di livello consumer, a seconda del modello in prova. I risultati hanno rilevato che i modelli che hanno rimosso la maggior parte del testo non hanno funzionato bene, principalmente perché ciò può influire sulla coerenza del testo rimanente.
Implicazioni etiche della riscrittura dinamica degli articoli
I ricercatori riconoscono le preoccupazioni etiche riguardo alle tecnologie di questa natura:
‘L’attività HARE è intesa per la progettazione di future applicazioni rivolte agli utenti. In base alla progettazione, queste applicazioni hanno la capacità di controllare ciò che un utente legge da un determinato articolo. È possibile che, se utilizzati senza cure sufficienti, questi strumenti possano esacerbare l’effetto “ecocamera” già prodotto da feed di notizie automatizzati, risultati di ricerca e comunità online “.
Tuttavia, notano anche che un tale sistema potrebbe essere utilizzato in future applicazioni per mitigare l’effetto della camera d’eco iniettando del testo che propone punti di vista alternativi che potrebbero non essere stati inizialmente presenti nell’articolo. Osservano: “La ponderazione di questo fattore potrebbe essere regolata per fornire sia un’esperienza di lettura coinvolgente che l’esposizione a una varietà di idee”.
Quelli che probabilmente trarranno vantaggio da un tale sistema, secondo i ricercatori, sono i lettori che vogliono risparmiare tempo nell’acquisizione di informazioni e gli editori di contenuti