Che cos’è l’apprendimento con pochi colpi?Approcci all’apprendimento con pochi colpiApprocci a livello di datiApprocci a livello di parametroApprendimento metricoApplicazioni per l’apprendimento con pochi colpi
L’apprendimento con pochi colpi si riferisce a una varietà di algoritmi e tecniche utilizzati per sviluppare un modello di intelligenza artificiale utilizzando una quantità molto ridotta di dati di addestramento. L’apprendimento con pochi tentativi si sforza di consentire a un modello di intelligenza artificiale di riconoscere e classificare nuovi dati dopo essere stato esposto a un numero relativamente ridotto di istanze di addestramento. L’addestramento con pochi colpi è in contrasto con i metodi tradizionali di addestramento dei modelli di apprendimento automatico , in cui viene tipicamente utilizzata una grande quantità di dati di addestramento. L’apprendimento con pochi colpi viene utilizzato principalmente nella visione artificiale.
Per sviluppare una migliore intuizione per l’apprendimento con pochi colpi, esaminiamo il concetto in modo più dettagliato. Esamineremo le motivazioni e i concetti alla base dell’apprendimento pochi colpi, esploreremo alcuni vari tipi di apprendimento pochi colpi e tratteremo alcuni modelli utilizzati nell’apprendimento pochi colpi ad alto livello. Infine, esamineremo alcune applicazioni per l’apprendimento in pochi colpi.
Che cos’è l’apprendimento con pochi colpi?
“Few-shot learning” descrive la pratica di addestrare un modello di machine learning con una quantità minima di dati. In genere, i modelli di machine learning vengono addestrati su grandi volumi di dati, più grandi sono, meglio è. Tuttavia, l’apprendimento pochi colpi è un concetto importante di apprendimento automatico per diversi motivi.
Uno dei motivi per utilizzare l’apprendimento in pochi passaggi è che può ridurre drasticamente la quantità di dati necessari per addestrare un modello di apprendimento automatico, riducendo il tempo necessario per etichettare set di dati di grandi dimensioni. Allo stesso modo, l’apprendimento pochi colpi riduce la necessità di aggiungere funzionalità specifiche per varie attività quando si utilizza un set di dati comune per creare campioni diversi. L’apprendimento con pochi colpi può idealmente rendere i modelli più robusti e in grado di riconoscere oggetti basati su meno dati, creando modelli più generali rispetto ai modelli altamente specializzati che sono la norma.
L’apprendimento con pochi colpi è più comunemente utilizzato nel campo della visione artificiale, poiché la natura dei problemi di visione artificiale richiede grandi volumi di dati o un modello flessibile.
Sottocategorie
La frase apprendimento “pochi colpi” è in realtà solo un tipo di apprendimento che utilizza pochissimi esempi di formazione. Dal momento che stai usando solo “pochi” esempi di addestramento, ci sono sottocategorie di apprendimento con pochi colpi che coinvolgono anche la formazione con una quantità minima di dati. L’apprendimento “one-shot” è un altro tipo di addestramento del modello che implica l’insegnamento a un modello di riconoscere un oggetto dopo aver visto solo un’immagine di quell’oggetto. Le tattiche generali utilizzate per l’apprendimento one-shot e l’apprendimento per pochi colpi sono le stesse. Essere consapevoli del fatto che il termine apprendimento “pochi colpi” potrebbe essere usato come termine generico per descrivere qualsiasi situazione in cui un modello viene addestrato con pochissimi dati.
Approcci all’apprendimento con pochi colpi
La maggior parte degli approcci all’apprendimento di pochi colpi può rientrare in una delle tre categorie: approcci a livello di dati, approcci a livello di parametro e approcci basati su metriche.
Approcci a livello di dati
Gli approcci a livello di dati all’apprendimento con pochi colpi sono concettualmente molto semplici. Per addestrare un modello quando non disponi di dati di addestramento sufficienti, puoi semplicemente ottenere più dati di addestramento. Esistono varie tecniche che un data scientist può utilizzare per aumentare la quantità di dati di addestramento di cui dispone.
Dati di addestramento simili possono eseguire il backup dei dati di destinazione esatti su cui stai addestrando un classificatore. Ad esempio, se stai addestrando un classificatore a riconoscere tipi specifici di cani ma mancavano molte immagini della specie particolare che stavi cercando di classificare, potresti includere molte immagini di cani che aiuterebbero il classificatore a determinare le caratteristiche generali che compongono un cane .
L’aumento dei dati può creare più dati di addestramento per un classificatore. Ciò comporta in genere l’applicazione di trasformazioni ai dati di addestramento esistenti, come la rotazione di immagini esistenti in modo che il classificatore esamini le immagini da diverse angolazioni. I GAN possono anche essere utilizzati per generare nuovi esempi di addestramento basati su ciò che apprendono dai pochi esempi autentici di dati di addestramento che hai.
Approcci a livello di parametro
Meta-apprendimento
Un approccio a livello di parametro all’apprendimento con pochi colpi prevede l’uso di una tecnica chiamata ” meta-apprendimento “. Il meta-apprendimento implica l’ insegnamento a un modello di come apprendere quali caratteristiche sono importanti in un’attività di apprendimento automatico. Ciò può essere ottenuto creando un metodo per regolare il modo in cui viene esplorato lo spazio dei parametri di un modello.
Il meta-apprendimento utilizza due diversi modelli: un modello insegnante e un modello studente. Il modello “insegnante” e un modello “studente”. Il modello dell’insegnante impara a incapsulare lo spazio dei parametri, mentre l’algoritmo dello studente impara a riconoscere e classificare gli elementi effettivi nel set di dati. In altre parole, il modello insegnante impara a ottimizzare un modello, mentre il modello studente impara a classificare. Gli output del modello insegnante vengono utilizzati per addestrare il modello studente, mostrando al modello studente come negoziare l’ampio spazio di parametri che risulta da dati di addestramento insufficienti. Da qui il “meta” nel meta-apprendimento.
Uno dei problemi principali con i modelli di apprendimento a pochi colpi è che possono facilmente sovraadattare ai dati di allenamento, poiché spesso hanno spazi ad alta dimensione. Limitare lo spazio dei parametri di un modello risolve questo problema e, sebbene possa essere ottenuto applicando tecniche di regolarizzazione e selezionando le funzioni di perdita appropriate, l’uso di un algoritmo dell’insegnante può migliorare notevolmente le prestazioni di un modello a pochi colpi.
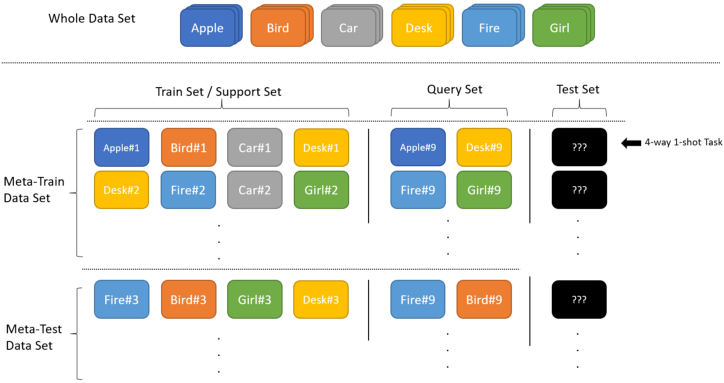
Un modello di classificazione dell’apprendimento a pochi colpi (il modello dello studente) tenterà di generalizzare in base alla piccola quantità di dati di formazione forniti e la sua precisione può migliorare con un modello dell’insegnante per dirigerlo attraverso lo spazio dei parametri ad alta dimensione. Questa architettura generale viene definita meta-discente “basata sul gradiente”.
Il processo completo di formazione di un meta studente basato sul gradiente è il seguente:
Crea il modello base-studente (insegnante)
Formare il modello base-discente sul set di supporto
Chiedi allo studente di base di restituire previsioni per il set di query
Formare il meta-studente (studente) sulla perdita derivata dall’errore di classificazione
Variazioni sul meta-apprendimento
Il meta-apprendimento indipendente dal modello è un metodo utilizzato per aumentare la tecnica di meta-apprendimento basata sul gradiente di base che abbiamo trattato sopra.
Come spiegato sopra, un meta-studente basato sul gradiente utilizza l’esperienza precedente acquisita da un modello di insegnante per perfezionare se stesso e fornire previsioni più accurate per una piccola quantità di dati di formazione. Tuttavia, iniziare con parametri inizializzati casualmente significa che il modello può ancora potenzialmente sovradattare i dati. Per evitare ciò, viene creato un meta-studente “indipendente dal modello” limitando l’influenza del modello dell’insegnante / modello base. Invece di addestrare il modello dello studente direttamente sulla perdita per le previsioni fatte dal modello dell’insegnante, il modello dello studente viene addestrato sulla perdita per le proprie previsioni.
Per ogni episodio di formazione di un meta-studente indipendente dal modello:
Viene creata una copia dell’attuale modello meta-studente.
La copia viene addestrata con l’assistenza del modello base / modello insegnante.
La copia restituisce previsioni per i dati di addestramento.
La perdita calcolata viene utilizzata per aggiornare il meta-studente.
Apprendimento metrico
Gli approcci di apprendimento metrico alla progettazione di un modello di apprendimento a pochi colpi in genere implicano l’ uso di metriche di distanza di base per effettuare confronti tra i campioni in un set di dati. Gli algoritmi di apprendimento metrico come la distanza del coseno vengono utilizzati per classificare i campioni di query in base alla loro somiglianza con i campioni di supporto. Per un classificatore di immagini, ciò significherebbe semplicemente classificare le immagini in base alla somiglianza di caratteristiche superficiali. Dopo che un set di immagini di supporto è stato selezionato e trasformato in un vettore di incorporamento, lo stesso viene fatto con il set di query e quindi vengono confrontati i valori per i due vettori, con il classificatore che seleziona la classe che ha i valori più vicini al set di query vettorizzato .
Una soluzione metrica più avanzata è la ” rete prototipica “. Le reti prototipiche raggruppano i punti dati combinando i modelli di clustering con la classificazione basata su metriche descritta sopra. Come nel clustering K-means, i centroidi per i cluster vengono calcolati per le classi nei set di supporto e query. Viene quindi applicata una metrica della distanza euclidea per determinare la differenza tra i set di query ei centroidi del set di supporto, assegnando il set di query a qualsiasi classe del set di supporto più vicino.
La maggior parte degli altri approcci di apprendimento con pochi colpi sono solo variazioni delle tecniche di base trattate sopra.
Applicazioni per l’apprendimento con pochi colpi
L’apprendimento con pochi colpi ha applicazioni in molti diversi sottocampi della scienza dei dati , come visione artificiale, elaborazione del linguaggio naturale , robotica, sanità e elaborazione dei segnali.
Le applicazioni per l’apprendimento di pochi colpi nello spazio di visione artificiale includono il riconoscimento efficiente dei caratteri, la classificazione delle immagini, il riconoscimento degli oggetti, il tracciamento degli oggetti, la previsione del movimento e la localizzazione delle azioni. Le applicazioni di elaborazione del linguaggio naturale per l’apprendimento in pochi passaggi includono traduzione, completamento di frasi, classificazione dell’intenzione dell’utente, analisi del sentiment e classificazione del testo con più etichette. L’apprendimento con pochi colpi può essere utilizzato nel campo della robotica per aiutare i robot a conoscere le attività da poche dimostrazioni, consentendo ai robot di imparare come eseguire azioni, muoversi e navigare nel mondo che li circonda. La scoperta di nuovi farmaci è un’area emergente dell’assistenza sanitaria basata sull’intelligenza artificiale. Infine, l’apprendimento pochi colpi ha applicazioni per l’elaborazione del segnale acustico, che è il processo di analisi dei dati sonori,