I ricercatori di Facebook e della New York University (NYU) affermano di aver sviluppato tre modelli di apprendimento automatico che potrebbero aiutare i medici a prevedere come potrebbero svilupparsi le condizioni di un paziente COVID-19. I modelli open source, che richiedono tutti non più di una sequenza di raggi X, predicono apparentemente il deterioramento del paziente fino a quattro giorni in anticipo e la quantità di ossigeno supplementare (se presente) di cui un paziente potrebbe aver bisogno.
La nuova pandemia di coronavirus continua a raggiungere nuove allarmanti vette negli Stati Uniti e in tutto il mondo. Negli Stati Uniti la scorsa settimana, per la prima volta dall’inizio della crisi sanitaria, le morti giornaliere hanno superato le 4.000. Numeri record di infezioni nell’ordine delle centinaia di migliaia al giorno hanno messo a dura prova i sistemi sanitari a livello nazionale, con stati come la California che lottano per mantenere lo spazio in unità di terapia intensiva sovraccariche.
Huiying Medical, Alibaba , RadLogics , Lunit , DarwinAI , Infervision , Qure.ai e altri hanno sviluppato algoritmi AI che apparentemente diagnosticano COVID-19 dai raggi X con elevata precisione. Ciò che differenzia l’approccio adottato da Facebook e dalla NYU, tuttavia, è che tenta di prevedere le traiettorie cliniche a lungo termine. Stanford, Mount Sinai e i fornitori di cartelle cliniche elettroniche Epic e Cerner hanno sviluppato modelli che rivelano punteggi di rischio per le probabilità di un paziente di morire o aver bisogno di un ventilatore, ma pochi (se ce ne sono) fanno queste previsioni da una singola scansione o cartella clinica elettronica.
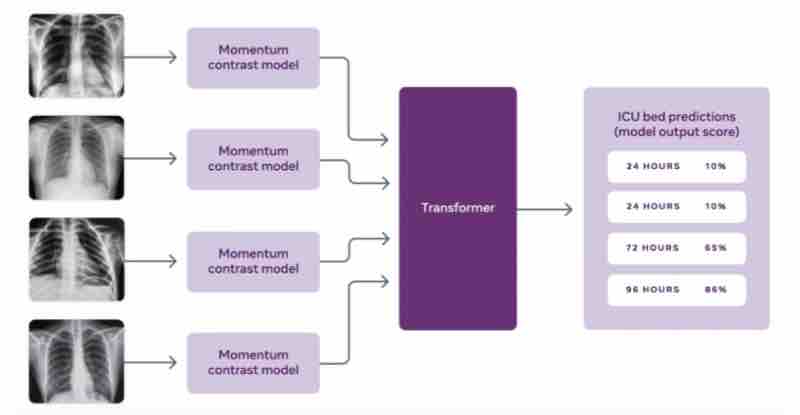
Nell’ambito di una collaborazione in corso con l’Unità di analisi predittiva e il Dipartimento di radiologia della NYU Langone Health, i ricercatori di Facebook hanno pre-addestrato un sistema di intelligenza artificiale su due grandi set di dati radiografici del torace pubblici, MIMIC-CXR-JPG e CheXpert, utilizzando una tecnica di apprendimento auto-supervisionato chiamato Momentum Contrast (MoCo). L’apprendimento autogestito ha consentito al modello MoCo di apprendere dalle scansioni a raggi X all’interno dei set di dati, anche quando le etichette che spiegavano quelle scansioni non erano disponibili.
Il passo successivo è stato mettere a punto il modello MoCo utilizzando una versione estesa del dataset NYU COVID-19 disponibile pubblicamente. I ricercatori hanno costruito classificatori con 26.838 immagini a raggi X di 4.914 pazienti, annotate per indicare se le condizioni del paziente sono peggiorate entro 24, 48 o 72 ore dalla scansione in questione. Un classificatore prevede il deterioramento del paziente sulla base di una singola radiografia, mentre l’altro utilizza una sequenza di raggi X aggregati.
I ricercatori affermano che i classificatori che si basano su una serie di immagini a raggi X hanno superato gli esperti umani nel prevedere le esigenze di terapia intensiva, la mortalità e gli eventi avversi fino a 96 ore in anticipo. Sebbene i risultati non siano necessariamente applicabili ad altri ospedali con set di dati univoci, i ricercatori ritengono che i nuovi classificatori possano essere costruiti dal modello MoCo con relativamente poche risorse, forse una singola GPU.
“Essere in grado di prevedere se un paziente avrà bisogno di risorse di ossigeno sarebbe anche il primo e potrebbe aiutare gli ospedali a decidere come allocare le risorse nelle settimane e nei mesi a venire. Con i casi di COVID-19 in aumento in tutto il mondo, gli ospedali hanno bisogno di strumenti per prevedere e prepararsi ai picchi imminenti mentre pianificano l’allocazione delle risorse “, ha scritto il team di Facebook in un post sul blog. “Queste previsioni potrebbero aiutare i medici a evitare di mandare a casa i pazienti a rischio troppo presto e aiutare gli ospedali a prevedere meglio la domanda di ossigeno supplementare e altre risorse limitate”.
Una recente ricerca dell’Università di Toronto, del Vector Institute e del MIT ha rivelato che i set di dati radiografici del torace utilizzati per addestrare modelli diagnostici – inclusi MIMIC-CXR e CheXpert – mostrano uno squilibrio, polarizzandoli contro determinati gruppi di genere, socioeconomici e razziali. Le pazienti di sesso femminile soffrono dei livelli di disparità più elevati, anche se la percentuale di donne nel set di dati è solo leggermente inferiore a quella degli uomini. I pazienti bianchi – la maggioranza, con il 67,6% di tutte le immagini radiografiche – sono il sottogruppo più favorito, mentre i pazienti ispanici sono i meno favoriti.
I ricercatori di Facebook e della New York University affermano di aver affrontato questo pregiudizio preparandosi su dati non COVID e selezionando attentamente ogni campione di prova. Ma all’inizio dello scorso anno, i Centri statunitensi per il controllo e la prevenzione delle malattie hanno raccomandato di non utilizzare scansioni TC o raggi X per la diagnosi di COVID-19, così come l’American College of Radiology (ACR) e le organizzazioni radiologiche in Canada, Nuova Zelanda e Australia. Questo perché anche i migliori sistemi di intelligenza artificiale a volte non sono in grado di distinguere tra COVID-19 e infezioni polmonari comuni come la polmonite batterica o virale.
In parte a causa della reticenza a rilasciare codice, set di dati e tecniche, molti dei dati utilizzati oggi per addestrare algoritmi di intelligenza artificiale per la diagnosi delle malattie possono perpetuare le disuguaglianze. Un team di scienziati britannici ha scoperto che quasi tutti i set di dati sulle malattie degli occhi provengono da pazienti in Nord America, Europa e Cina, il che significa che gli algoritmi di diagnosi delle malattie degli occhi hanno meno probabilità di funzionare bene per i gruppi razziali dei paesi sottorappresentati. In un altro studio, i ricercatori della Stanford University hanno affermato che la maggior parte dei dati statunitensi per gli studi che coinvolgono usi medici dell’IA provengono da California, New York e Massachusetts. Uno studio su un algoritmo del gruppo UnitedHealth ha stabilito che potrebbe sottostimare della metà il numero di pazienti neri bisognosi di cure maggiori. E un numero crescente di lavori suggerisce che gli algoritmi di rilevamento del cancro della pelle tendono ad essere meno precisi quando usati su pazienti neri, in parte perché i modelli di intelligenza artificiale sono addestrati principalmente su immagini di pazienti di pelle chiara.
Determinare quanto siano affidabili gli algoritmi di Facebook e della NYU richiederebbe probabilmente test approfonditi presso più sistemi sanitari diversi in tutto il mondo, con il consenso dei pazienti. Uno studio pubblicato su Nature Machine Intelligence ha rivelato che un modello di deterioramento COVID-19 implementato con successo a Wuhan, in Cina, ha prodotto risultati che non erano migliori di un lancio di dadi se applicato a un campione di pazienti a New York. Mentre un’attenta messa a punto potrebbe aiutare l’algoritmo di Facebook e della NYU a evitare lo stesso destino, è impossibile prevedere dove potrebbero sorgere i pregiudizi, il che parla della necessità di audit prima della distribuzione su qualsiasi scala.