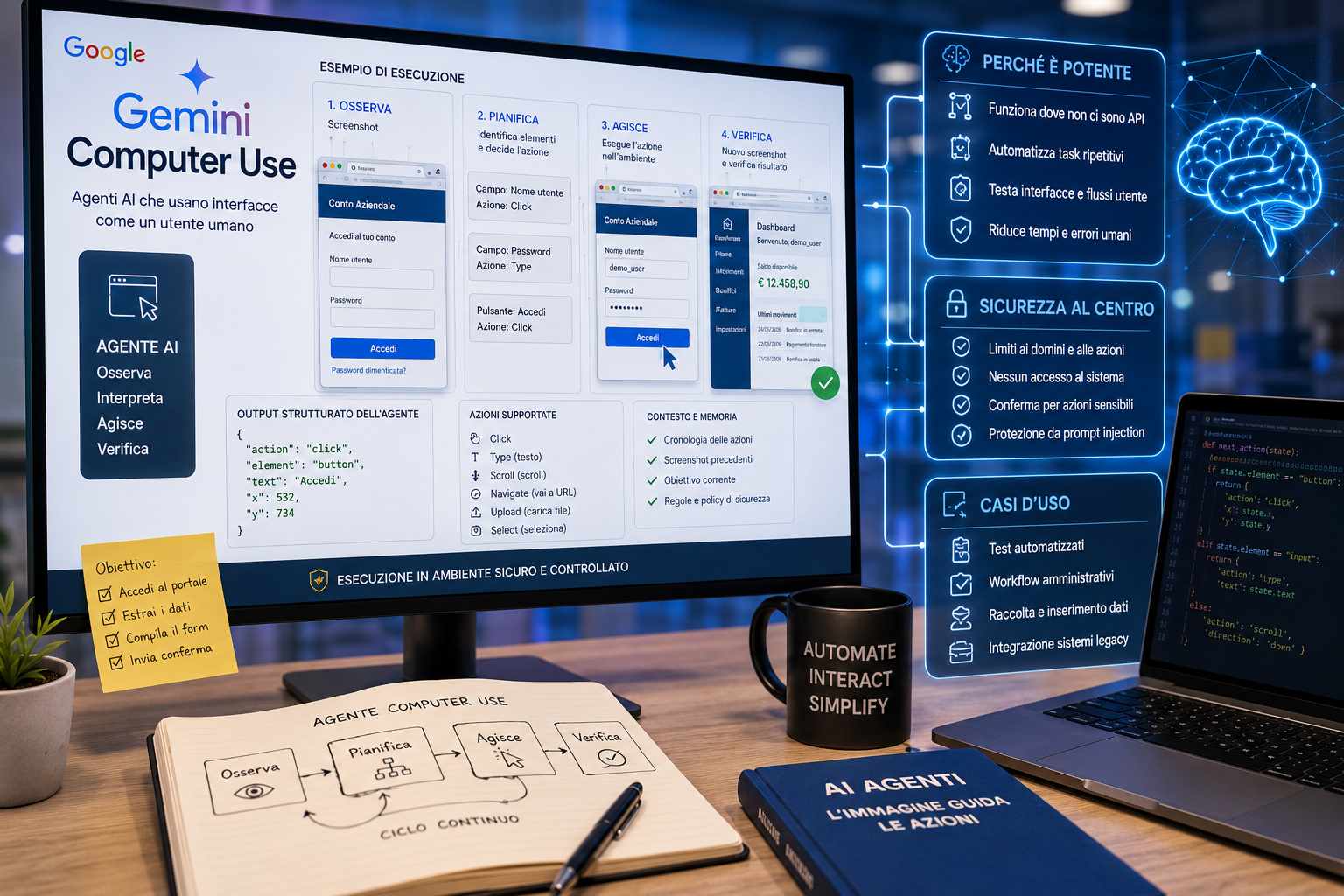
Google ha introdotto Computer Use, una capacità di Gemini pensata per costruire agenti in grado di usare interfacce digitali attraverso lo stesso livello visivo disponibile a un utente umano. Il sistema non opera collegandosi direttamente alla logica interna di un’applicazione né richiede, in ogni caso, API specifiche per ciascun software: osserva lo stato della pagina o della finestra tramite screenshot, interpreta elementi visivi come pulsanti, menu, campi di input e finestre di dialogo, quindi propone una sequenza di azioni da eseguire.
L’architettura è diversa da quella di un chatbot tradizionale. Un modello linguistico riceve una richiesta e restituisce testo; un agente Computer Use deve invece affrontare un ciclo operativo composto da osservazione, pianificazione, azione e verifica. Dopo aver ricevuto uno screenshot e il contesto dell’attività, Gemini identifica la condizione corrente dell’interfaccia, seleziona l’azione successiva, come un clic, l’inserimento di testo, uno scorrimento della pagina o la navigazione verso un indirizzo, e restituisce l’istruzione in un formato strutturato. Il programma che integra l’agente riceve quell’output, esegue fisicamente l’azione nel browser o nell’ambiente controllato e invia un nuovo screenshot al modello, che può verificare il risultato e decidere come proseguire.
Questa modalità rende possibile automatizzare procedure che normalmente non dispongono di API moderne o di integrazioni dirette. Molte attività aziendali richiedono ancora la compilazione di moduli web, l’accesso a portali di fornitori, la consultazione di applicazioni legacy, l’inserimento di dati in sistemi amministrativi, il confronto tra schermate oppure l’esecuzione di test su flussi utente. In questi scenari, l’agente non deve conoscere in anticipo il codice sorgente dell’applicazione, ma deve riconoscere correttamente ciò che appare sullo schermo e mantenere una sequenza coerente di azioni.
Il caso d’uso più immediato è il testing di interfacce. Un agente può ricevere un compito come creare un account di prova, compilare un form, caricare un documento, completare un acquisto simulato o verificare che un messaggio di errore compaia in una specifica condizione. Rispetto ai test basati esclusivamente su selettori HTML o coordinate rigide, l’approccio visuale può risultare più flessibile quando cambiano il layout, la posizione dei controlli o l’aspetto della pagina. Questa flessibilità non elimina però la necessità di validazioni affidabili: il test deve definire quali campi compilare, quali risultati attendersi e quali condizioni indicano un errore.
Computer Use può essere applicato anche a workflow amministrativi, come estrarre informazioni da una schermata, trasferirle in un altro sistema, preparare bozze di documenti o raccogliere dati distribuiti su più portali. In un ambiente produttivo, tuttavia, l’agente deve essere inserito in un perimetro operativo molto definito. Ogni azione può modificare un record, inviare una comunicazione, generare un ordine o attivare una procedura irreversibile; per questo il sistema deve distinguere tra attività informative, azioni reversibili e operazioni che richiedono l’approvazione esplicita di una persona.
La sicurezza è il punto centrale di questa architettura. Un agente che legge il contenuto di una pagina può incontrare istruzioni ostili inserite in testi, documenti, email, pagine web o immagini. Una pagina potrebbe tentare di convincere il modello a ignorare il compito assegnato, rivelare dati o compiere azioni non richieste. Questo tipo di attacco viene definito prompt injection indiretta, perché l’istruzione malevola non arriva dall’utente autorizzato ma dal contenuto osservato durante la navigazione.
Per ridurre il rischio, il modello deve essere affiancato da controlli esterni. Il client che esegue le azioni può limitare i domini raggiungibili, bloccare il download di file, impedire l’accesso a impostazioni di sistema, separare le credenziali per ambiente, applicare limiti alle azioni consecutive e richiedere conferme prima di operazioni come acquisti, trasferimenti di denaro, invio di moduli, pubblicazione di contenuti o modifica di dati sensibili. Il modello prende decisioni sull’interfaccia, ma l’ambiente di esecuzione deve mantenere l’autorità sulle operazioni consentite.
Un altro elemento tecnico rilevante è la gestione dello stato. In un processo multi-step, Gemini deve ricordare che cosa ha già fatto, distinguere tra una pagina caricata correttamente e una schermata inattesa, gestire errori temporanei, riconoscere richieste di autenticazione e capire quando il compito è concluso. Per questo Computer Use non coincide con un singolo comando di automazione, ma richiede un orchestratore che conservi cronologia, screenshot, risultati intermedi, policy di sicurezza e criteri di successo.
La capacità di usare un’interfaccia come un operatore umano amplia il raggio d’azione dell’AI generativa, ma non rende l’agente automaticamente adatto a ogni processo. Le applicazioni più solide sono quelle in cui il compito è ben delimitato, l’ambiente è controllato, l’esito è verificabile e gli effetti delle azioni possono essere monitorati. In questo modello, Gemini non sostituisce le regole applicative o i sistemi aziendali esistenti: agisce come un livello di percezione e interazione capace di collegare istruzioni in linguaggio naturale e schermate software, sotto il controllo delle policy definite dall’organizzazione.