
analizzare i dati di twitter
Twitter è una grande fonte di notizie al giorno d’oggi perché è la fonte più completa di conversazioni pubbliche in tutto il mondo. Le ultime notizie che potrebbero non essere disponibili sui canali di notizie o sui siti Web, ma potrebbero essere di tendenza su Twitter tra le conversazioni pubbliche. Qualsiasi informazione, nonostante sia costruttiva o distruttiva, può essere facilmente diffusa attraverso la rete di Twitter saltando i tagli o le normative editoriali.
A causa di questa natura di Twitter, è anche popolare tra gli analisti di dati che vogliono raccogliere alcune informazioni di tendenza ed eseguire analisi. In questo articolo, impareremo a scaricare e analizzare i dati di Twitter. Impareremo come ottenere tweet correlati a una parola chiave interessante, come pulire, analizzare, visualizzare quei tweet e infine come convertirlo in un frame di dati e salvarlo in un file CSV.
Qui discuteremo un approccio pratico per scaricare e analizzare i dati di Twitter. Importeremo qui tutte le librerie richieste. Assicurati di installare le librerie ‘tweepy’, ‘ textblob ‘ e ‘ wordcloud ‘ usando ‘ pip install tweepy ‘, ‘ pip install textblob ‘ e ‘ pip install wordcloud ‘.
Importing Libraries
import tweepy
from textblob import TextBlob
import panda as
import pp numpy as np
import matplotlib.pyplot as plt
import re
import nltk
nltk.download (‘stopwords’)
da nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from wordcloud importa WordCloud
importa json
dalle collezioni import Counter
Download dei dati da Twitter
Per utilizzare l’ API ‘ tweepy ‘, devi creare un account con Twitter Developer. Dopo aver creato l’account, vai all’opzione “Inizia” e vai all’opzione “Crea un’app”. Dopo aver creato l’app, non in basso le credenziali richieste di seguito da lì.
Authorization e Ricerca tweets
Getting autorizzazione
consumer_key = ‘XXXXXXXXXXXXXXX’
consumer_key_secret = ‘XXXXXXXXXXXXXXX’
access_token = ‘XXXXXXXXXXXXXXX’
access_token_secret = ‘XXXXXXXXXXXXXXX’
auth = tweepy.OAuthHandler (consumer_key, consumer_key_secret)
auth.set_access_token (access_token, access_token_secret)
API = tweepy. API (auth, wait_on_rate_limit = True)
Puoi passare qui la parola chiave di tuo interesse e il numero massimo di tweet da scaricare tramite l’ API tweepy .
Definizione della parola chiave di ricerca e numero di tweet e ricerca di tweet
query = ‘lockdown’
max_tweets = 2000earch_tweets
= [status for status in tweepy.Cursor (api.search, q = query) .items (max_tweets)]
Analizzeremo ora i sentimenti dei tweet che abbiamo scaricato e li visualizzeremo qui.
Analisi del sentimento
Sentiment Analysis Report
Finding Analisi del sentiment (+ ve, -ve e neutral)
pos = 0
neg = 0
neu = 0
per il tweet nei
motori di
ricerca: analysis = TextBlob (tweet.text) se analysis.sentiment [0]> 0:
pos = pos +1
elif analysis.sentiment [0] <0:
neg = neg + 1
altro:
neu = neu + 1
stampa (“Total Positive =”, pos)
print (“Total Negative =”, neg)
print (“Total Neutral = “, neu)
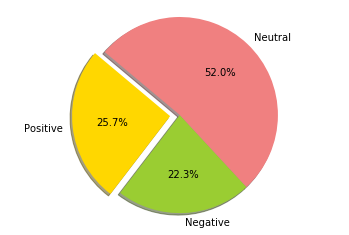
Plotting sentiments
labels = ‘Positive’, ‘Negative’, ‘Neutral’
dimensioni = [257, 223, 520]
colors = [‘gold’, ‘yellowgreen’, ‘lightcoral’]
explode = (0.1, 0, 0) # esplodere prima fetta
plt.pie (dimensioni, esplodere = esplodere, etichette = etichette, colori = colori, autopct = ‘% 1.1f %%’, ombra = True, startangle = 140)
plt.axis (‘uguale’)
plt.show ()
analisi dei dati di twitter; analisi del sentimento
Qui, creeremo un frame di dati di tutti i dati di tweet che abbiamo scaricato. Successivamente tutti i dati elaborati verranno salvati in un file CSV nel sistema locale. In questo modo, possiamo utilizzare questi dati di tweet per altri scopi sperimentali .
Creazione del frame di dati e salvataggio nel file CSV
Creazione di un frame di dati di tweet # Pulizia di tweet
cercati e conversione in un frame di dati
my_list_of_dicts = []
per each_json_tweet in
seek_tweets : my_list_of_dicts.append (each_json_tweet._json)
con open (‘tweet_json_Data.txt’, ‘w’) come file:
file.write (json.dumps (my_list_of_dicts, indent = 4))
my_demo_list = []
con open (‘tweet_json_Data.txt’, encoding = ‘utf-8’) come json_file:
all_data = json.load (json_file)
per each_dictionary in all_data:
tweet_id = each_dictionary [‘id’]
text = each_dictionary [‘ text ‘]
favorite_count = each_dictionary [‘ favorite_count ‘]
retweet_count = each_dictionary [‘ retweet_count ‘]
Created_at = each_dictionary [‘
Created_at
‘] my_demo_list.append ({‘ tweet_id ‘: str (tweet_id), ‘ text ‘: str (testo), str
‘favorite_count’: int (favorite_count),
‘retweet_count’: int (retweet_count),
‘Created_at’: Created_at,
})
tweet_dataset = pd.DataFrame (my_demo_list, colonne = [‘tweet_id’, ‘text’, ‘favorite_count’, ‘retweet_count’, ‘Created_at’])
#Writing set di dati tweet per file CSV per riferimento futuro
tweet_dataset.to_csv (‘tweet_data.csv’)
Pulizia di testi Tweet tramite operazioni NLP
Dato che ora siamo pronti con il set di dati tweet, analizzeremo il nostro set di dati e puliremo questi dati nei seguenti segmenti.
tweet_dataset.shape
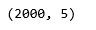
forma dei dati di twitter
tweet_dataset.head ()

tweets
Cleaning Data
Removing @ handle
def remove_pattern (input_txt, pattern):
r = re.findall (pattern, input_txt)
per i in r:
input_txt = re.sub (i, ”, input_txt)
restituisce input_txt
tweet_dataset [‘text’] = np.vectorize (remove_pattern) (tweet_dataset [‘text’], “@ [\ w] *”)
tweet_dataset.head ()

dati tweet
tweet_dataset [ ‘testo’]. Testa ()

dati tweet
Qui, mentre siamo pronti con i dati puliti del tweet, eseguiremo operazioni di PNL sui testi del tweet incluso prendere solo alfabeti, convertire tutto in lettere minuscole, tokenizzazione e stemming. Poiché nei tweet sono presenti retweet, ipertesti, ecc., È necessario rimuovere tutte quelle informazioni non necessarie.
Cleaning Tweets
corpus = []
per i nell’intervallo (0, 1000):
tweet = re.sub (‘[^ a-zA-Z0-9]’, ”, tweet_dataset [‘text’] [i])
tweet = tweet.lower ()
tweet = re.sub (‘rt’, ”, tweet)
tweet = re.sub (‘http’, ”, tweet)
tweet = re.sub (‘https’, ”, tweet )
tweet = tweet.split ()
ps = PorterStemmer ()
tweet = [ps.stem (parola) per parola in tweet se non parola in set (stopwords.words (‘inglese’))]
tweet = ” .join (tweet )
corpus.append (tweet)
Ora, dopo aver eseguito le operazioni NLP, visualizziamo le parole più frequenti nei tweet attraverso una nuvola di parole e usando il termine frequenza.
Visualizzazione delle parole più alte che si verificano utilizzando Word Cloud
Visualization
Word Cloud
all_words = ” .join ([testo per testo in corpus])
wordcloud = WordCloud (larghezza = 800, altezza = 500, random_state = 21, max_font_size = 110) .generate (all_words)
plt.figure (figsize = (10, 7))
plt.imshow (wordcloud, interpolazione = “bilineare”)
plt.axis (‘off’)
plt.show ()
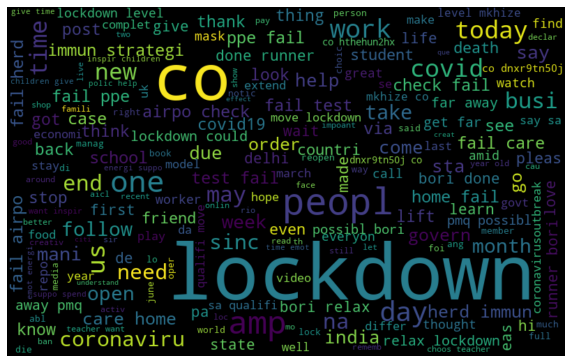
nuvola di parole tweet
Analisi della frequenza dei termini con le parole più alte che si verificano
Term Freuency – TF-IDF
da sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer (max_df = 0.90, min_df = 2, max_features = 1000, stop_words = ‘inglese’)
tfidf = tfidf_vectoret’d_fformas ” tfidf ”
Conta le
parole più frequenti Counter = Counter (corpus) most_occur = Counter.most_common (10)
print (most_occur)

frequenza del termine tweet
Soprattutto i termini più frequenti sono comparsi nei dati del tweet. Quindi, questo è il modo in cui possiamo scaricare i tweet, pulire quei tweet, convertirli in frame di dati, salvarli in file CSV e, infine, analizzare quei tweet.