La crescita dell’utilizzo dei modelli linguistici sta portando molte aziende a confrontarsi con un problema sempre più rilevante: il costo associato all’elaborazione dei token. Mentre gran parte dell’attenzione del settore continua a concentrarsi sulle prestazioni dei modelli e sulle dimensioni delle finestre di contesto, un progetto open source chiamato Headroom propone un approccio differente, intervenendo direttamente sulla quantità di dati trasmessi ai sistemi di intelligenza artificiale.
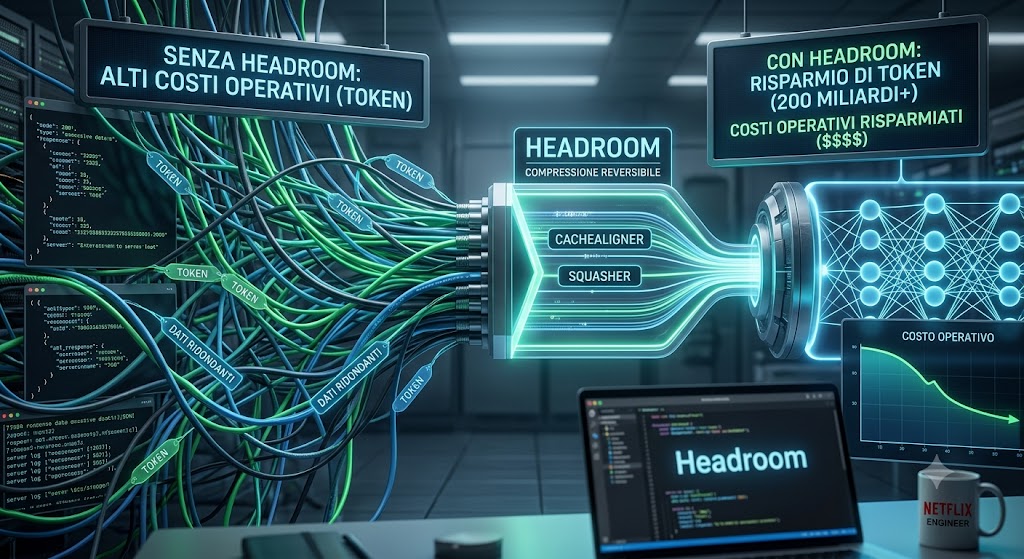
Il progetto è stato sviluppato da Tejas Chopra, Senior Engineer di Netflix, con l’obiettivo di ridurre il volume di informazioni che raggiungono i modelli linguistici durante le attività quotidiane di sviluppo software, analisi dati e automazione. Secondo i dati condivisi dal progetto, la comunità che utilizza Headroom avrebbe già risparmiato circa 200 miliardi di token, traducibili in centinaia di migliaia di dollari di costi operativi evitati.
L’origine del progetto nasce dall’osservazione di un fenomeno sempre più diffuso nei sistemi AI moderni. In numerosi casi il problema non è rappresentato dai prompt scritti dagli utenti, ma dall’enorme quantità di metadati e informazioni di contesto che vengono aggiunti automaticamente dagli strumenti software. Strutture JSON particolarmente verbose, risposte API complesse, log applicativi, descrizioni dei database e dati provenienti da sistemi RAG possono aumentare enormemente il numero di token elaborati senza apportare un reale beneficio al risultato finale.
Headroom affronta questa situazione operando come proxy tra l’applicazione e il modello linguistico. Prima che i dati vengano inviati all’LLM, il sistema analizza il contenuto e applica diverse tecniche di ottimizzazione progettate per ridurre la quantità di informazioni ridondanti mantenendo il contesto essenziale necessario all’elaborazione.
Uno dei componenti principali della piattaforma è CacheAligner. Questo modulo confronta il nuovo input con le informazioni già note al modello e trasmette soltanto le parti che risultano effettivamente modificate. In questo modo viene eliminata la necessità di reinviare continuamente porzioni di contesto che non hanno subito variazioni, riducendo significativamente il volume dei dati elaborati.
La piattaforma utilizza inoltre compressori specializzati in funzione del tipo di contenuto trattato. Codice sorgente, strutture JSON, dati web e output provenienti da strumenti differenti vengono analizzati mediante algoritmi ottimizzati per ciascuna categoria. Questo approccio consente di ottenere livelli di compressione superiori rispetto alle tecniche generiche utilizzate normalmente nei sistemi di gestione del contesto.
Particolarmente interessante è il componente denominato Squasher. Il sistema utilizza tecniche statistiche per individuare quali informazioni risultano realmente importanti durante l’interazione con il modello. Attraverso l’osservazione delle richieste successive, Headroom apprende quali dati vengono recuperati più frequentemente e adatta progressivamente il livello di compressione in funzione dell’utilizzo reale.
A differenza di altre soluzioni che eliminano semplicemente le informazioni considerate meno rilevanti, Headroom adotta una strategia di compressione reversibile. I dati compressi vengono infatti conservati separatamente e collegati a riferimenti che permettono il recupero delle informazioni originali qualora il modello ne abbia bisogno durante le fasi successive dell’elaborazione. Questo meccanismo punta a mantenere l’accuratezza delle risposte pur riducendo sensibilmente il numero di token elaborati.
Le applicazioni pratiche risultano particolarmente evidenti in alcuni contesti. Nel caso dei log applicativi e dei log server, il sistema è in grado di eliminare grandi quantità di informazioni duplicate o poco significative. Analogamente, nelle strutture JSON generate da API e strumenti MCP, una parte consistente dei dati trasmessi può essere compressa senza compromettere il contenuto informativo realmente necessario ai modelli linguistici.
L’interesse verso tecnologie di questo tipo è legato non soltanto alla riduzione dei costi. Diversi studi hanno infatti evidenziato come l’eccessiva lunghezza del contesto possa influire negativamente sulle prestazioni dei modelli. Quando il volume delle informazioni cresce oltre determinate soglie, aumenta la probabilità che il modello perda elementi rilevanti o attribuisca maggiore importanza alle informazioni presenti all’inizio e alla fine del contesto, riducendo l’efficacia complessiva dell’elaborazione.
La diminuzione del numero di token contribuisce inoltre a migliorare la velocità di risposta e a ridurre il carico computazionale richiesto dai modelli. Questo aspetto assume particolare importanza nelle applicazioni in tempo reale, nei sistemi vocali e nei servizi che devono elaborare grandi volumi di richieste contemporaneamente.
Con la diffusione sempre più ampia degli agenti AI e delle applicazioni basate su modelli linguistici di grandi dimensioni, Headroom rappresenta un esempio di come l’innovazione possa concentrarsi non soltanto sull’aumento delle capacità dei modelli, ma anche sull’ottimizzazione dell’intera catena di elaborazione. Ridurre la quantità di dati inutili trasmessi ai sistemi di intelligenza artificiale potrebbe infatti diventare un elemento fondamentale per contenere costi, consumi energetici e tempi di risposta nelle future infrastrutture AI.