Facebook AI Research (FAIR) ha pubblicato un documento di ricerca che introduce Hidden Unit BERT (HuBERT), il loro ultimo approccio per l’apprendimento delle rappresentazioni vocali auto-supervisionate . Secondo FAIR, le tecniche auto-supervisionate per il riconoscimento vocale sono attualmente limitate a causa di tre fattori: primo, la presenza di più unità sonore in ciascuna enunciazione in ingresso; in secondo luogo, l’assenza di lessici delle unità sonore in ingresso durante la fase di pre-formazione; e, infine, l’osservazione che le unità sonore hanno lunghezze variabili senza segmentazione esplicita.
Per affrontare questo problema, HuBERT utilizza un algoritmo di clustering k-means offline e apprende la struttura del suo input (parlato) prevedendo il cluster giusto per i segmenti audio mascherati. FAIR afferma che la semplicità e la stabilità di HuBERT lo rendono facilmente implementabile per casi d’uso in PNL e ricerca vocale.
HuBERT si ispira al metodo DeepCluster di FAIR per l’apprendimento visivo auto-supervisionato. DeepCluster è un metodo di clustering introdotto nel 2018 che apprende i parametri di una rete neurale e la loro assegnazione di cluster, dopodiché raggruppa queste funzionalità utilizzando un algoritmo di clustering standard, chiamato k-means. HuBERT beneficia ulteriormente delle rappresentazioni dell’encoder bidirezionale dei trasformatori ( BERT ) di Google sfruttando il suo metodo di perdita di previsione mascherata sulle sequenze per mostrare la natura sequenziale del parlato. Un modello BERT utilizza funzioni vocali continue mascherate per prevedere assegnazioni di cluster predeterminate. Questa perdita predittiva viene applicata solo sulle regioni mascherate, consentendo al modello di apprendere rappresentazioni di alto livello di input non mascherati per dedurre correttamente i target delle aree mascherate.
Come funziona HuBERT?
Il modello HuBERT apprende modelli acustici e linguistici da questi input continui. Per questo, il modello prima codifica gli ingressi audio non mascherati in rappresentazioni latenti continue significative. Queste rappresentazioni mappano il problema della modellazione acustica classica. Il modello utilizza quindi l’apprendimento della rappresentazione tramite la previsione mascherata.
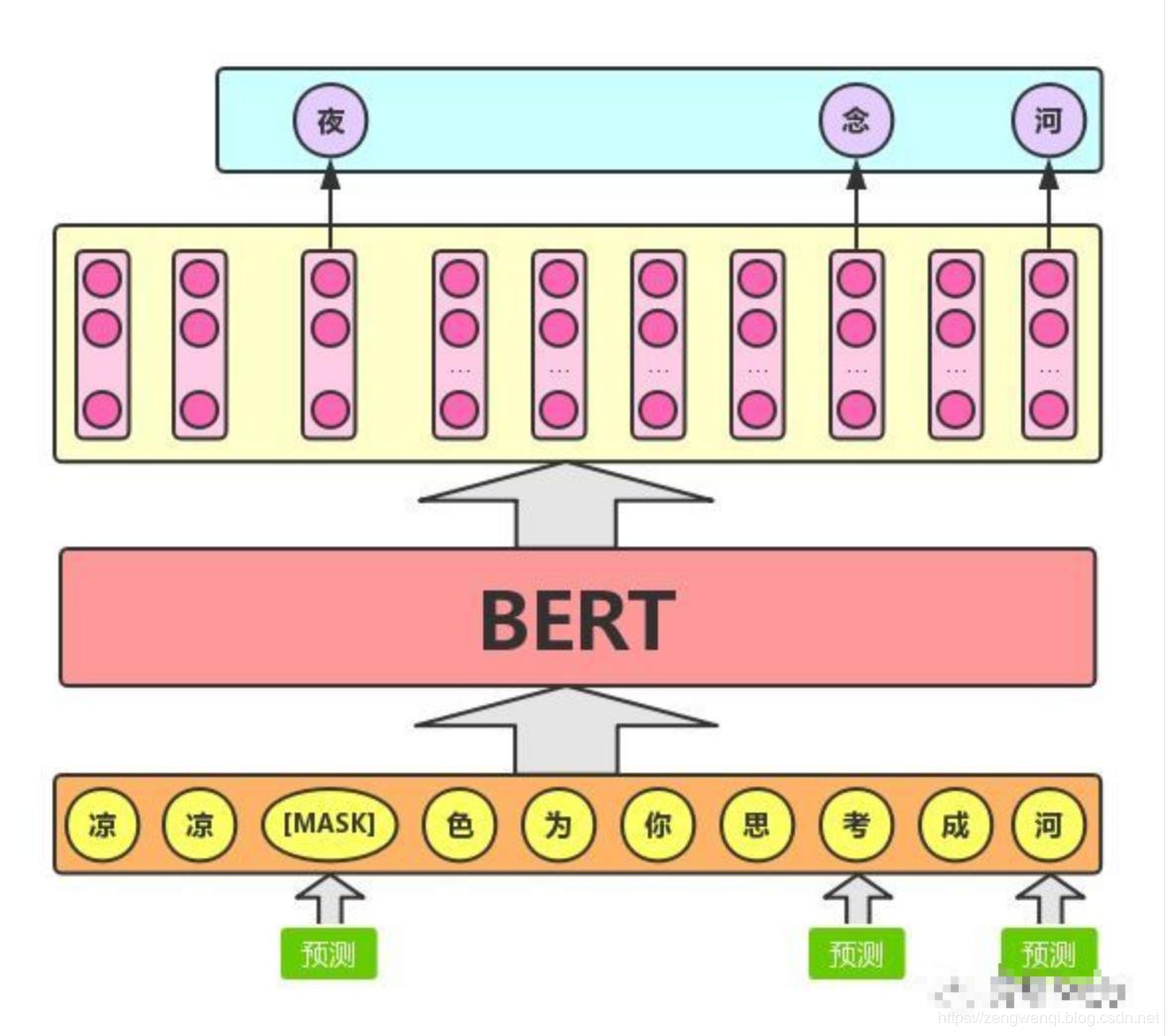
L’approccio HuBERT che prevede le assegnazioni di cluster nascosti dei frame mascherati (MSK) y2, y3, y4 / Fonte: Facebook AI Research
Il modello cerca di ridurre l’errore di previsione catturando le relazioni temporali a lungo raggio tra le rappresentazioni che ha appreso. Qui, la coerenza della mappatura dei k-means dagli input audio ai target discreti è importante quanto la loro correttezza poiché consente al modello di concentrarsi sulla modellazione della struttura sequenziale dei dati di input. Ad esempio, se una prima espressione di clustering non può distinguere i suoni /k/ e /g/, porterebbe a un singolo superammasso contenente entrambi questi suoni. La perdita di previsione apprenderà quindi rappresentazioni che modellano il modo in cui altri suoni di consonanti e vocali funzionano con questo superammasso durante la formazione delle parole. Attraverso questa rappresentazione appena appresa, l’iterazione del clustering creerà cluster migliori.
Implementazione di HuBERT
FAIR ha pre-addestrato HuBERT sulle ore standard di LibriSpeech 960 e su Libri-Light 60.000 ore e ha scoperto che il modello corrispondeva o migliorava le prestazioni di AI wav2vec 2.0 di riconoscimento vocale all’avanguardia di Facebook su sottoinsiemi di messa a punto di 10 minuti , 1 ora, 10 ore, 100 ore e 960 ore. Gli esperimenti sono stati condotti utilizzando due modelli di HuBERT: HuBERT L-LV60k e HuBERT XL-LV60k.
Facebook AI Research ha anche testato le prestazioni di HuBERT nella generazione del linguaggio, che è essenziale per la modellazione diretta del linguaggio dei segnali vocali senza fare affidamento su risorse lessicali come le etichette supervisionate.
Utilizzando il Generative Spoken Learning Modeling (GSLM), che implica l’apprendimento delle caratteristiche acustiche e linguistiche di una lingua senza testo o etichette, Facebook ha iniziato a utilizzare rappresentazioni del parlato apprese per sintetizzare il parlato da modelli come Contrastive Predictive Coding (CPC), Wav2Vec2.0 e HuBERT . HuBERT, sia in valutazioni automatiche che umane, ha generato campioni in grado di competere in termini di qualità con LogMel (LM) basato sui caratteri supervisionato di prima linea.
Infine, FAIR ha anche testato HuBERT utilizzando il test MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA), che conduce un test di ascolto del codec per valutare la qualità dell’output da algoritmi di compressione audio con perdita. Qui, HuBERT è arrivato secondo solo all’audio non compresso.
Molte piattaforme di riconoscimento vocale basate sull’intelligenza artificiale hanno lavorato per comprendere e riconoscere il parlato semplicemente attraverso l’ascolto e l’interazione e senza etichette. Ad esempio, Facebook AI Research ha recentemente lanciato un’intelligenza artificiale che comprendeva il parlato senza testo etichettato. Il gigante della tecnologia ha anche reso pubblico il suo più grande database linguistico per facilitare lo sviluppo di strumenti di riconoscimento vocale, concentrandosi esplicitamente su lingue come lo swahili, dove i dati etichettati sono scarsi.
Con HuBERT, afferma Facebook, la comunità di ricerca sull’intelligenza artificiale può sviluppare sistemi di elaborazione del linguaggio naturale (NLP) che potrebbero addestrare tramite audio anziché campioni di testo. Ciò consentirà agli assistenti vocali di intelligenza artificiale di catturare l’espressività del linguaggio orale e parlare con le sfumature e gli stili di una persona reale che parla la lingua. Tale tecnologia consentirà alle persone che parlano lingue o dialetti rari o lingue con una letteratura più limitata di altre di beneficiare di applicazioni di riconoscimento vocale e traduzione più inclusive.