Questi database di grafici open source sono dotati di prestazioni, scalabilità e integrabilità elevate.
La comprensione della maggior parte dei domini richiede l’elaborazione di grandi insiemi di connessioni insieme a valori individuali. Insieme ai fornitori di servizi finanziari, anche i social network, le reti di pagamento o le reti stradali dipendono dalla comprensione delle relazioni tra i valori individuali per stabilire motori di raccomandazione e rilevare le frodi.
È qui che viene evidenziata l’importanza dei database di grafi poiché utilizzano modelli di dati topografici per archiviare i dati. Memorizzano nodi e relazioni invece di documenti o tabelle. L’attraversamento di nodi, join e relazioni è molto più veloce della valutazione dei valori individuali.
Ecco un elenco di 9 database di grafici open source per casi d’uso NoSQL.
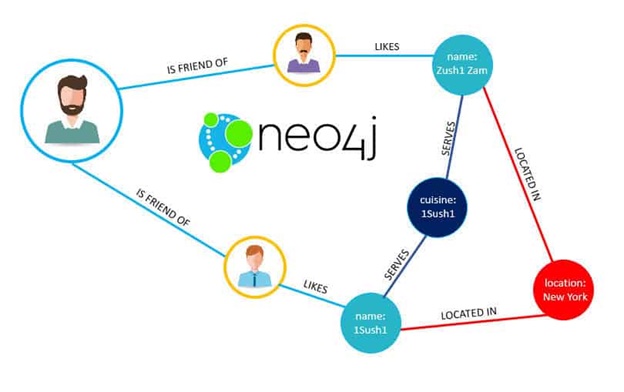
1 Neo4j
Uno dei percorsi più utilizzati e veloci per creare grafici, Neo4j , è il principale spazio di lavoro di analisi per i dati dei grafici. La libreria open source di data science per i grafici include uno strumento di esplorazione chiamato “Bloom”, che è un linguaggio di query Cypher molto facile da imparare.
Neo4j archivia i dati interconnessi in modo nativo per una più facile decifrazione e quindi semplificare alle organizzazioni lo sviluppo e l’evoluzione dei modelli di apprendimento automatico. Supporta anche query di grafici ad alte prestazioni per set di dati di grandi dimensioni.
2 ArangoGraph
ArangoGraph, creato da ArangoDB , consente di scoprire il difficile database SQL tradizionale risultando in una guida più semplice del valore dai dati connessi più velocemente. È la spina dorsale di molte imprese e startup di Fortune 500 in settori come l’assistenza sanitaria, le telecomunicazioni e i servizi finanziari.
Il database viene fornito con grafici facilmente comprensibili per dimostrare le API. È un database multimodello scalabile e open source per la massima flessibilità su qualsiasi cloud.
3 RedisGraph
Sviluppato da RedisLabs , RedisGraph è sviluppato da zero su Redis e con l’aiuto dell’API Redis Modules con comandi e capacità estesi. Memorizza i dati nella RAM per essere efficiente in termini di memoria e velocizzare l’indicizzazione e l’esecuzione di query. Utilizza il linguaggio di query del grafico openCypher.
Teoricamente, RedisGraph utilizza matrici di adiacenza sparse per rappresentare i grafici che gli consentono di aggiungere nuovi nodi ed estendere le matrici. Può creare oltre 1 milione di nodi in mezzo secondo e formare 500.000 relazioni in 0,3 secondi.
4 Dgraph
Con oltre 500.000 download ogni mese da GitHub, Dgraph è uno dei database GraphQL più avanzati per prestazioni elevate e scalabilità. Restituisce terabyte di dati entro millisecondi. Senza richiedere alcun codice, il modulo ti consente di creare schemi personalizzati sulle tue applicazioni con accesso istantaneo a database e API.
Gli utenti possono importare e trasmettere facilmente i dati su Dgraph e ridimensionarli senza problemi con bassa latenza, anche con enormi quantità di dati. Inoltre, con Dgraph Lambda, puoi creare una logica personalizzata in JavaScript che è eseguibile invocando una mutazione o una query.
5 FaunaDB
Fornito come API cloud, FaunaDB è un database relazionale di documenti distribuito. Può integrare perfettamente le applicazioni esistenti su di esso senza ridimensionamento o operazioni. Combina la coerenza ACID dei sistemi SQL con la flessibilità di NoSQL. Consente alle organizzazioni di eseguire centralmente sofisticate logiche di business.
L’idea di non doversi preoccupare delle operazioni rende più facile per gli utenti ridimensionarlo senza dover gestire server, partizionamento dei dati o cluster. Funziona con piattaforme cloud come AWS, Azure, Google, Cloudflare e può essere integrato con piattaforme front-end come Netlify e Vercel.
6 GraphDB
Un prodotto di Ontotext, GraphDB consente di collegare diversi set di dati, indicizzarli per la ricerca semantica e arricchirli tramite l’analisi del testo per costruire grafici di conoscenza di grandi dimensioni. Oltre ad essere un database RDF, può anche essere collegato con plug-in aggiuntivi come Elasticsearch, Solr e Lucene. Consente inoltre al connettore Kafka di sincronizzare i dati con i sistemi a valle.
GraphDB utilizza hardware minimo e massimizza l’utilizzo dei nodi oltre a prevenire la perdita di dati e gli errori con l’algoritmo di consenso Raft. È anche facilmente implementabile da qualsiasi luogo utilizzando Java.
7 RDFox
Costruito da Oxford Semantic Technologies. RDFox acquisisce i dati in formato RDF-triplo che semplifica la conversione in sorgenti SQL o CSV. La piattaforma cloud consente agli utenti di operare al volo con un’elevata scalabilità e senza vincoli di memoria su qualsiasi dispositivo. Supporta il ragionamento parallelo della memoria per RDF, RDFS, Datalog e OWL 2 RL.
RDFox può essere utilizzato per il rilevamento di modelli complessi, il ragionamento semantico, l’integrazione dei dati e la creazione di grafici della conoscenza. È scritto su C++ e viene fornito con supporto multipiattaforma come il wrapper Java.
8 Aerospike
La piattaforma dati multimodello, Aerospike, è un multi-cloud NoSQL per casi d’uso JSON su larga scala. È utilizzato da aziende come Airtel, Yahoo e Snap Inc., tra le altre, per il suo massiccio parallelismo e un modello di memoria ibrido. La piattaforma cloud può elaborare terabyte o petabyte di dati in pochi minuti, fornendo una latenza minima.
Aerospike includeva un supporto Flash ottimizzato che aiuta a gestire i set di dati con linguaggi come Python e Go. È un puro archivio di valori chiave, il che significa che può memorizzare diversi tipi di valori chiave per strutturare elenchi, set, array di bit e hash.
9 Titan
Un database transazionale che supporta migliaia di utenti simultanei e contiene miliardi di vertici e bordi distribuiti su cluster multi-macchina: Titan supporta ACID e l’eventuale coerenza. Per il back-end, supporta Apache Cassandra , Oracle BerkeleyDB, Apache HBase.
Titan supporta anche l’integrazione nativa con TinkerPop e il supporto per la ricerca geografica, numerica e full-text con l’aiuto di ElasticSearch, Solr e Lucene. Tutte queste caratteristiche consentono al database di essere altamente efficiente, estremamente tollerante ai guasti e fornire prestazioni elevate.