Nelle applicazioni di visione artificiale, l’attenzione viene applicata insieme alle CNN o utilizzata per sostituire alcuni componenti di queste reti convoluzionali mantenendo la loro struttura complessiva in posizione. Ma le architetture convoluzionali rimangono ancora dominanti.
La scorsa settimana, un documento in fase di revisione in doppio cieco per ICLR 2021 ha entusiasmato la comunità ML. Il documento intitolato “Un’immagine vale 16X16 parole” è stato discusso da artisti del calibro del capo di Tesla AI, Andrej Karpathy , tra molti altri.
Sin dal seminale articolo “L’attenzione è tutto ciò di cui hai bisogno”, i trasformatori hanno riacceso l’interesse per i modelli linguistici. Sebbene l’architettura del trasformatore sia diventata la soluzione ideale per molte attività di elaborazione del linguaggio naturale, le sue applicazioni per la visione artificiale rimangono limitate.
I trasformatori stanno lentamente diventando popolari con compiti diversi come il riconoscimento vocale, la matematica simbolica e persino l’apprendimento per rinforzo.
Nell’ultimo lavoro in esame all’ICLR 2021, gli autori anonimi affermano che i loro risultati mostrano che il trasformatore di visione può andare in punta di piedi con i modelli all’avanguardia sui benchmark di riconoscimento delle immagini, raggiungendo precisioni fino all’88,36% su ImageNet e 94,55 % su CIFAR-100.
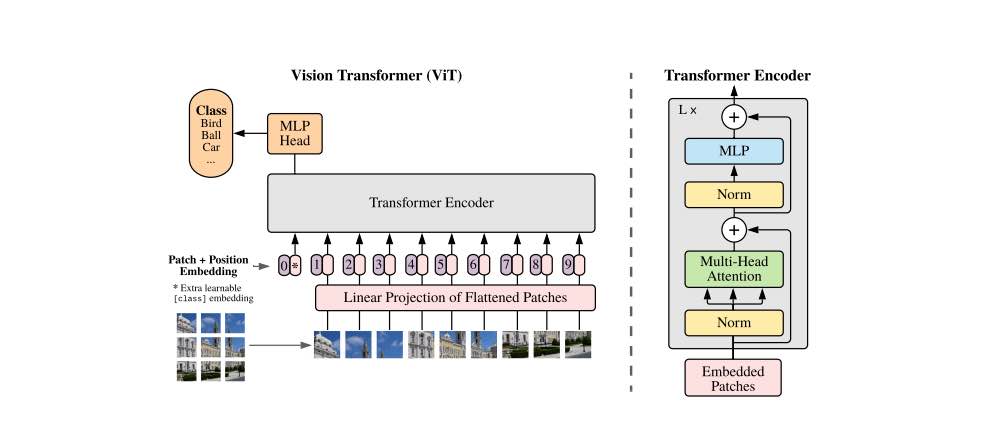
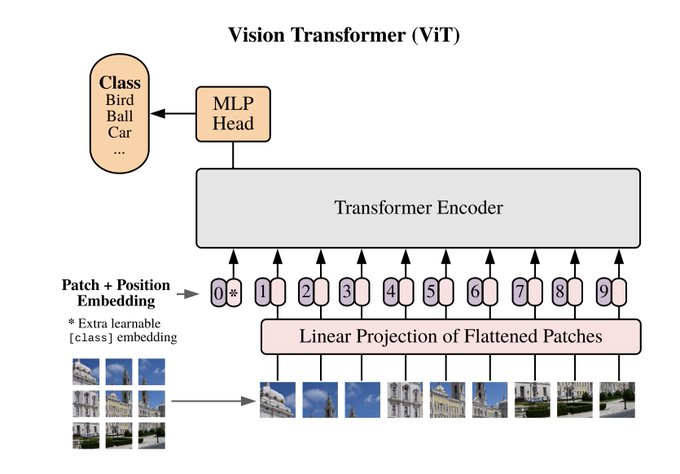
Panoramica dei trasformatori visivi
Il trasformatore di visione, come illustrato sopra, riceve input come sequenza unidimensionale di token embedding. Per gestire le immagini 2D, l’immagine viene rimodellata in una sequenza di patch 2D appiattite. Gli autori affermano che i trasformatori in questo lavoro utilizzano larghezze costanti attraverso tutti i suoi strati, per fornire una proiezione lineare addestrabile che mappa ogni patch vettorializzata alla dimensione del modello che a sua volta porta a incorporamenti di patch.
Questi incorporamenti di patch vengono combinati con incorporamenti posizionali per conservare le informazioni sulla posizione. Gli incorporamenti congiunti vengono inviati come input all’encoder. Gli autori hanno anche consigliato un’architettura ibrida dove invece di dividere l’immagine in patch, è divisa in mappe di caratteristiche intermedie di un modello ResNet.
Procedura:
L’immagine viene suddivisa in patch di dimensioni fisse.
Le patch sono incorporate linearmente.
Gli incorporamenti di posizione vengono aggiunti alla sequenza di vettori risultante.
Le patch vengono inviate a un encoder trasformatore standard.
Un “gettone di classificazione” apprendibile extra viene aggiunto alla sequenza per eseguire la classificazione.
Gli autori hanno valutato le capacità di apprendimento della rappresentazione su tre modelli: ResNet, Vision Transformer (ViT) e l’ibrido. I modelli vengono pre-addestrati su set di dati di dimensioni variabili e valutano molte attività di benchmark.
Set di dati utilizzati: set di dati ImageNet ILSVRC-2012 con classi 1k e immagini 1.3M.
Il modello addestrato su questo set di dati viene quindi convalidato su attività di benchmark su CIFAR -10/100, Oxford-IIIT Pets ecc.
La tabella sopra mostra come con lo stato dell’arte sui benchmark dei set di dati di classificazione delle immagini popolari. Il primo punto di confronto è Big Transfer (BiT), che esegue l’apprendimento del trasferimento supervisionato con ResNets di grandi dimensioni. Il secondo è Noisy Student, che è un grande EfficientNet addestrato utilizzando l’apprendimento semi-supervisionato su ImageNet e JFT-300M con le etichette rimosse.
Tutti i modelli sono stati addestrati su hardware TPUv3 e il numero di giorni TPUv3 necessari per il pre-addestramento può essere visualizzato in fondo alla tabella.
Quando si considera il costo computazionale del pre-addestramento del modello, il documento afferma che ViT si comporta in modo molto favorevole, raggiungendo lo stato dell’arte di gran lunga sulla maggior parte dei benchmark di riconoscimento.
Il modello ViT più piccolo corrisponde o supera BiT-L su tutti i set di dati mentre richiede risorse di calcolo sostanzialmente inferiori per l’addestramento. Considerando che, la modalità più grande migliora ulteriormente le prestazioni su ImageNet e CIFAR-100.
Punti chiave
Vision Transformer corrisponde o supera lo stato dell’arte su molti set di dati di classificazione delle immagini, pur essendo relativamente economico da pre-addestrare.
Gli esperimenti iniziali mostrano miglioramenti rispetto al pre-training autogestito, ma c’è ancora un grande divario tra pre-training autoguidato e supervisionato su larga scala
Gli autori concludono che il rilevamento e la segmentazione sono alcune delle sfide che vorrebbero esplorare. Tuttavia, ci sono stati lavori precedenti in cui vengono realizzati trasformatori per rilevare oggetti. Facebook ha recentemente rilasciato DETR o trasformatori di rilevamento, ma queste reti utilizzano le CNN. Mentre i ViT sono pronti a rendere obsolete le convoluzioni.