L’intelligenza artificiale può ora utilizzare Instagram per prevedere il rischio di abuso di sostanze
Un articolo pubblicato di recente ha sviluppato un metodo per prevedere il rischio di abuso di sostanze da parte di qualcuno sulla base dei propri account Instagram ( link ). Diamo un’occhiata a come hanno fatto.
Abuso di sostanze. Gli autori dell’articolo hanno riconosciuto il problema urgente dell’abuso di sostanze: è un problema in tutto il mondo che colpisce le persone indipendentemente dallo stato socioeconomico. Ecco una citazione dall’articolo:
“Insieme alle scelte di vita e ai fattori di rischio metabolico, l’uso di alcol, tabacco e droghe è tra le prime dieci cause di decessi prevenibili negli Stati Uniti. L’abuso di prescrizione e droghe illecite provoca oltre 100 morti per overdose da solo ogni giorno, detronizzando gli incidenti automobilistici come la principale causa di decessi per lesioni. ”
L’attuale epidemia di oppioidi negli Stati Uniti ha solo peggiorato il problema e gli autori speravano di impiegare moderne innovazioni tecnologiche per affrontare il problema.
Dati Instagram. L’articolo ha scelto di utilizzare Instagram per la sua popolarità tra i giovani utenti e la sua rapida crescita. Gli autori osservano che le immagini e il testo pubblicati dagli utenti possono essere utilizzati per farsi un’idea della personalità di ciascun utente. Per sfruttare questa caratteristica dei social media, gli autori hanno fatto crowdsourcing a migliaia di partecipanti (con il loro consenso, ovviamente) per condividere le loro informazioni su Instagram e partecipare allo studio. In particolare, hanno esaminato le foto, i commenti e le didascalie di ciascun utente (è interessante notare che il numero medio di post per utente era di 183,5 post). Gli autori hanno utilizzato ASSIST modificato NIDA per assegnare etichette “ad alto rischio” e “a basso rischio” ai partecipanti. Diamo un’occhiata ad alcuni esempi estremi in modo da poter comprendere meglio quali tipi di cose l’intelligenza artificiale cercherebbe.
Se un utente pubblica un’immagine di se stesso mentre beve alcolici, il modello di apprendimento automatico probabilmente lo contrassegnerebbe come ad alto rischio di abuso di sostanze.
Se un utente commenta e dice “Odio le droghe”, il modello di apprendimento automatico probabilmente lo contrassegnerebbe come a basso rischio di abuso di sostanze.
Se un utente pubblica un’immagine con la didascalia “Sostanze che attualmente abusano di sostanze”, il modello di apprendimento automatico potrebbe contrassegnarlo come un rischio elevato di abuso di sostanze. (OK non realistico ma ottieni il punto)
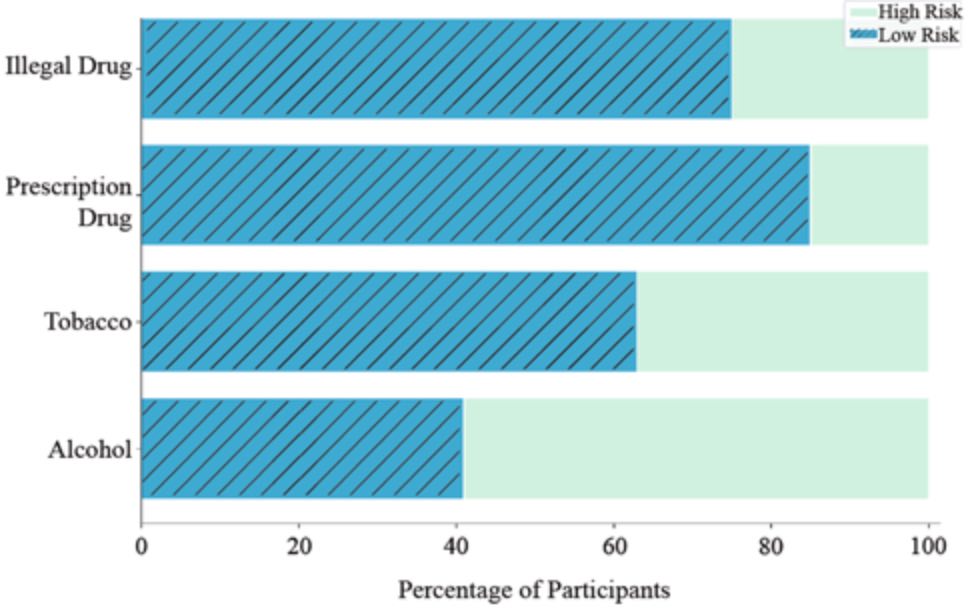
La sostanza utilizza la distribuzione del rischio tra gli utenti di Instagram nel set di dati. Crediti immagine agli autori del documento originale.
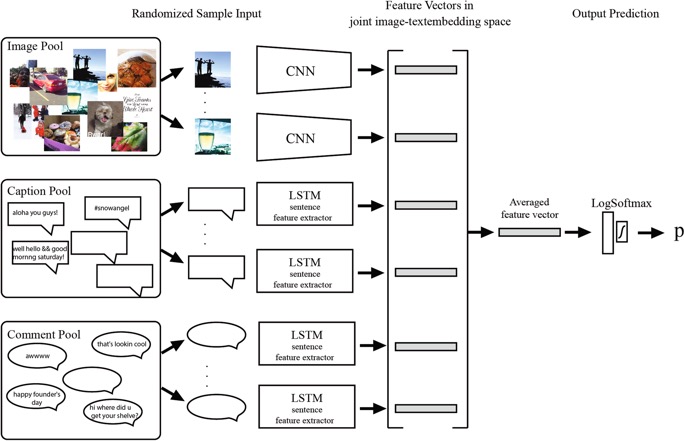
Modello di apprendimento automatico. Poiché l’immagine e il testo hanno strutture dati diverse, gli autori hanno utilizzato diverse architetture di machine learning diverse. Per analizzare le immagini pubblicate dagli utenti, hanno utilizzato un modello ResNet-18 pre-addestrato sul set di dati ImageNet. Hanno ottimizzato il modello sul proprio set di dati Instagram per massimizzare la precisione. Per analizzare il testo (didascalie e commenti), gli autori hanno prima usato Word2Vec sui loro dati, un metodo per cambiare le parole in rappresentazioni vettoriali, quindi hanno alimentato i vettori risultanti in una rete di memoria a breve termine (LSTM). Hanno quindi utilizzato un livello finale per combinare i risultati delle reti di immagini e testo per ottenere una previsione finale.
Architettura utilizzata: le CNN estraggono le funzionalità dalle immagini e le LSTM estraggono le funzionalità dal testo. Un livello finale utilizza queste funzionalità per ottenere una previsione finale. Crediti immagine agli autori del documento originale.
Risultati. Gli autori hanno scoperto che la loro IA potrebbe identificare il rischio di alcol in base ai contenuti di Instagram in modo significativamente migliore di quanto ci si aspetti a causa di casualità. Hanno ottenuto un punteggio F1 (una misurazione standard di precisione per questo tipo di problema) del 72,4%, rispetto a un punteggio di ipotesi F1 del 50%. Tuttavia, i risultati non erano così promettenti quando l’intelligenza artificiale stava cercando di identificare il rischio di tabacco, farmaci da prescrizione e droghe illegali; l’IA non è stata in grado di ottenere punteggi di F1 superiori al 40% per quelle classi.
Conclusione. L’articolo è stato il primo a dimostrare che l’apprendimento automatico potrebbe essere utilizzato per identificare il potenziale comportamento di abuso di sostanze utilizzando i social media. Gli autori osservano che il loro metodo è completamente automatico, un miglioramento rispetto alle ricerche precedenti che richiedevano analisi manuali per prevedere il rischio di abuso di sostanze. Attribuiscono le inesattezze del modello su classi fuori dall’alcool a un set di dati sbilanciato (c’erano relativamente poche persone ad alto rischio per quelle classi).