Il progetto CodeNet di IBM testerà fino a che punto puoi spingere l’intelligenza artificiale per scrivere software
La divisione di ricerca sull’intelligenza artificiale di IBM ha rilasciato un set di dati di 14 milioni di campioni per sviluppare modelli di apprendimento automatico che possono aiutare nelle attività di programmazione. Chiamato Project CodeNet, il set di dati prende il nome da ImageNet, il famoso repository di foto etichettate che ha innescato una rivoluzione nella visione artificiale e nel deep learning .
Sebbene ci siano poche possibilità che i modelli di apprendimento automatico basati sul set di dati CodeNet rendano superflui i programmatori umani, c’è motivo di sperare che rendano gli sviluppatori più produttivi.
Automatizzare la programmazione con il deep learning
All’inizio degli anni 2010, notevoli progressi nell’apprendimento automatico hanno innescato l’entusiasmo (e la paura) per l’intelligenza artificiale che ha presto automatizzato molte attività, inclusa la programmazione. Ma la penetrazione dell’IA nello sviluppo del software è stata estremamente limitata.
I programmatori umani scoprono nuovi problemi ed esplorano diverse soluzioni utilizzando una pletora di meccanismi di pensiero conscio e subconscio. Al contrario, la maggior parte degli algoritmi di apprendimento automatico richiede problemi ben definiti e molti dati annotati per sviluppare modelli in grado di risolvere gli stessi problemi.
Ci sono stati molti sforzi per creare set di dati e benchmark per sviluppare e valutare sistemi “AI per codice”. Ma data la natura creativa e aperta dello sviluppo del software, è molto difficile creare il set di dati perfetto per la programmazione.
Il set di dati CodeNet
Sopra: Project CodeNet è un enorme set di dati di circa 14 milioni di campioni di codice distribuiti in dozzine di linguaggi di programmazione.
Con Project CodeNet , i ricercatori di IBM hanno cercato di creare un set di dati multiuso che può essere utilizzato per addestrare modelli di apprendimento automatico per varie attività. I creatori di CodeNet lo descrivono come un “set di dati su larga scala, diversificato e di alta qualità per accelerare i progressi algoritmici nell’AI per il codice”.
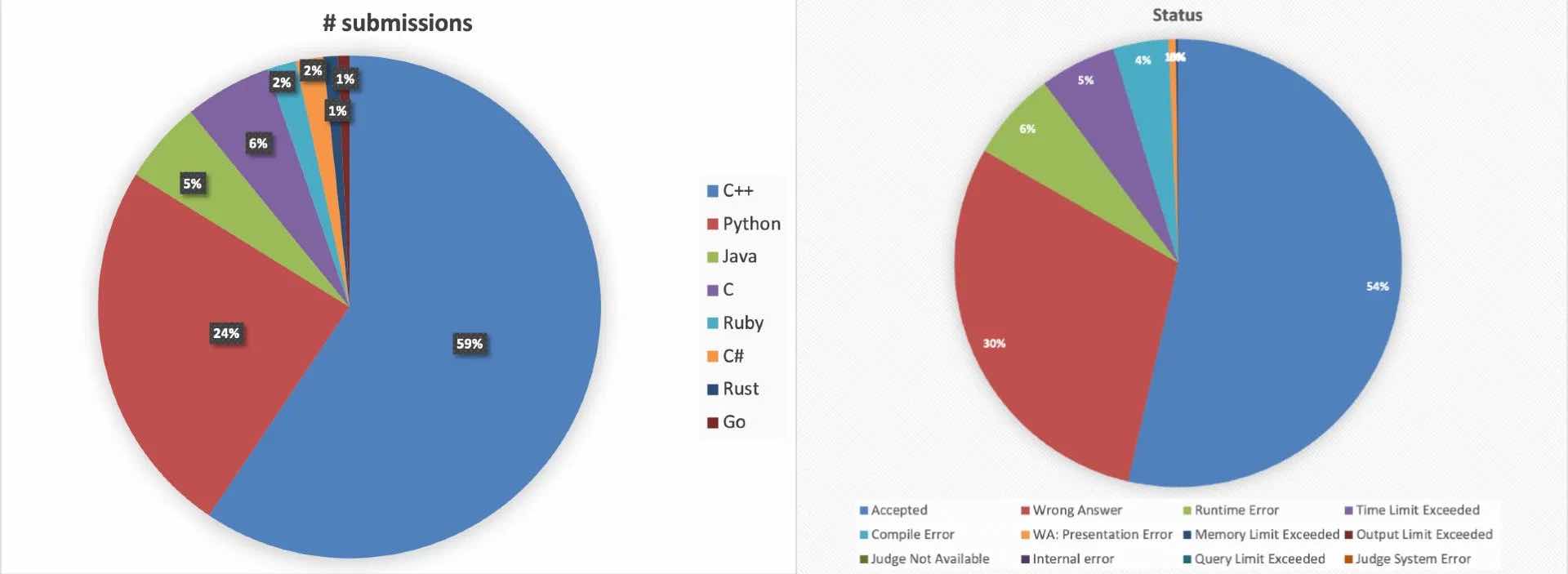
Il set di dati contiene 14 milioni di campioni di codice con 500 milioni di righe di codice scritte in 55 diversi linguaggi di programmazione. Gli esempi di codice sono stati ottenuti dagli invii a quasi 4.000 sfide pubblicate sulle piattaforme di codifica online AIZU e AtCoder. Gli esempi di codice includono risposte corrette e errate alle sfide.
Una delle caratteristiche chiave di CodeNet è la quantità di annotazioni che è stata aggiunta agli esempi. Ognuna delle sfide di codifica incluse nel set di dati ha una descrizione testuale insieme ai limiti di tempo e memoria della CPU. Ogni invio di codice contiene una dozzina di informazioni, tra cui la lingua, la data di invio, le dimensioni, il tempo di esecuzione, l’accettazione e i tipi di errore.
I ricercatori di IBM hanno anche compiuto grandi sforzi per assicurarsi che il set di dati sia bilanciato lungo diverse dimensioni, inclusi il linguaggio di programmazione, l’accettazione e i tipi di errore.
Attività di programmazione per l’apprendimento automatico
CodeNet non è l’unico set di dati per addestrare modelli di machine learning per attività di programmazione. Ma alcune caratteristiche che lo distinguono. Il primo è la dimensione assoluta del set di dati, compreso il numero di campioni e la diversità delle lingue.
Ma forse più importanti sono i metadati che accompagnano i campioni di codifica. Le ricche annotazioni aggiunte a CodeNet lo rendono adatto a un insieme diversificato di attività rispetto ad altri set di dati di codifica specializzati per attività di programmazione specifiche.
Esistono diversi modi in cui CodeNet può essere utilizzato per sviluppare modelli di apprendimento automatico per attività di programmazione . Uno è la traduzione linguistica. Poiché ogni sfida di codifica nel set di dati contiene invii di vari linguaggi di programmazione, i data scientist possono utilizzarla per creare modelli di apprendimento automatico che traducono il codice da una lingua all’altra. Questo può essere utile per le organizzazioni che desiderano trasferire il vecchio codice in nuovi linguaggi e renderli accessibili alle nuove generazioni di programmatori e gestibili con nuovi strumenti di sviluppo.
CodeNet può anche aiutare a sviluppare modelli di apprendimento automatico per la raccomandazione del codice. Gli strumenti di raccomandazione potrebbero essere semplici come modelli in stile completamento automatico che completano l’attuale riga di codice su sistemi più complessi che scrivono funzioni complete o blocchi di codice.
Poiché CodeNet dispone di una vasta gamma di metadati sulla memoria e sulle metriche del tempo di esecuzione, i data scientist possono anche utilizzarli per sviluppare sistemi di ottimizzazione del codice. Oppure possono utilizzare i metadati di tipo errore per addestrare i sistemi di apprendimento automatico che segnalano potenziali difetti nel codice sorgente.
Un caso d’uso più avanzato che sarebbe interessante vedere sono le generazioni di codice. CodeNet è una ricca libreria di descrizioni testuali dei problemi e del relativo codice sorgente. Ci sono già stati diversi esempi di sviluppatori che utilizzano modelli di linguaggio avanzati come GPT-3 per generare codice da descrizioni in linguaggio naturale. Sarà interessante vedere se CodeNet può aiutare a mettere a punto questi modelli di linguaggio per diventare più coerenti nella generazione del codice.
I ricercatori di IBM hanno già condotto diversi esperimenti con CodeNet, inclusa la classificazione del codice, la valutazione della somiglianza del codice e il completamento del codice. Le architetture di deep learning che hanno utilizzato includono semplici perceptron multistrato, reti neurali convoluzionali , reti neurali a grafo e trasformatori. I risultati, riportati in un documento che descrive in dettaglio il progetto CodeNet, mostrano che sono stati in grado di ottenere una precisione superiore al 90% nella maggior parte delle attività. (Anche se vale la pena notare che la valutazione dell’accuratezza nella programmazione è leggermente diversa dalla classificazione delle immagini e dalla generazione del testo, dove errori minori potrebbero portare a risultati scomodi ma accettabili.)
Un mostruoso sforzo ingegneristico
Gli ingegneri di IBM hanno svolto un complicato sforzo di ingegneria del software e dei dati per curare il set di dati CodeNet e sviluppare i suoi strumenti complementari.
Innanzitutto, hanno dovuto raccogliere i campioni di codice da AIZU e AtCoder. Mentre uno di loro aveva un’interfaccia di programmazione dell’applicazione che rendeva facile ottenere il codice, l’altro non aveva un’interfaccia di facile accesso e i ricercatori hanno dovuto sviluppare strumenti che scartassero i dati dalle pagine web della piattaforma e li scomponessero in una tabella formato. Quindi, hanno dovuto unire manualmente i due set di dati in uno schema unificato.
Successivamente, hanno dovuto sviluppare strumenti per ripulire i dati identificando e rimuovendo duplicati e campioni che contenevano molto codice morto (codice sorgente che non viene eseguito in fase di esecuzione).
Hanno anche sviluppato strumenti di pre-elaborazione che semplificheranno l’addestramento di modelli di apprendimento automatico sul corpus CodeNet. Questi strumenti includono tokenizzatori per diversi linguaggi di programmazione, alberi di analisi e un generatore di rappresentazioni grafiche da utilizzare nelle reti neurali a grafo.
Tutti questi sforzi sono un promemoria dell’enorme sforzo umano necessario per creare sistemi di apprendimento automatico efficienti. L’intelligenza artificiale non è pronta a sostituire i programmatori (almeno per il momento). Ma potrebbe cambiare il tipo di attività che richiedono gli sforzi e l’ingegnosità dei programmatori umani.