I nuovi dati MLPerf mostrano che la concorrenza è in aumento nell’IA, ma NVIDIA è ancora in testa
Oggi è stato pubblicato il secondo round (versione 0.7) dei risultati del benchmark MLPerf Inference. Come gli ultimi risultati della formazione, annunciati a luglio, i nuovi numeri di inferenza mostrano un aumento del numero di aziende che si sottopongono e un numero maggiore di piattaforme e carichi di lavoro supportati. I numeri di inferenza MLPerf sono suddivisi in quattro categorie: Data Center, Edge, Mobile e Notebook. Il numero di richieste è aumentato da 43 a 327 e il numero di aziende che hanno presentato richieste è aumentato da nove a 21. Le aziende che hanno presentato la richiesta includevano aziende di semiconduttori, OEM di dispositivi e diversi laboratori di prova. Le ovvie omissioni da questo round di presentazioni includevano Google e tutte le società cinesi, inclusi i precedenti partecipanti Alibaba e Tencent.
Come rapido aggiornamento, MLPerf è un consorzio di settore istituito per sviluppare standard per soluzioni di Machine Learning (ML) / Intelligenza Artificiale (AI). MLPerf è una raccolta di una suite di benchmark per la misurazione delle prestazioni di formazione e inferenza di hardware, software e servizi ML / AL. Gli ultimi risultati di inferenza v0.7 segnano solo la seconda volta che i risultati dell’inferenza sono stati pubblicati. Il primo è stato quasi un anno fa. L’organizzazione MLPerf lavora continuamente per migliorare le suite di benchmarking con modelli nuovi o migliorati che rappresentano carichi di lavoro AI reali. Inoltre, l’organizzazione sta lavorando per aumentare la frequenza dei test con un obiettivo di almeno due volte l’anno, sta valutando di consentire la pubblicazione dei risultati dei test tra le versioni principali e sta lavorando per aggiungere ulteriori qualificatori, come i dati sul consumo di energia per valutare l’efficienza di una piattaforma AI. I risultati dei test possono essere forniti da qualsiasi azienda nella catena del valore dell’elettronica e vengono verificati in modo casuale.
Ogni categoria di segmento include un segmento “chiuso” e “aperto”. Il segmento “chiuso” si riferisce ai test eseguiti utilizzando un modello di carico di lavoro equivalente al modello di riferimento. Il segmento “aperto” consente modifiche al modello in modo che i fornitori possano dimostrare le prestazioni rispetto ad altri carichi di lavoro mirati. Inoltre, ci sono sottosegmenti: “Disponibile” per i prodotti che sono oggi sul mercato, “Anteprima” per i prodotti che arriveranno sul mercato nei prossimi sei mesi e “Ricerca, Sviluppo o Interno” per i prodotti ancora in fase di sviluppo o appena considerati progetti di laboratorio. Per coerenza, la maggior parte della nostra analisi si concentra sui segmenti chiusi e disponibili. In alcuni casi, un prodotto non ha un numero per tutti i test perché i numeri non sono stati inviati o non sono stati in grado di raggiungere il punteggio di accuratezza minimo del 99%. Poiché la suite di benchmark è in continua evoluzione, confrontare i numeri con i risultati precedenti non sono particolarmente utili fino a quando la suite non raggiunge uno stato più maturo. Tuttavia, c’è molto da raccogliere dai risultati.
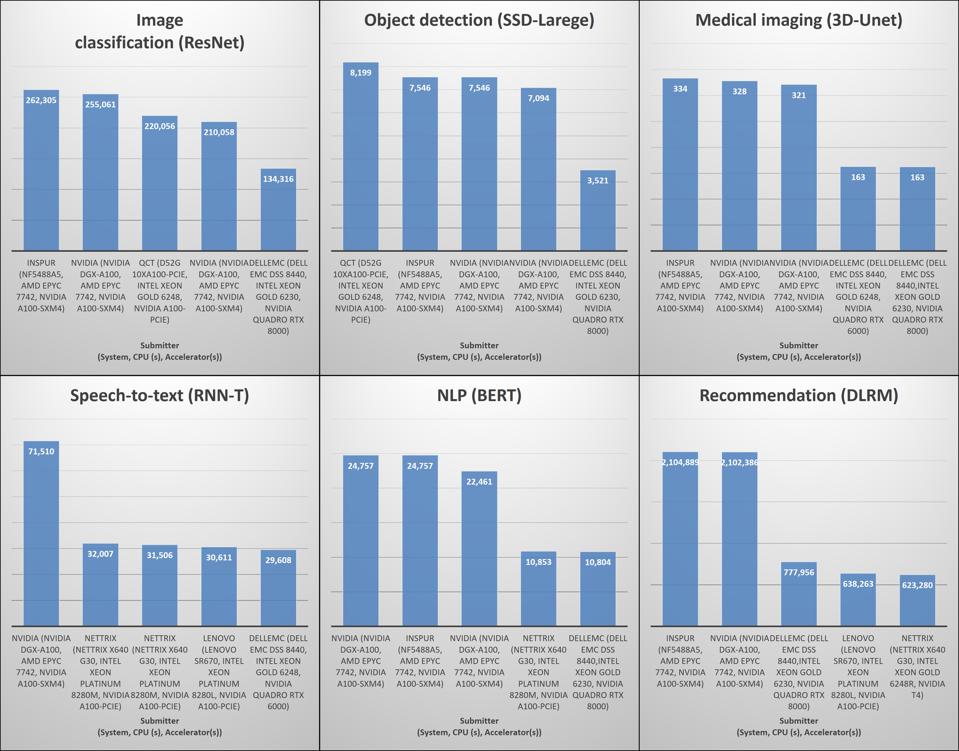
Per le applicazioni del data center, i test di inferenza 0.7v includevano quattro nuovi benchmark: rappresentazione e trasformazione dell’encoder bidirezionale (BERT) che rappresenta i carichi di lavoro di elaborazione del linguaggio naturale, modello di raccomandazione Deep Learning (DLRM) che rappresenta i carichi di lavoro raccomandati, U-Net 3D che rappresenta l’imaging medico carichi di lavoro e Recurrent Neural Network Transducer (RNN-T) che rappresenta i carichi di lavoro da voce a testo. Nella categoria chiusa, i risultati erano simili a quelli dei risultati dei test di formazione rilasciati a luglio. Le piattaforme accelerate hanno sovraperformato le piattaforme solo CPU di un enorme margine e gli acceleratori principali erano le GPU e la GPU principale con un enorme margine era la nuova GPU A-100 di Nvidia basata sull’architettura Ampere. L’aumento delle prestazioni rispetto alle GPU Tesla (T4) per inferenza, il leader precedente, è evidente in ogni carico di lavoro. Ciò dimostra il valore dell’architettura Ampere che consente sette partizioni di inferenza su una singola GPU. In termini di altri acceleratori, erano rappresentati solo FPGA Xilinx e solo nella categoria aperta.
Questo ciclo di test di inferenza include anche quattro nuovi benchmark per dispositivi mobili, come smartphone, tablet e PC. La nuova suite mobile include MobileNetEdgeTPU che rappresenta i carichi di lavoro di classificazione delle immagini, SSD-MobileNetV2 che rappresenta i carichi di lavoro di riconoscimento degli oggetti, DeepLabV3 + MobileNetV2 che rappresenta la comprensione della scena e la fotografia computazionale e MobileBERT che rappresenta l’elaborazione del linguaggio naturale. Per la categoria mobile, c’erano tre proposte che rappresentavano gli smartphone 5G di livello premium e SoC mobili: MediaTek Dimensity 820 nello Xisomi Redmi 10X, Qualcomm Snapdragon 855+ nell’Asus ROG Phone 3 e Samsung Exynos 990 nel Samsung Galaxy Nota 20 Ultra ei risultati sono stati contrastanti. MediaTek Dimensity 820 ha ottenuto un punteggio elevato in tre delle quattro categorie per la classificazione delle immagini, il rilevamento di oggetti, e segmentazione delle immagini, ma ha ottenuto il punteggio più basso nell’elaborazione del linguaggio naturale (PNL). Il Samsung Exynos 990 ha ottenuto un punteggio elevato nella classificazione delle immagini e nella PNL. E il Qualcomm Snapdragon 865+ ha ottenuto un punteggio alto nella segmentazione delle immagini e nella PNL. Ciò dimostra le differenze nell’architettura di questi SoC complessi e rende impossibile dichiarare un chiaro vincitore. Tutti i SoC mobili utilizzano core CPU Arm, ma ognuno ha acceleratori ML diversi e tutti adottano approcci drasticamente diversi per gestire i carichi di lavoro AI.
Per notebook, c’era solo una presentazione per il 11 Intel esimo processore Intel Core Gen, altrimenti noto come Tiger Lake, che include il nuovo microarchitettura CPU Willow Cove e la prima generazione Intel Xe grafica integrata. È ancora elencato nel segmento di anteprima, ma i prodotti con il processore saranno sul mercato questo trimestre. Ancora una volta, questa è un’area che Tirias Research vorrebbe ricevere più contributi, in particolare da piattaforme basate su AMD per un vero confronto delle prestazioni dell’IA nelle piattaforme PC mobili.
E l’ultima categoria è Edge, che ha raccolto il maggior numero di candidature, soprattutto nella categoria open a causa del gruppo di ingegneria dividiti, che ha presentato 230 risultati di test su piattaforme Firefly, Raspberry Pi e Nvidia Jetson Arm. La categoria, tuttavia, è ancora enorme e comprende di tutto, dalle piattaforme a bassissima potenza per l’automazione e la robotica ai server per il networking. Di conseguenza, è più difficile confrontare i risultati. Sul lato server, i server con GPU Nvidia Ampere sono stati il chiaro vincitore, seguiti dai server che utilizzano GPU Tesla T4 meno recenti, simili ai risultati per il data center. Una presentazione di Centaur Technology che utilizza la CPU Centaur x86 – e sì, c’è ancora un terzo fornitore di processori x86 – con un processore AI integrato ha funzionato abbastanza bene in termini di latenza con una piccola dimensione del campione. Nella gamma di potenza 10-15 W, il Nvidia Jetson AGX Xavier, la fascia alta della linea di prodotti Jetson, era l’unico concorrente. E nella gamma a bassissima potenza le piattaforme Firefly e Raspberry Pi hanno ottenuto risultati simili. Le categorie a bassa potenza, più di ogni altra, hanno il potenziale per crescere a causa dell’ampia varietà di soluzioni disponibili o del sottosviluppo. L’intera tabella dei risultati è disponibile suqui sul sito MLPerf.
Per riassumere, Nvidia è ancora un chiaro leader nelle soluzioni AI dall’edge al cloud. Tuttavia, la concorrenza sta crescendo insieme alla partecipazione di MLPerf. Inoltre, il segmento degli smartphone si sta dimostrando molto competitivo e il segmento dei PC è ancora agli inizi. È stato deludente non vedere la partecipazione di nessuna delle startup di chip AI che spesso rivendicano prestazioni ed efficienza elevate. Con risorse limitate e l’impatto della pandemia COVID-19, è stato difficile per molti di loro partecipare a MLPerf. Tuttavia, molti, come Grog e Tenstorrent, hanno indicato l’intenzione di presentare i risultati in futuro. È anche importante notare che come qualsiasi benchmark MLPerf non è perfetto. In molti casi la tecnologia del silicio, le dimensioni e le dinamiche dei carichi di lavoro superano le capacità dei benchmark. Tuttavia, utilizzando una suite di carichi di lavoro che continuano a migliorare e con un’ampia partecipazione del settore, MLPerf continuerà a migliorare. E MLPerf è l’unica soluzione pratica per i test ML / AI nel settore.