Non si tratta solo di dati; Si tratta di portare i dati dove sono necessari quando sono necessari
C’è un vecchio detto che i dati aumentano per soddisfare lo spazio di archiviazione disponibile. Questo è uno dei motivi per cui ho riso della frase “big data” quando è uscita. Abbiamo sempre lavorato con quanti più dati possibile. Ciò che è cambiato ora è che i volumi di dati nell’intelligenza artificiale (AI), nell’HPC e in altre arene moderne stanno finalmente colpendo un muro che non è spazio di archiviazione o potenza di elaborazione, è la larghezza di banda per i due lavorano insieme con bassa latenza per la varietà di richieste di dati esistenti. Nuove soluzioni stanno uscendo per affrontare questo problema.
L’elaborazione parallela in un’architettura scale-out è ciò che ha consentito al cloud computing di crescere. Più processori che lavorano in sincronizzazione per gestire i volumi di richieste che Internet sta guidando. Allo stesso tempo, l’archiviazione è aumentata con le reti SAN (Storage Area Network) per consentire a più unità e persino server di guardare alle applicazioni come se fossero un’unica fonte. La combinazione ha comportato la necessità di modificare le architetture di bus interno e di rete esterna per supportare flussi di dati più elevati.
Questo, ovviamente, non è così facile come potrebbe sembrare a prima vista. Non tutte le richieste di dati sono uguali. Non è solo da un punto di vista prioritario. La maggior parte dei dati necessari per addestrare un motore di inferenza AI è di un tipo molto diverso rispetto ai flussi di dati orientati alla transazione destinati al motore di inferenza di runtime.
Riportare gli studenti a scuola in sicurezza durante la pandemia di COVID-19
La sfida che ne è derivata ha fatto sì che molte aziende stiano cercando come fornire un’architettura software per gestire al meglio le elevate esigenze di numerose applicazioni. Molte aziende stanno lavorando a tali soluzioni, proponendo potenti soluzioni di archiviazione. La gamma di aziende include tutti i principali attori, come Dell, EMC e HPE, e più startup.
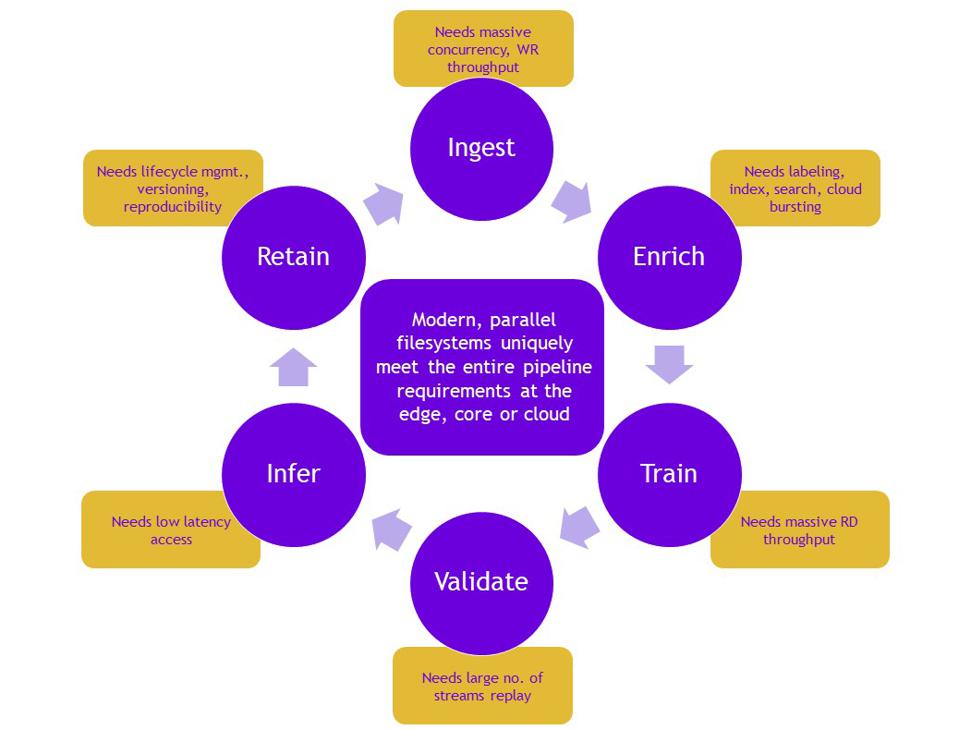
Queste organizzazioni sono interessate a causa dell’elevata domanda di potenti pipeline di dati. Ci sono tre aree ovvie in cui ciò è fondamentale:
· Calcolo ad alte prestazioni (HPC): l’analisi meteorologica e la ricerca biotecnologica sono due esempi in cui è necessario lo scricchiolio di grandi volumi di dati.
· Intelligenza artificiale: l’addestramento di grandi motori di inferenza in un tempo ragionevole significa alimentare grandi blocchi di dati il più rapidamente possibile.
· Trading ad alta frequenza (HFT): grandi quantità di transazioni finanziarie avvengono molto più rapidamente e la velocità è un chiaro vantaggio.
Tuttavia, ci sono molte altre aree che richiedono una grande larghezza di banda dei dati. Attenendosi all’intelligenza artificiale, mentre le persone spesso si concentrano sull’inferenza della formazione, l’inferenza del runtime ha un’esigenza molto diversa. Mentre l’addestramento si occupa dell’invio di grandi blocchi di dati a un sistema, l’inferenza in runtime ha una sfida diversa. Il runtime si occupa della singola transazione. Tuttavia, nel cloud, ci sono molte transazioni. Ciò che serve è una bassa latenza per ogni transazione, anche se può esserci un numero elevato di transazioni molto elevato.
Gli addetti IT sanno anche che esistono richieste di dati “invisibili”. La conservazione dei dati è fondamentale, sia da un punto di vista normativo che di backup / ripristino dei dati. Sebbene molta attenzione sia, giustamente, alla riservatezza dei dati e assicurando che i dati identificabili non vengano conservati oltre un certo periodo, c’è una grande quantità di dati che viene conservata. Essere in grado di estrarre tali dati, gestire il controllo delle versioni e svolgere altre attività IT critiche senza influire sulle prestazioni del sistema in tempo reale richiede un’attenzione significativa alla larghezza di banda dei dati.
Una delle startup che affrontano la sfida è Weka IO. Sebbene si stiano chiaramente concentrando sui frutti a bassa pendenza di HPC, AI e HFT, non hanno dimenticato l’intero ciclo di vita necessario per l’accesso e la gestione dei dati. “Il trio di HPC, AI e HFT sono ottimi esempi di casi d’uso con elevato throughput, bassa latenza e richieste di larghezza di banda elevata”, ha affermato Ken Grohe, Presidente e CRO, WekaIO. “I risultati di successo dell’IA dipendono da tre elementi essenziali, come tre lati di un triangolo equilatero: tecnologia di accelerazione del calcolo come GPU, rete ad alta velocità e un moderno file system parallelo ottimizzato per flash NVMe e cloud ibrido nativo. Quando questi tre elementi sono presenti, ottieni la latenza più bassa e l’I / O più elevato che accelera la formazione sull’IA e il time-to-market “.
Il riferimento al software del signor Grohe è fondamentale. Non è più ragionevole per le singole applicazioni effettuare una chiamata diretta al sistema operativo e quindi a un’unità disco. Lo sviluppo della SAN, negli anni ’90, è stato il primo passo nella costruzione dei sistemi di archiviazione per l’era di Internet. Poiché le applicazioni sono diventate più complesse, le soluzioni di archiviazione si sono evolute oltre la SAN verso applicazioni più complesse e robuste.
Così tanti di noi in tecnologia adorano concentrarsi sugli oggetti luccicanti. Sono, certamente, fighi. Tuttavia, non dobbiamo dimenticare che ci sono tecnologie che potrebbero non essere brillanti per il mercato più ampio, ma sono brillanti per pochi chiave che desiderano risolvere un problema profondo nel cuore dei sistemi.
La crescita dell’intelligenza artificiale e di altre applicazioni molto visibili può far dimenticare alle persone che esistono tecnologie fondamentali che rendono possibile l’implementazione dell’IA. L’evoluzione dello storage si è allontanata dal nastro magnetico (sì, lo so …). La necessità di gestire i grandi volumi di dati necessari distribuendoli dai supporti di memorizzazione alle applicazioni richiede che i nuovi sistemi non si limitino a spostare i dati, ma sappiano abbastanza sulla domanda per spostare i dati giusti al momento giusto con la giusta latenza.