OpenAI ha presentato LifeSciBench, un nuovo benchmark progettato per valutare la capacità dei modelli di intelligenza artificiale di supportare attività reali nella ricerca biomedica e nelle scienze della vita. Il benchmark è stato sviluppato per superare uno dei limiti principali delle valutazioni biologiche tradizionali, spesso basate su domande chiuse, recupero di nozioni, problemi con una risposta unica o test isolati su singoli domini. LifeSciBench punta invece a misurare compiti più vicini al lavoro quotidiano di ricercatori in biotecnologia, farmaceutica, genomica, ricerca traslazionale e sviluppo preclinico.
Il benchmark arriva dopo il lancio e l’aggiornamento di GPT-Rosalind, il modello di OpenAI specializzato per la ricerca nelle life sciences. GPT-Rosalind è progettato per ragionare su molecole, proteine, geni, pathway biologici, dati sperimentali, letteratura scientifica e strumenti di analisi. Con LifeSciBench, OpenAI introduce un sistema di valutazione pensato per capire se modelli di questo tipo riescono davvero a produrre risultati utili in workflow scientifici complessi, non soltanto a rispondere correttamente a domande teoriche.
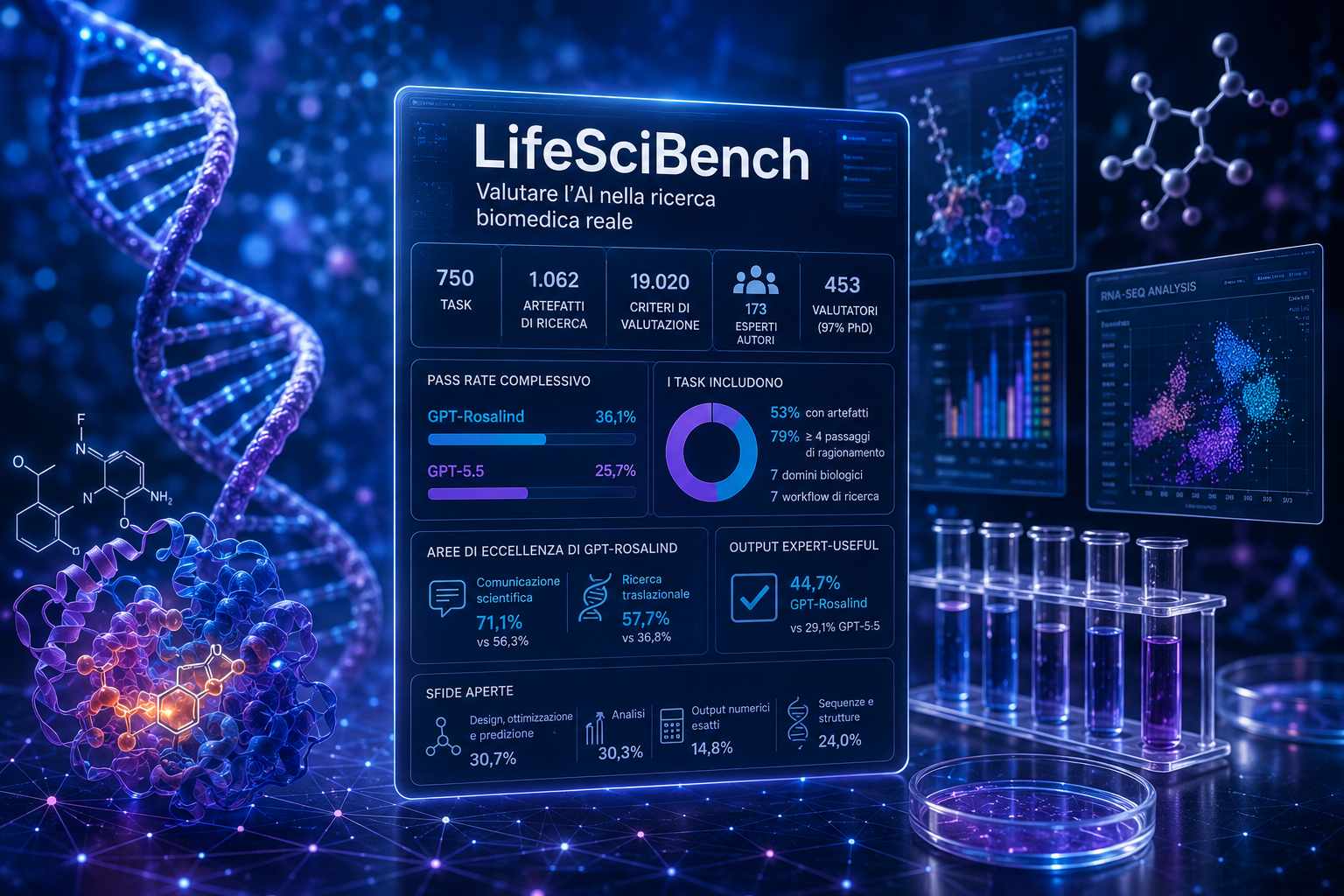
LifeSciBench è stato costruito con il contributo di 173 esperti che hanno scritto i task. Tutti i compiti sono stati sottoposti ad almeno due revisioni esperte e a una media di sei controlli automatici. Una seconda fase di validazione ha coinvolto 453 valutatori, il 97% dei quali in possesso di un dottorato. Secondo OpenAI, il livello di accordo dei valutatori sulla pertinenza dei task rispetto alla ricerca reale, sul ragionamento scientifico richiesto, sull’uso delle evidenze e sulla praticità delle risposte supera il 96%.
La struttura del benchmark comprende 750 task, 1.062 artefatti di ricerca e 19.020 criteri di valutazione. Ogni task è formulato come una richiesta che un ricercatore potrebbe effettivamente rivolgere a un collega: non una domanda a scelta multipla, ma un compito aperto che richiede analisi, sintesi, valutazione critica, progettazione sperimentale o produzione di un risultato operativo. La risposta del modello viene valutata attraverso rubriche dettagliate, con una media di circa 25 criteri per task.
La scelta delle rubriche è centrale. LifeSciBench non valuta soltanto se il modello arriva a una conclusione corretta, ma se il percorso scientifico è valido. Le rubriche considerano affermazioni scientifiche, uso delle fonti, passaggi di calcolo, interpretazione dei dati, qualità della motivazione, gestione dell’incertezza, limiti sperimentali, vincoli pratici e utilità dell’output per un esperto. Un modello può quindi ricevere credito parziale anche quando non supera il task, oppure può essere penalizzato se produce una risposta apparentemente convincente ma trascura una variabile biologica, un vincolo sperimentale o un problema metodologico rilevante.
OpenAI usa due metriche distinte: score e pass rate. Lo score misura il credito medio ottenuto sulle singole voci della rubrica e consente di riconoscere risposte parzialmente utili. Il pass rate misura invece la percentuale di task in cui il modello raggiunge la soglia di successo a livello di compito, fissata al 70% dei punti disponibili nella rubrica. Questa distinzione è importante perché nella ricerca scientifica una risposta può contenere elementi utili senza essere sufficiente per essere considerata completa o affidabile.
I task coprono sette domini biologici e sette workflow di ricerca. I domini includono aree come genomica, chimica medicinale e ricerca clinica o traslazionale. I workflow comprendono gestione delle evidenze, analisi, progettazione e ottimizzazione, ragionamento scientifico, validazione e operazioni, ricerca traslazionale e comunicazione scientifica. L’impostazione è quindi trasversale: LifeSciBench non misura solo conoscenza biologica, ma la capacità di applicarla in processi di ricerca che richiedono decisioni, confronto tra fonti, gestione di dati incompleti e produzione di artefatti utilizzabili.
Una caratteristica tecnica rilevante è la presenza di materiali allegati. Il 53% dei task richiede l’analisi di almeno un artefatto, come PDF scientifici, tabelle, grafici, sequenze genetiche, strutture chimiche o risorse web. Questo rende il benchmark più vicino a un contesto di laboratorio o di R&D, dove il ricercatore non lavora su testo pulito e isolato, ma su evidenze eterogenee, figure complesse, dati numerici, file sperimentali, documentazione regolatoria e letteratura scientifica.
Il 79% dei task richiede in media almeno quattro passaggi di ragionamento o decisione. Questo dato è importante perché separa LifeSciBench dai benchmark che valutano principalmente recupero di conoscenza. Molti compiti richiedono di interpretare prove incomplete, riconciliare risultati contraddittori, criticare un disegno sperimentale, proporre follow-up, scegliere tra alternative metodologiche o collegare risultati preclinici a implicazioni cliniche. Sono attività in cui l’errore non dipende solo dalla mancanza di una nozione, ma dalla cattiva integrazione tra evidenza, metodo e decisione.
OpenAI ha valutato cinque modelli, tra cui GPT-Rosalind e GPT-5.5. GPT-Rosalind ha ottenuto il miglior risultato complessivo, con il punteggio medio più alto e il miglior pass rate. Su 750 task, GPT-Rosalind è risultato il modello con il punteggio medio più alto in 386 task. Il suo pass rate complessivo è stato del 36,1%, contro il 25,7% di GPT-5.5. Il risultato è significativo perché mostra un vantaggio netto del modello specializzato, ma indica anche che il benchmark è tutt’altro che saturo: persino il modello migliore supera poco più di un terzo dei compiti.
Le aree in cui GPT-Rosalind mostra i guadagni più evidenti sono comunicazione scientifica e ricerca traslazionale. Nella comunicazione scientifica, il pass rate passa dal 56,3% di GPT-5.5 al 71,1% di GPT-Rosalind. Nella ricerca traslazionale, cioè il collegamento tra evidenze precliniche e implicazioni cliniche, il pass rate cresce dal 36,8% al 57,7%. OpenAI segnala però che la categoria di comunicazione scientifica è piccola, con 9 task, quindi il risultato va interpretato con cautela.
Un altro dato rilevante riguarda gli output “expert-useful” o azionabili. Nei task che richiedono risultati effettivamente utilizzabili da un esperto, GPT-Rosalind ottiene il 44,7% contro il 29,1% di GPT-5.5. Nei task che richiedono gestione dell’incertezza, caveat e limiti, GPT-Rosalind raggiunge il 44,8%, mentre GPT-5.5 si ferma al 29,3%. Questo suggerisce che il miglioramento del modello specializzato non riguarda solo la correttezza nozionistica, ma anche la capacità di produrre risposte più attente a vincoli, rischi, ambiguità e limiti dell’evidenza.
Le aree più difficili restano però quelle più operative. Nei workflow di design, ottimizzazione e predizione, GPT-Rosalind raggiunge un pass rate del 30,7%. Nell’area di analisi, il pass rate è del 30,3%. Questi risultati indicano che i modelli continuano a faticare quando devono progettare esperimenti, ottimizzare condizioni, produrre previsioni vincolate o trasformare dati complessi in decisioni operative. È proprio in queste aree che la ricerca biologica richiede maggiore precisione, controllo metodologico e capacità di evitare errori che potrebbero compromettere un esperimento o una decisione di sviluppo.
Il benchmark mostra inoltre una forte penalizzazione quando il task include artefatti. GPT-Rosalind passa dal 45,1% di pass rate nei task solo testuali al 28,1% nei task con allegati o URL. Anche GPT-5.5 mostra un calo analogo, dal 29,9% al 21,9%. Il problema non è solo leggere un file, ma estrarre correttamente informazioni da figure, tabelle, sequenze, strutture chimiche e documenti complessi, per poi integrarle nella risposta finale. OpenAI indica questo punto come uno dei gap più evidenti dei modelli frontier nelle life sciences.
Le prestazioni peggiorano ulteriormente quando il task richiede output esatti. GPT-Rosalind raggiunge soltanto il 14,8% nei task numerici e il 24,0% nei task che richiedono sequenze o strutture. La generazione di costrutti biologici resta fragile, con un pass rate del 27,3% e un miglioramento limitato rispetto a GPT-5.5. Questo è un limite tecnico importante perché molte attività biomediche richiedono output direttamente utilizzabili, come progettazione di donor per CRISPR/HDR, sequenze di siRNA, costrutti genetici, calcoli quantitativi o strutture molecolari con vincoli precisi. In questi casi un piccolo errore di calcolo, formato o sequenza può rendere inutilizzabile il risultato.
Un aspetto interessante è che i modelli spesso producono risposte parzialmente valide senza superare il task. In circa il 14% dei compiti, i modelli ottengono credito sostanziale dalla rubrica pur restando sotto la soglia di successo. Per GPT-Rosalind, 109 task hanno un pass rate inferiore al 20% ma almeno il 50% di reward nella rubrica. Questo significa che il modello può individuare elementi scientificamente rilevanti, sintetizzare correttamente una parte dell’evidenza o produrre ragionamento utile, ma fallire perché manca un vincolo chiave, usa una prova sbagliata, non completa un calcolo o non traduce il ragionamento in una decisione operativa sufficiente.
LifeSciBench si collega direttamente all’evoluzione di GPT-Rosalind come modello specializzato. Nell’aggiornamento del 3 giugno 2026, OpenAI ha spiegato che GPT-Rosalind combina le capacità di coding agentico e uso di strumenti di GPT-5.5 con una maggiore intelligenza nei domini centrali della drug discovery, in particolare chimica medicinale e genomica. L’obiettivo è supportare workflow che attraversano letteratura, dati sperimentali, omiche, sequenze, strutture, pathway e risultati biologici.
OpenAI ha affiancato LifeSciBench ad altre valutazioni specializzate. In MedChemBench, dedicato a workflow realistici di chimica medicinale, GPT-Rosalind ottiene il 27,5% contro il 25,1% di GPT-5.5, usando il 7,2% di token in meno. MedChemBench valuta comprensione multimodale di strutture chimiche, relazioni struttura-attività, predizione di potenza, tossicità, ADME, decisioni di lead optimization multiparametrica e retrosintesi. In GeneBench, focalizzato su analisi agentiche long-horizon in genomica e biologia quantitativa, GPT-Rosalind raggiunge il 21,6% contro il 20,4% di GPT-5.5, usando il 31% di token in meno. GeneBench comprende task in genomica funzionale, trascrittomica spaziale, proteomica, epigenomica e genetica applicata.
OpenAI ha introdotto anche LabWorkBench, una valutazione dedicata all’assistenza al lavoro di laboratorio reale. LabWorkBench misura la capacità del modello di collegare perturbazioni sperimentali a risultati osservati in protocolli wet lab, con finalità di troubleshooting e ottimizzazione. I dati usati da questa valutazione sono proprietari e quindi non contaminati dal training pubblico. In questo benchmark GPT-Rosalind ottiene il 63,2% contro il 55,8% di GPT-5.5, utilizzando il 5,3% di token in meno.
Il sistema non è pensato solo come modello conversazionale. OpenAI ha sviluppato due plugin, Life Sciences Research e Life Sciences NGS Analysis, per collegare GPT-Rosalind a workflow eseguibili e ripetibili. I plugin consentono recupero di evidenze con fonti, interpretazione biologica, esecuzione bioinformatica, conservazione degli artefatti e tracciabilità della provenance. Tutti gli utenti possono accedere ai plugin tramite Codex, mentre le organizzazioni enterprise qualificate possono usare GPT-Rosalind per alimentarli direttamente.
Il plugin Life Sciences NGS Analysis è progettato per trasformare dati e file biologici in workflow ispezionabili. OpenAI cita esempi come analisi di ctDNA in biopsia liquida, QC e annotazione di single-cell RNA-seq, controllo qualità di FASTQ bulk RNA-seq, generazione di bundle con MultiQC, matrici Salmon, provenance e caveat espliciti. L’azienda ha inoltre aggiunto viewer interattivi per file biologici nativi, inclusi visualizzatori di sequenze, allineamenti e strutture, in modo che il modello possa ragionare mantenendo in contesto l’artefatto attivo.
L’esempio applicativo descritto da OpenAI riguarda un workflow su biopsia liquida tumorale. Il plugin NGS Analysis analizza record ctDNA processati, costruisce un notebook interattivo, evidenzia alterazioni ricorrenti, chiamate a bassa frequenza e traiettorie dei campioni, fino a focalizzare l’indagine su KRAS G12C. Il plugin Life Sciences Research aggiunge poi contesto su target, inibitori e resistenza, mentre i viewer di sequenza, allineamento e struttura permettono di ispezionare il residuo mutante 12, la conservazione nella famiglia RAS e la tasca legata all’inibitore. Il workflow termina traducendo l’evidenza in opzioni concrete di follow-up, con ogni passaggio e artefatto disponibile per revisione esperta.
L’accesso a GPT-Rosalind resta controllato. OpenAI lo rende disponibile in research preview tramite una struttura di trusted access per organizzazioni idonee che conducono ricerca scientifica legittima con beneficio pubblico, governance e supervisione di sicurezza solide, controllo degli accessi e sicurezza enterprise. Tra le organizzazioni citate figura Novo Nordisk, che sta utilizzando capacità frontier per aiutare i ricercatori ad analizzare dataset complessi, individuare pattern utili e testare ipotesi più rapidamente. Mishal Patel, Group Vice President AI & Digital Innovation R&D di Novo Nordisk, ha sottolineato la necessità di modelli avanzati fondati su dati scientifici affidabili, collegati a strumenti validati e integrati nei workflow reali dei ricercatori.
OpenAI chiarisce però che LifeSciBench non misura direttamente l’impatto finale sulla ricerca reale. Il benchmark valuta task auto-contenuti che riflettono workflow ricorrenti dell’industria, ma non cattura l’intera dinamica di un programma scientifico vivo, dove i ricercatori raccolgono nuove evidenze, modificano ipotesi, progettano esperimenti successivi e adattano le decisioni in più cicli. Per misurare se i modelli accelerano davvero la scoperta o migliorano gli esiti R&D, saranno necessari studi di deployment in ambienti di ricerca reali, su orizzonti più lunghi e con più round di ragionamento, feedback e verifica sperimentale.
Il risultato tecnico più importante è quindi duplice. Da un lato, LifeSciBench mostra che GPT-Rosalind supera GPT-5.5 in task complessi di life sciences e che la specializzazione del modello produce vantaggi misurabili in comunicazione scientifica, ricerca traslazionale, uso dell’incertezza e output utili agli esperti. Dall’altro lato, il benchmark quantifica con precisione i limiti ancora aperti: uso di artefatti, calcoli esatti, sequenze, strutture, progettazione sperimentale, ottimizzazione e predizione restano aree in cui anche il modello migliore fallisce spesso. Per OpenAI, LifeSciBench diventa così non solo uno strumento di valutazione, ma una mappa tecnica delle capacità e delle carenze dei modelli AI applicati alla ricerca biomedica.