La stima della posa umana si riferisce a una tecnologia – abbastanza nuova, ma in rapida evoluzione – che gioca un ruolo significativo nelle applicazioni di fitness e danza, permettendoci di posizionare i contenuti digitali nel mondo reale.
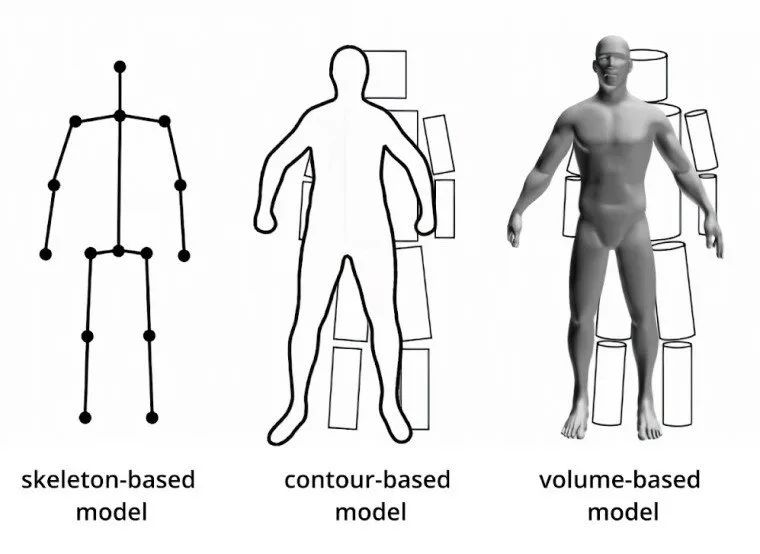
In breve, il concetto di stima della posa umana è una tecnologia basata sulla visione artificiale in grado di rilevare ed elaborare la postura umana. La parte più importante e centrale di questa tecnologia è la modellazione del corpo umano. Tre modelli corporei sono i più importanti all’interno degli attuali sistemi di stima della posa umana: basato sullo scheletro, sul contorno e sul volume.
Modello basato su scheletro
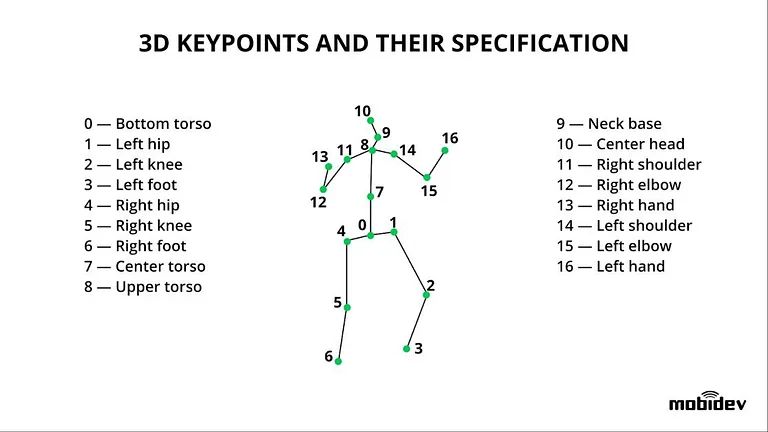
Questo modello è costituito da una serie di articolazioni (punti chiave), come ginocchia, caviglie, polsi, gomiti, spalle e l’orientamento degli arti del corpo. Questo modello si distingue per la sua flessibilità e come tale è adatto per la stima della posa umana sia tridimensionale che bidimensionale. Con la modellazione tridimensionale, la soluzione utilizza un’immagine RGB e trova le coordinate X, Y e Z dei giunti. Con la modellazione bidimensionale, è la stessa analisi di un’immagine RGB, ma utilizzando le coordinate X e Y.
Modello basato sui contorni
Questo modello utilizza i contorni del busto e degli arti del corpo, nonché la loro larghezza ruvida. Qui, la soluzione prende la sagoma del telaio del corpo e rende le parti del corpo come rettangoli e confini all’interno di quel quadro.
Modello basato sul volume
Questo modello utilizza generalmente una serie di scansioni tridimensionali per catturare la forma del corpo e la converte in una struttura di forme e mesh geometriche. Queste forme creano una serie 3D di pose e rappresentazioni del corpo.
Come funziona la stima della posa umana in 3D
Le applicazioni per il fitness tendono a fare affidamento sulla stima tridimensionale della posa umana. Per queste app, maggiori sono le informazioni sulla posa umana, meglio è. Con questa tecnica, l’utente dell’app registrerà se stesso mentre partecipa a un esercizio oa una routine di allenamento. L’app analizzerà quindi i movimenti del corpo dell’utente, offrendo correzioni per errori o imprecisioni.
Questo tipo di diagramma di flusso dell’app segue in genere questo modello:
Innanzitutto, raccogli i dati sui movimenti dell’utente mentre esegue l’esercizio.
Successivamente, determina quanto sono stati corretti o errati i movimenti dell’utente.
Infine, mostra all’utente tramite l’interfaccia quali errori potrebbe aver commesso.
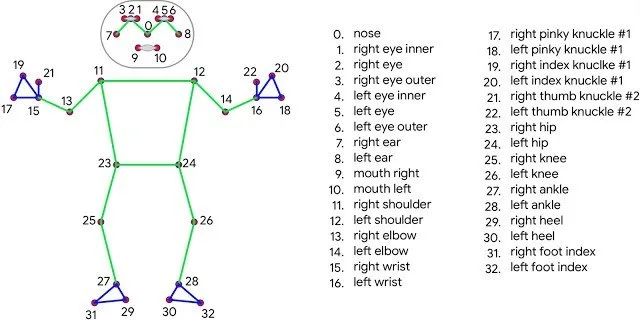
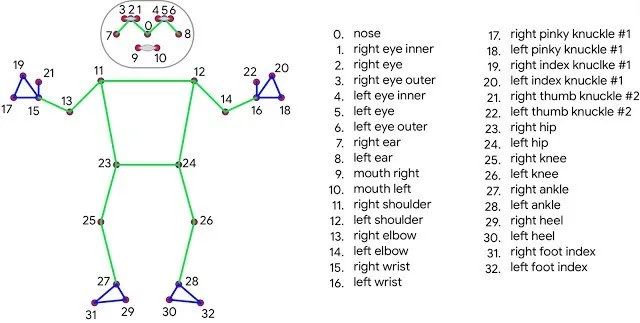
In questo momento, lo standard nella tecnologia della posa umana è la topologia COCO . La topologia COCO è composta da 17 punti di riferimento su tutto il corpo, che vanno dal viso alle braccia alle gambe. Si noti che COCO non è l’unico schema di posa del corpo umano, ma solo quello più comunemente usato.
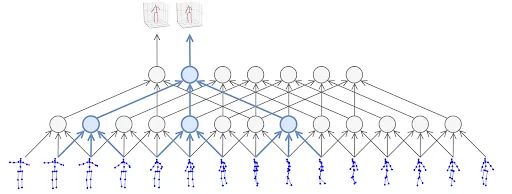
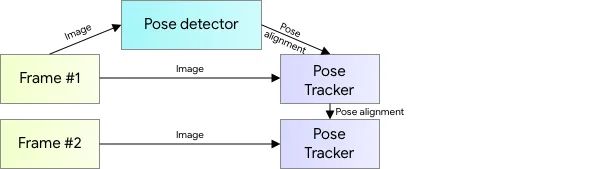
Questo tipo di processo utilizza tipicamente la tecnologia di deep machine learning per l’estrazione delle articolazioni nella stima della posa dell’utente. Quindi utilizza algoritmi basati sulla geometria per dare un senso a ciò che viene trovato (analizzare le posizioni relative dei giunti rilevati). Durante l’utilizzo di un video dinamico come dati sorgente, il sistema può utilizzare una serie di fotogrammi, non solo una singola immagine, per catturarne i punti chiave. Il risultato è un rendering molto più accurato dei movimenti reali dell’utente poiché il sistema può utilizzare le informazioni dei frame adiacenti per risolvere eventuali incertezze riguardanti la posizione del corpo umano nel frame corrente.
Tra le attuali tecniche per l’utilizzo della stima della posa 3D nelle applicazioni di fitness, l’approccio più accurato consiste nell’applicare prima un modello per rilevare i punti chiave 2D e successivamente elaborare il rilevamento 2D con un altro modello per convertirli in previsioni dei punti chiave 3D.
Nella ricerca che abbiamo pubblicato di recente, è stata utilizzata un’unica sorgente video, con reti neurali convoluzionali con convoluzioni temporali dilatate applicate per eseguire la conversione dei punti chiave 2D -> 3D.
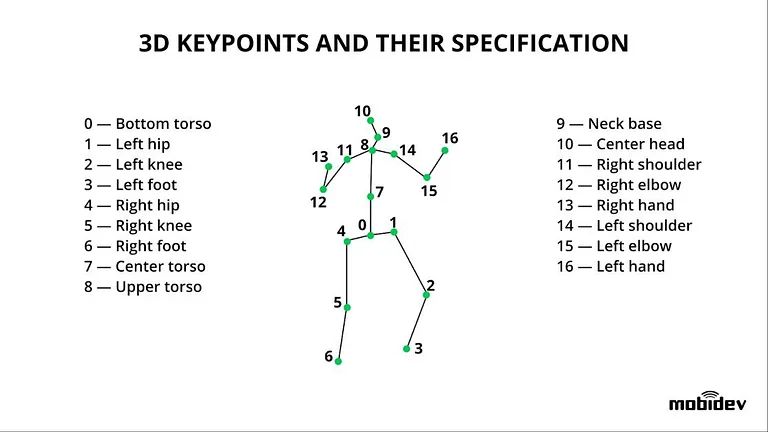
Dopo aver analizzato i modelli attualmente disponibili, abbiamo stabilito che VideoPose3D è la soluzione più adatta alle esigenze della maggior parte delle applicazioni di fitness basate sull’intelligenza artificiale. L’input che utilizza questo sistema dovrebbe consentire il rilevamento di un set 2D di punti chiave, in cui un modello, pre-addestrato sul set di dati COCO 2017, viene applicato come rilevatore 2D.
Per la previsione più precisa della posizione di un’articolazione o di un punto chiave corrente, VideoPose3D può utilizzare più fotogrammi in una breve sequenza di tempo per generare informazioni sulla posa 2D.
Per aumentare ulteriormente la precisione della stima della posa 3D, più di una telecamera può raccogliere punti di vista alternativi dell’utente che esegue lo stesso esercizio o routine. Si noti, tuttavia, che richiede una maggiore potenza di elaborazione e un’architettura del modello specializzata per gestire più ingressi di flusso video.
Recentemente, Google ha presentato il suo sistema BlazePose, un modello orientato ai dispositivi mobili per stimare la posa umana aumentando il numero di punti chiave analizzati a 33, un superset del set di punti chiave COCO e altre due topologie: BlazePalm e BlazeFace. Di conseguenza, il modello BlazePose può produrre risultati di previsione della posa coerenti con i modelli della mano e del viso articolando la semantica del corpo.
Ogni componente all’interno di un sistema di stima della posa umana basato sull’apprendimento automatico deve essere veloce, impiegando un massimo di un paio di millisecondi per fotogramma per il rilevamento della posa e i modelli di tracciamento.
A causa del fatto che la pipeline BlazePose (che include la stima della posa e i componenti di tracciamento) deve funzionare su una varietà di dispositivi mobili in tempo reale, ogni singola parte della pipeline è progettata per essere molto efficiente dal punto di vista computazionale e funzionare a 200-1000 FPS .
La stima della posa e il monitoraggio nel video in cui non è noto se e dove la persona è presente viene in genere eseguita in due fasi.
Nella prima fase, viene eseguito un modello di rilevamento di oggetti per localizzare la presenza di un essere umano o per identificare la loro assenza. Dopo che la persona è stata rilevata, il modulo di stima della posa può elaborare l’area localizzata contenente la persona e prevedere la posizione dei punti chiave.
Uno svantaggio di questa configurazione è che richiede sia il rilevamento degli oggetti che i moduli di stima della posa per essere eseguiti per ogni fotogramma che consuma risorse di calcolo extra. Gli autori di BlazePose, tuttavia, hanno escogitato un modo intelligente per aggirare questo problema e utilizzarlo in modo efficiente in altri moduli di rilevamento dei punti chiave come FaceMesh e MediaPipe Hand .
L’idea è che un modulo di rilevamento di oggetti (rilevatore di volti nel caso di BlazePose) possa essere utilizzato solo per avviare il tracciamento della posa nel primo fotogramma mentre il successivo tracciamento della persona può essere eseguito utilizzando esclusivamente le previsioni di posa dopo un certo allineamento di posa, parametri per i quali sono previsti utilizzando il modello di stima della posa.
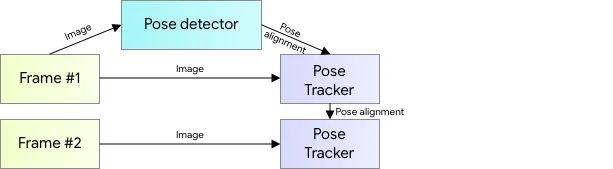
La faccia produce il segnale più forte per quanto riguarda la posizione del busto per la rete neurale, a causa della variazione relativamente piccola nell’aspetto e dell’alto contrasto nelle sue caratteristiche. Di conseguenza, è possibile creare un sistema rapido e basso per il rilevamento della posa attraverso una serie di presupposti giustificabili fondati sull’idea che la testa umana sarà localizzabile in ogni caso d’uso personale.
Superare le sfide della stima della posa umana
Fare uso della stima delle pose nelle app per il fitness affronta la sfida dell’enorme volume della gamma di pose umane, ad esempio, le centinaia di asana nella maggior parte dei regimi di yoga.
Inoltre, il corpo a volte blocca determinati arti come catturato da una determinata telecamera, gli utenti possono indossare abiti vari che oscurano le caratteristiche del corpo e l’aspetto personale.
Durante l’utilizzo di modelli pre-addestrati, notare che movimenti del corpo insoliti o angoli di ripresa strani possono portare a errori nella stima della posa umana . Possiamo mitigare questo problema in una certa misura utilizzando dati sintetici da un rendering 3D del modello del corpo umano o perfezionando i dati specifici per il dominio in questione.
La buona notizia è che possiamo evitare o mitigare la maggior parte dei punti deboli. La chiave per farlo è scegliere i dati di addestramento e l’architettura del modello corretti. Inoltre, la tendenza allo sviluppo nel campo della tecnologia di stima della posa umana suggerisce che alcuni dei problemi che dobbiamo affrontare ora saranno meno rilevanti nei prossimi anni.
L’ultima parola
La stima della posa umana contiene una varietà di potenziali usi futuri al di fuori dell’area delle app per il fitness e del monitoraggio dei movimenti umani, dai giochi all’animazione, dalla realtà aumentata alla robotica. Questo non rappresenta un elenco completo delle possibilità, ma evidenzia alcune delle aree più probabili in cui la stima della posa umana contribuirà al nostro panorama digitale.