I ricercatori della Corea del Sud hanno utilizzato tecniche di apprendimento automatico per sviluppare una tastiera “invisibile” per dispositivi mobili con spazio limitato che consente agli utenti di digitare il 157,5% più velocemente, anche se sullo schermo non è visibile alcuna tastiera.
La risposta degli utenti al nuovo metodo – chiamato semplicemente Invisible Mobile Keyboard (IMK) – è stata segnalata come molto positiva, con gli utenti del test che hanno riportato bassi livelli di richiesta fisica, mentale e temporale durante l’utilizzo della tastiera. In termini di efficienza, IMK supera leggermente il più recente metodo di input alternativo all’avanguardia, raggiungendo un punteggio all’avanguardia di 51,6 parole al minuto.
La tastiera fantasma
Per iniziare a generare input, gli utenti possono semplicemente iniziare a digitare sullo schermo, come se fosse visibile una tastiera (anche se non lo è). Non viene visualizzato nulla per ostacolare la visualizzazione del contenuto e le parole digitate appariranno in qualsiasi casella di testo ricettiva in cui ha origine la digitazione e, facoltativamente, come un sottile flusso di testo che l’utente può verificare per la precisione.
Il sistema si autocalibra dal momento in cui riconosce l’input. Pertanto, l’utente può avere il dispositivo mobile in modalità orizzontale o verticale e utilizzare l’intero spazio disponibile sullo schermo per digitare il testo.
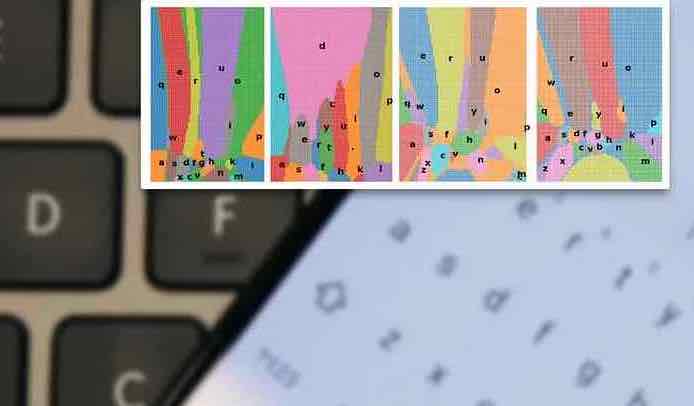
Questo è un esempio di IMK nella fase di raccolta dei dati, sebbene funzioni in modo identico nell’utilizzo finale. La tastiera che appare è solo a scopo illustrativo e non appare all’utente né durante il processo di raccolta dei dati né nell’utilizzo finale dell’interfaccia . Fonte: https://www.youtube.com/watch?v=PuhiVGOfIR0
Digitare come sistema di coordinate
La ricerca proviene dal Korea Advanced Institute of Science and Technology (KAIST) e sfrutta la nostra capacità naturale di “tracciare” dove si trova il tasto successivo su una tastiera. Sebbene possa sembrare controintuitivo nascondere la tastiera e aspettarsi che il dito di un utente trovi il tasto successivo desiderato, in realtà anche un dattilografo medio punta istintivamente al carattere corretto.
In effetti, IMK tratta la tastiera come una matrice di trama e gli autori hanno compilato un ampio database di input dell’utente al fine di fornire dati per il decodificatore di caratteri neurali di autoattenzione (SA-NCD) del sistema su cui allenarsi.
SA-NCD annoterà la posizione di una “caduta chiave” e calcolerà la probabilità della chiave desiderata. Man mano che le parole si accumulano attraverso le sequenze di tasti, SA-NCD può compilare e suddividere i caratteri nelle parole che li compongono, pulendo l’input in tempo reale.
SA-NCD non aspetta il completamento di una possibile frase, poiché non ha idea di quando l’input della frase finirà, e quando una o più parole vengono aggiunte alla frase, può rivisitare e riscrivere interpretazioni precedenti dal sentenza alla luce degli ultimi input.
Banca dati
Per alimentare il processo di formazione, i ricercatori hanno raccolto circa due milioni di paia di punti di contatto e testo dai soggetti del test, che utilizzavano una semplice interfaccia basata sul Web accessibile da dispositivi mobili abilitati al tocco.
Il set di dati contiene le iniziali del nome dell’utente, le dimensioni dello schermo del suo dispositivo, la sua età, il tipo di dispositivo mobile utilizzato (ad es. tablet, smartphone, ecc.) e i valori delle coordinate x e y di ciascuna keyfall registrata.
Posizioni medie di keyfall tra gli utenti, con punti di colore identico che indicano keyfall da parte degli stessi utenti. L’identificazione dei dati dello stesso utente aiuta a ottimizzare il set di dati ed evitare l’overfitting confrontando i raggruppamenti di keyfall medi dei singoli utenti, piuttosto che addestrare le sequenze di tasti di un utente l’una contro l’altra.
La formazione doveva tenere conto delle notevoli variazioni nella distanza media dei pixel tra i tratti tra gli utenti. Alcuni utenti, forse quelli abituati a tastiere software molto anguste, hanno mantenuto una distanza media tra i tasti di soli 50 pixel sull’asse z, mentre altri una media di 300 pixel.
Queste differenze sono critiche, poiché nel caso dell’asse Y, un errore collocherebbe la chiave sulla riga sbagliata, sostituendo, ad esempio, una ‘I’ o una ‘M’ per la corsa ‘K’ prevista.
Architettura e Formazione
SA-NCD è costituito da due moduli di decodifica: un decodificatore geometrico, che calcola dove sulla tastiera invisibile doveva cadere un tasto; e un decodificatore semantico, che gestisce l’interpretazione dal vivo del testo di input.
Il decodificatore geometrico utilizza GRU Bidirezionale ( BiGRU ), con GRU adottato come Rete Neurale Ricorrente ( RNN ), con passaggi avanti e indietro che facilitano un’interpretazione in continua evoluzione della frase.
Il componente semantico utilizza un’architettura Transformer , che interpreta l’input dopo che è passato attraverso un processo di “mascheramento della fiducia” progettato per confrontare l’utilizzo medio con il nuovo keyfall specifico. Il decodificatore semantico è stato addestrato come modello di linguaggio a caratteri mascherati rispetto al One Billion Word Benchmark , una collaborazione del 2014 tra Google, l’Università di Cambridge e l’Università di Edimburgo.
Risultati
Nei test, gli utenti sono stati in grado di digitare il 157,5% più velocemente utilizzando IMK rispetto alle tastiere software di terze parti sui propri smartphone. Inoltre, è stato scoperto che IMK ha superato i risultati ottenuti da nuovi metodi rivali, come i metodi di immissione di testo basati su gesti, touch e a dieci dita degli ultimi anni. Il documento riporta che gli utenti hanno mostrato un’elevata soddisfazione per il sistema.