Memorie emergenti e intelligenza artificiale
Tom Coughlin
Il 29 agosto 2019 ho tenuto un seminario su Emerging Memories and Artificial Intelligence presso la Stanford University, organizzato dal Stanford Center for Magnetic Nanotechnology e Coughlin Associates. Abbiamo avuto diversi oratori interessanti che parlavano di vari tipi di intelligenza artificiale e del ruolo che le nuove memorie non volatili svolgeranno sia nell’addestramento dei modelli di intelligenza artificiale che nella loro attuazione sul campo utilizzando i motori di inferenza. Questo pezzo parlerà di parte del materiale presentato in questo seminario.
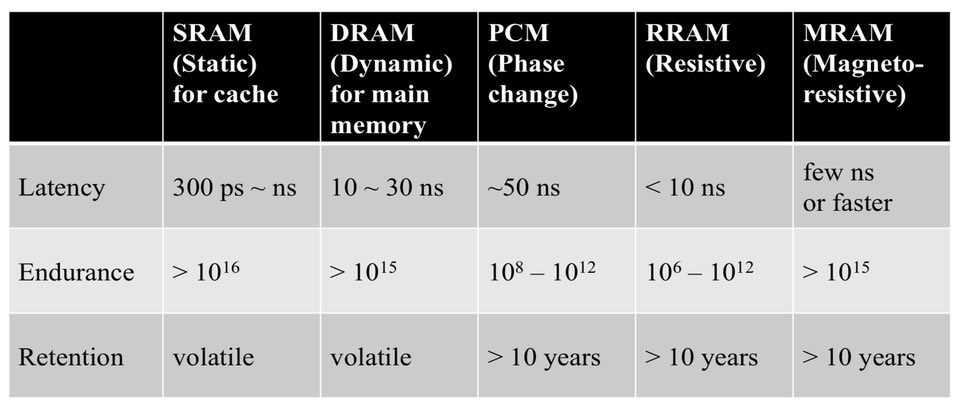
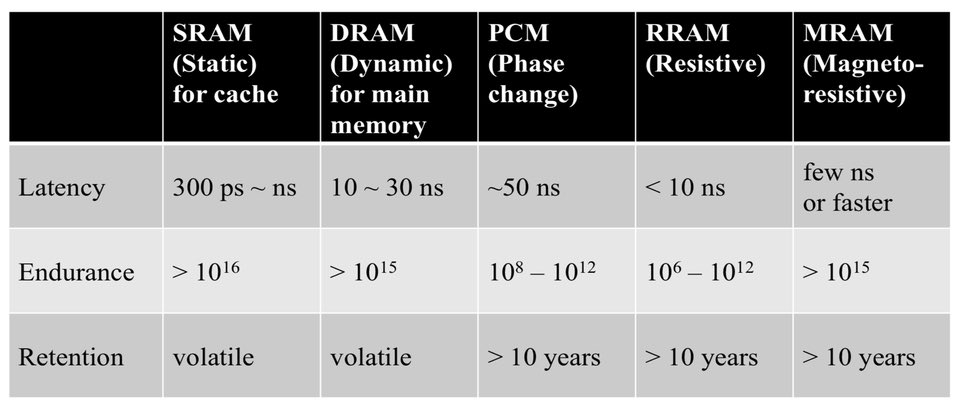
La dott.ssa Shan Wang, co-organizzatore dell’evento, ha fatto una presentazione, parlando di memorie non volatili emergenti e in particolare sulla memoria ad accesso casuale magnetico (MRAM). Ha parlato di come funzionano vari nuovi ricordi, in particolare Resistive RAM (RRAM), Phase Change Memory (PCM), MRAM e Ferrroelectic RAM (FRAM). Ha affermato che gli attuali requisiti di potenza della memoria volatile, in particolare l’energia statica, sono aumentati con caratteristiche litografiche a semiconduttore più piccole. Di tutte queste nuove memorie, MRAM è promettente per la sostituzione di SRAM e DRAM o come complemento di queste memorie e consente un funzionamento a bassa potenza, come mostrato nella tabella seguente.
Mentre MRAM promette di sostituire o integrare DRAM e SRAM, PCM e RRAM potrebbero fornire una maggiore capacità e una memorizzazione più lenta e possono anche essere utilizzati come acceleratori analogici di AI (elaborazione neuromorfa).
Il discorso del Dr. Wang ha esplorato la fisica della tecnologia magnetoresistiva, che è di uso comune per la lettura dei dati nei dischi rigidi. Ha discusso delle differenze tra le valvole di spin utilizzate nelle testine HDD e le giunzioni del tunnel magnetico utilizzate nei dispositivi MRAM. La prossima generazione di dispositivi MRAM si basa sul trasferimento della coppia di spin e sull’energia termica ambientale per commutare i dispositivi di memoria. Questi dispositivi stanno ora entrando in produzione come dispositivi discreti da 1 Gb e come opzione di memoria per sostituire NOR e alcune cache SRAM di livello superiore. I futuri dispositivi MRAM useranno una tecnologia chiamata Spin Orbit Transfer (SOT), che è in grado di cambiare molto più velocemente, consentendo eventualmente la sostituzione completa della memoria volatile SRAM di oggi. SOT MRAM può avere tempi di commutazione nel range di picosecondi (ps), tanto quanto SRAM.
Il dottor Deliang Fan, dell’Università dell’Arizona, ha parlato di elaborazione in memoria ad alta efficienza energetica, in particolare con acceleratori in memoria con elaborazione parallela. Ha chiamato questa architettura di Processing-in-Memory (PIM). Ha anche esplorato un accoppiamento molto stretto tra elaborazione e memoria, in particolare con i dispositivi Spintronic in grado di combinare funzioni logiche e di memoria in grado di eseguire operazioni di lettura / scrittura della memoria e operazioni logiche AND / OR. Gli sforzi di ricerca della logica in memoria includono Pinatubo, che utilizza memoria non volatile.
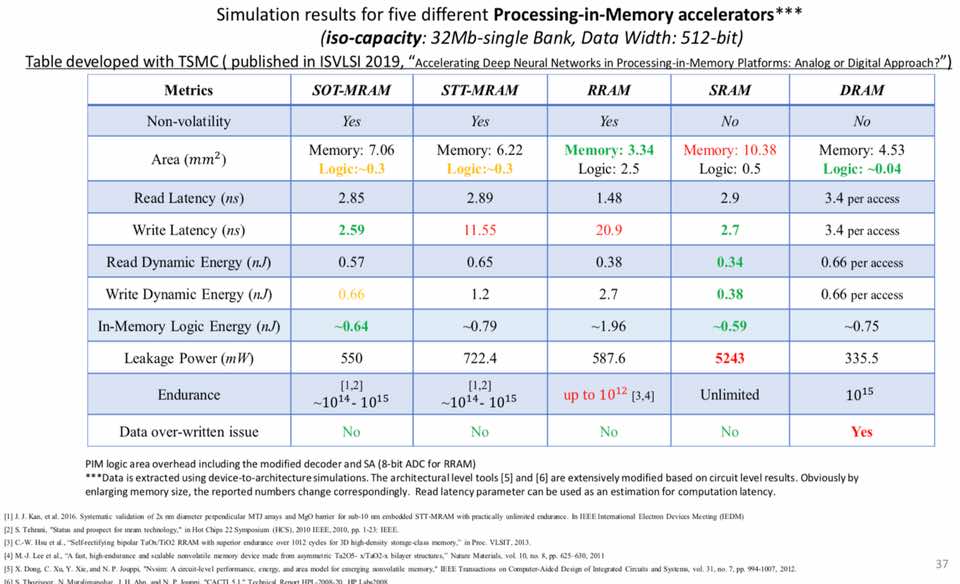
La tabella seguente confronta alcuni dati di simulazione per gli acceleratori di elaborazione in memoria che utilizzano memorie non volatili e volatili. Il risultato SOT-MRAM è molto promettente per un sistema ad alte prestazioni, simile alla simulazione SRAM. Ha anche parlato di come si possano realizzare migliori modelli di apprendimento dell’IA che funzionano a bassa potenza (reti neurali profonde) con approcci PIM.
Il dott. Hsinyu (Sidney) Tsai, del centro di ricerca IBM Almaden, ha fornito una rassegna completa del funzionamento degli acceleratori di dispositivi di memoria analogica DNN (deep neural network), in particolare utilizzando PCM come tecnologia di memoria. Si noti che IBM ha lavorato per diversi anni su chip di memoria neuromorfi basati su PCM. Le funzioni analogiche fornite da queste memorie sono chiamate accumulo multiplo. Questa tecnica può essere applicata per l’allenamento diretto della rete neurale e comporta inferenze in avanti basate su allenamenti precedenti, propagazione all’indietro di errori da queste inferenze per correggere la matrice di pesi utilizzata per il passaggio dell’inferenza. Ha sottolineato quanto sia possibile ottenere un’elevata precisione DNN nonostante i dispositivi PCM imperfetti.
Il Dr. Any Steinbach della startup Paradigm Shift AI ha tenuto un discorso interessante sul funzionamento dettagliato dell’apprendimento automatico su come può essere applicato nel settore dei semiconduttori. In particolare ha discusso di come può essere utilizzato per correggere i difetti di adesione litografica e la pianificazione dei lotti di produzione, in particolare utilizzando le informazioni sui sensori IoT industriali.
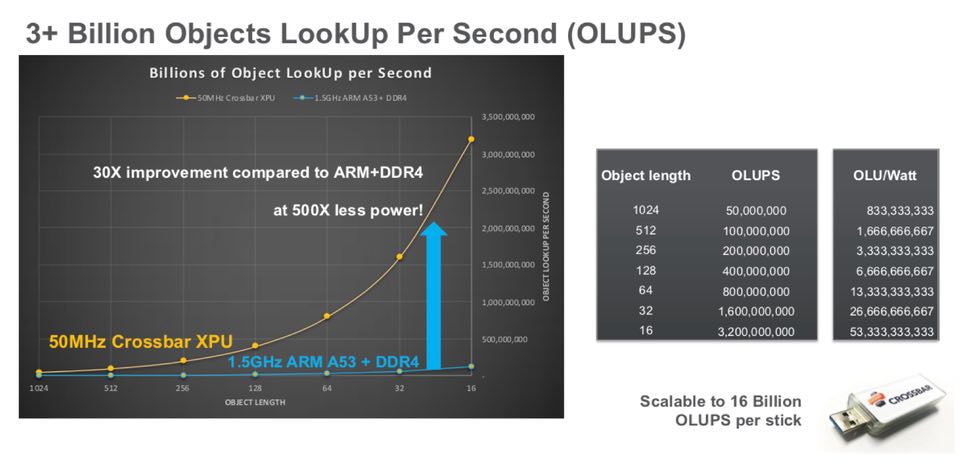
Sylvain Debois di Crossbar (un espositore del seminario) ha parlato dell’utilizzo di acceleratori di calcolo near-memory per un apprendimento automatico più rapido utilizzando la tecnologia RRAM di Crossbar in un array di memoria altamente parallelo. A dimostrazione di questo approccio, la società ha costruito una chiavetta USB con quella che la società chiama la sua XPU Crossbar per mostrare miglioramenti significativi nella velocità di ricerca degli oggetti (OLUPS) rispetto al processore ARM che opera a una frequenza operativa molto più alta, come mostrato di seguito.
Confronto di ricerca dell’oggetto della barra trasversale per ARM contro la barra trasversale XPU
Confronto di ricerca dell’oggetto della barra trasversale per ARM contro la barra trasversale XPU IMMAGINE DALLA PRESENTAZIONE DI STANFORD
Il Dr. Peter Corcoran dell’Università Nazionale d’Irlanda, Galway, ha parlato del perché l’IA at the Edge guiderà la necessità di archiviazione e larghezza di banda. Ha parlato dell’importanza dell’informatica svolta nel tessuto della memoria. Ha sottolineato che ora le reti AI possono essere integrate in un formato di scheda SD con un consumo di energia inferiore di 2 ordini rispetto alle GPU. Dal momento che Peter lavora sui sistemi di visione dei consumatori, ha parlato del miglioramento della tecnologia delle telecamere dei consumatori e dell’uso dell’elaborazione visiva locale per mettere l’AI al limite. Ha discusso di come la prossima generazione di queste telecamere possa includere reti neurali convoluzionali (CNN).
Il dottor Corcoran ha sottolineato che andare ancora oltre per creare immagini veramente realistiche e una migliore analisi delle immagini (ad esempio per il monitoraggio dei driver) richiederà notevoli risorse di elaborazione e memoria. La diapositiva seguente mostra alcune delle sue stime per le risorse di archiviazione e monitoraggio per fare ciò.
Mahendra Pakala di Applied Materials ha parlato delle apparecchiature di produzione utilizzate per creare memorie emergenti moderne come RRAM, MRAM e PCM e Andy Walker della startup MRAM Spin Memory ha parlato di come STT-MRAM può rendere l’IA accessibile, soprattutto dal punto di vista del consumo di energia.
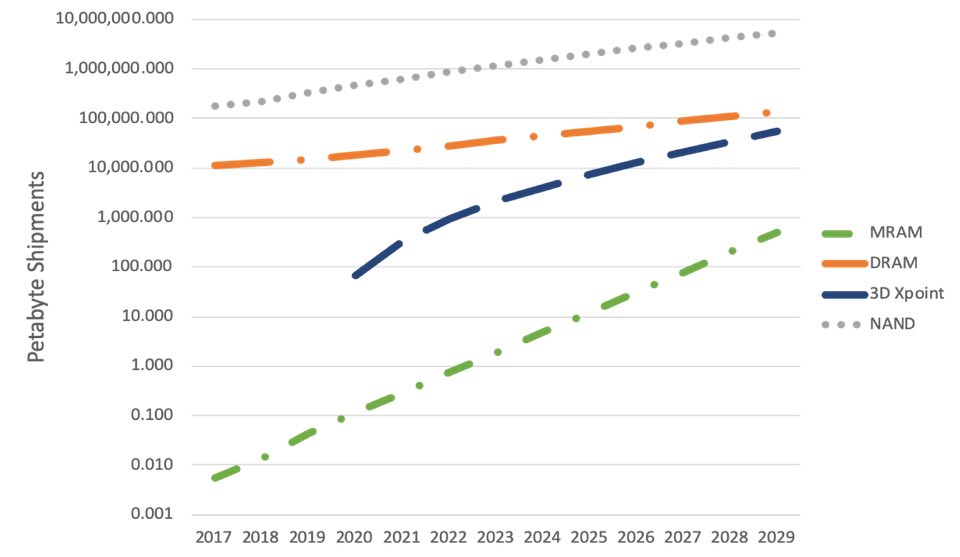
Il mio intervento ha concluso la giornata parlando di come le memorie emergenti consentano al mercato AI e proiezioni per la conseguente crescita di memorie emergenti, come MRAM e 3D XPoint, sulla base di un rapporto recentemente concluso sulla crescita della memoria emergente . Le proiezioni dei report sono mostrate di seguito.
Se ti trovi nella Bay Area di San Francisco e sei interessato a saperne di più sul ruolo delle memorie non volatili emergenti nell’applicazione di intelligenza artificiale e nel networking con professionisti dello storage, utenti dello storage e altre parti interessanti, potresti essere interessato alla cena della Storage Valley Riunione di club, 18 settembre 2019 a Techcode. Le iscrizioni sono aperte fino al 16 settembre .
I ricordi emergenti svolgeranno un ruolo importante nello sviluppo dell’IA e di altre applicazioni sia per l’apprendimento che per le applicazioni dei modelli di intelligenza artificiale nel mondo reale. Lo Stanford Workshop del 2019 ha fornito molte informazioni su come funzionano le varie IA e su come le nuove tecnologie di memoria possono essere integrate nei sistemi di intelligenza artificiale e nelle architetture di memoria / archiviazione per consentire la prossima generazione di data center e applicazioni client.