L’alternativa gratuita di GPT-3 GPT-Neo è qualcosa di cui essere entusiasti
L’avvento dei Transformers nel 2017 ha cambiato completamente il mondo delle reti neurali. Da allora, il concetto centrale di Transformers è stato remixato, riconfezionato e riassemblato in diversi modelli. I risultati hanno superato lo stato dell’arte in diversi benchmark di machine learning. In effetti, attualmente tutti i principali benchmark nel campo dell’elaborazione del linguaggio naturale sono dominati da modelli basati su Transformer. Alcuni dei modelli della famiglia Transformer sono BERT , ALBERT e la serie di modelli GPT .
In qualsiasi modello di machine learning, i componenti più importanti del processo di formazione sono:
Il codice del modello: i componenti del modello e la sua configurazione
I dati da utilizzare per l’addestramento
La potenza di calcolo disponibile
Con la famiglia di modelli Transformer, i ricercatori sono finalmente arrivati a un modo per aumentare le prestazioni di un modello all’infinito: basta aumentare la quantità di dati di addestramento e la potenza di calcolo.
Questo è esattamente ciò che ha fatto OpenAI, prima con GPT-2 e poi con GPT-3. Essendo un’azienda ben finanziata ($ 1 miliardo +), potrebbe permettersi di addestrare alcuni dei più grandi modelli del mondo. Per l’addestramento del modello è stato utilizzato un corpus privato di 500 miliardi di token e circa 50 milioni di dollari sono stati spesi in costi di elaborazione.
Sebbene il codice per la maggior parte dei modelli in linguaggio GPT sia open source, il modello è impossibile da replicare senza l’enorme quantità di dati e la potenza di calcolo. E OpenAI ha scelto di negare l’accesso pubblico ai suoi modelli addestrati, rendendoli disponibili tramite API solo a poche aziende e individui selezionati. Inoltre, la sua politica di accesso è priva di documenti, arbitraria e opaca.
Genesi di GPT-Neo
Stella Biderman, Leo Gao, Sid Black e altri hanno formato EleutherAI con l’idea di realizzare una tecnologia di intelligenza artificiale che fosse open source per il mondo. Uno dei primi problemi che il team ha scelto di affrontare è stato creare un modello di linguaggio simile a GPT che fosse accessibile a tutti.
Come accennato in precedenza, la maggior parte del codice per un modello di questo tipo era già disponibile, quindi le sfide principali erano trovare i dati e la potenza di calcolo. Il team di Eleuther ha deciso di generare un set di dati open source di una scala paragonabile a quella utilizzata da OpenAI per i suoi modelli di linguaggio GPT. Ciò ha portato alla creazione di The Pile . The Pile, rilasciato a luglio 2020, è un set di dati da 825 GB specificamente progettato per addestrare i modelli linguistici. Contiene dati da 22 diverse fonti, incluse fonti accademiche (Arxiv, PubMed, FreeLaw ecc.), Pagine web Internet (StackExchange, Wikipedia ecc.), Finestre di dialogo da sottotitoli, Github, ecc.
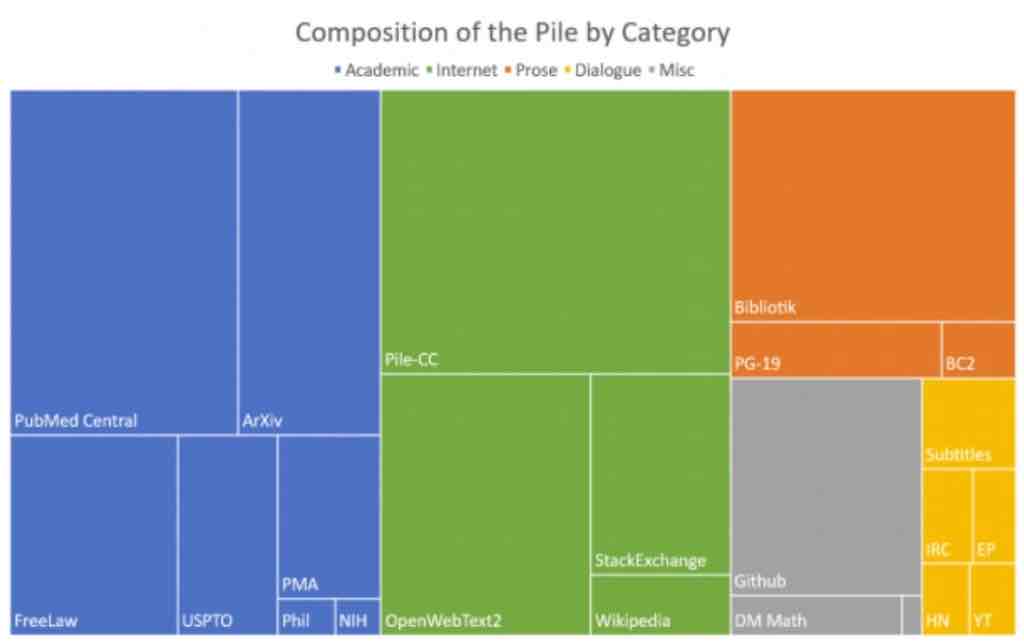
Fonte: carta The Pile, Arxiv .
Per il calcolo, EleutherAI è stata in grado di utilizzare il calcolo inattivo da TPU Research Cloud (TRC). TRC è un’iniziativa di Google Cloud che supporta progetti di ricerca con l’aspettativa che i risultati della ricerca vengano condivisi con il mondo tramite codice open source, modelli, ecc.
Il 22 marzo 2021, dopo mesi di meticolosa ricerca e formazione, il team di EleutherAI ha rilasciato due modelli linguistici in stile GPT addestrati, GPT-Neo 1.3B e GPT-Neo 2.7B. Il codice ei modelli addestrati sono open source con licenza MIT. E i modelli possono essere utilizzati gratuitamente utilizzando la piattaforma Transformers di HuggingFace .
Confronto tra GPT-Neo e GPT-3
Confrontiamo GPT-Neo e GPT-3 rispetto alle dimensioni del modello e ai benchmark delle prestazioni e infine guardiamo alcuni esempi.
Taglia del modello. In termini di dimensioni e calcolo del modello, il modello GPT-Neo più grande è costituito da 2,7 miliardi di parametri. In confronto, l’API GPT-3 offre 4 modelli, che vanno da 2,7 miliardi di parametri a 175 miliardi di parametri. Didascalia: dimensioni dei parametri GPT-3 come stimate qui e GPT-Neo come riportato da EleutherAI.
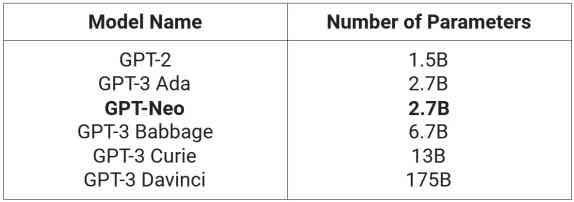
Come puoi vedere, GPT-Neo è più grande di GPT-2 e paragonabile al modello GPT-3 più piccolo.
Metriche di benchmark delle prestazioni. EleutherAI riferisce che GPT-Neo ha superato il modello GPT-3 comparabile più vicino (GPT-3 Ada) su tutti i benchmark di ragionamento NLP.
GPT-Neo ha superato GPT-3 Ada su Hellaswag e Piqa. Hellaswag è un benchmark intelligente di completamento di frasi a scelta multipla che ha un paragrafo contestuale e quattro finali. Piqa misura il ragionamento basato sul buon senso in cui la macchina deve scegliere una delle due frasi che hanno più senso. GPT-Neo ha anche superato GPT-3 Ada su Winogrande , un benchmark che utilizza il buon senso per risolvere pronomi ambigui in una frase.
Tuttavia GPT-3 Davinci, la versione più grande di GPT-3, con circa 65 volte più parametri, batte comodamente GPT-Neo in tutti i benchmark, come ci si aspetterebbe.
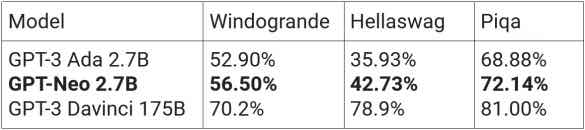
Didascalia: metriche del modello riportate da EleutherAI , ad eccezione di GPT-3 175B, che proviene dal documento GPT-3 di Open AI .
Esempi. Diamo un’occhiata ad alcuni esempi affiancati di testo generato dal più grande modello GPT-3 (da vari esempi GPT-3 Davincitrovati online) e GPT-Neo (che ho generato utilizzando l’implementazione di trasformatori GPT-Neo 2.7B di HuggingFace ) .
Il primo esempio che vedremo è il completamento di frasi in formato ELI-5, dove il testo in corsivo era il prompt dato al modello.

Direi che sia GPT-Neo che GPT-3 hanno funzionato altrettanto bene in questo esempio.
Il prossimo esperimento consiste nel verificare se GPT-Neo può correggere frasi grammaticalmente errate come può fare GPT-3 . Anche in questo caso le parti in corsivo sono il prompt fornito al modello.

Ancora una volta, GPT-Neo ha funzionato alla grande nel correggere “mangiare” per “mangiare”, soprattutto considerando che il modello non è stato specificamente addestrato per farlo.
Infine, la famosa “scoperta di unicorni di lingua inglese” (versione GPT-2 qui e versione GPT-3 qui ) reinventata e scritta da GPT-Neo. Il prompt fornito al modello è in corsivo e in grassetto.
In una scoperta scioccante, gli scienziati hanno scoperto un branco di unicorni che vivevano in una valle remota e inesplorata, nelle Ande. Ancora più sorprendente per i ricercatori è stato il fatto che gli unicorni parlavano un inglese perfetto.
L’unica prova era una sola parola: “ciao”.
“Gli unicorni sono ottimi ascoltatori, quindi hanno imparato a parlare inglese guardando gli umani”, ha detto il dottor David Orme, amministratore delegato della Zoological Society of London, in un comunicato stampa. “In effetti, hanno anche imparato a parlare spagnolo osservando gli umani. Ci hanno salutato in entrambe le lingue. “
Sebbene la scoperta sia sbalorditiva in sé e per sé, la notizia diventa ancora più strabiliante se si considera che gli unicorni sono stati lì per migliaia di anni. Erano “fossili viventi”, ha detto Orme, che è un modo elegante per dire che le loro origini devono ancora essere determinate.
“È estremamente eccitante che ora abbiamo le prove di una popolazione di unicorni, che sappiamo essere in giro e che sta vivendo”, ha detto in un comunicato stampa il dott. John Fitzpatrick, professore di conservazione e antropologia presso l’Università della California. “Questo dimostra che non sono solo un mito e che gli umani non sono l’unica specie sulla Terra ad aver sviluppato un linguaggio”.
I risultati sono stati pubblicati in un nuovo studio sulla rivista Proceedings of the Royal Society B: Biological Sciences.
Un “unicorno” dalle montagne andine in Colombia. (Immagine: The Royal Society)
La scoperta è stata fatta questa estate in una valle remota ma meravigliosa nelle montagne andine in Colombia chiamata Bureta. Si ritiene che gli unicorni avessero vent’anni. “È un posto molto insolito per trovare questi animali e al momento non ci sono prove che gli umani siano stati lì prima”, ha detto Orme.
Gli scienziati hanno detto che gli unicorni hanno vissuto in quella valle da quando esiste la loro specie, che è stimata in almeno 200.000 anni.
Ciò significa che la ricca storia della megafauna della zona, inclusi dinosauri, pterosauri e gatti dai denti a sciabola, è ancora lontana dall’essere conclusa.
“Se è vero in una valle relativamente isolata vicino a Bureta Colombia che ha più di 200.000 anni e ora ha anche una popolazione di questi animali, allora Bureta è davvero un posto unico e speciale”, ha detto Fitzpatrick.
Ancora una volta, GPT-Neo è stato in grado di generare un articolo coerente e quasi credibile senza perdere i temi centrali: la scoperta dell’unicorno, l’aspetto anglofono, le Ande, ecc.
Tutto sommato, le metriche delle prestazioni di GPT-Neo 2.7B nei benchmark NLP sono migliori di GPT-3 2.7B (Ada), ma molto peggiori del GPT-3 175B (Davinci). Ma qualitativamente, i completamenti e la scrittura di GPT-Neo 2.7B erano buoni quanto anche GPT-3 175B (Davinci), il modello GPT-3 più grande.
La linea di fondo qui è: GPT-Neo è un’ottima alternativa open source a GPT-3, soprattutto data la politica di accesso chiuso di OpenAI.