DeepSinger di Microsoft genera voci che possono cantare in inglese e cinese
Un team di ricercatori della Microsoft e della Zhejiang University ha recentemente sviluppato un sistema di sintesi vocale multilingue (SVS) multilingue chiamato DeepSinger . Il sistema è costruito da zero utilizzando i dati di allenamento del canto estratti da siti Web musicali.
Con l’avanzamento delle reti neurali profonde, Singing Voice Synthesis (SVS) genera voci di canto dai testi, che negli ultimi anni ha attratto molta trazione nel campo della ricerca e della comunità industriale. Questa tecnica è simile al metodo di sintesi vocale che consente alle macchine di parlare.
SVS tradizionale si basa principalmente su registrazioni e annotazioni umane e richiede un gran numero di registrazioni di canto di alta qualità come dati di allenamento, nonché rigidi allineamenti di dati tra testi e audio di canto per una modellazione accurata del canto. Ciò, di conseguenza, aumenta i costi dell’etichettatura dei dati e impedisce la ricerca e lo sviluppo di prodotti in questo settore. Queste continue sfide hanno portato allo sviluppo di un nuovo sistema SVS, DeepSinger.
DeepSinger, un sistema di sintesi vocale cantante creato da zero utilizzando i dati di allenamento del canto. La pipeline di DeepSinger consiste in diversi passaggi di data mining e modellazione. Loro sono:-
Scansione dei dati: al fine di ottenere un gran numero di canzoni da Internet, i ricercatori hanno eseguito la scansione di decine di migliaia di canzoni e dei loro testi dei migliori cantanti in tre lingue diverse, cinese, cantonese e inglese da un sito Web musicale.
Separazione di canto e accompagnamento: uno strumento di separazione musicale popolare , Spleeter è stato utilizzato per separare le voci di canto dagli accompagnamenti di brani.
Allineamento da testo a canto: un modello di allineamento è costruito per segmentare l’audio in frasi ed estrarre la durata del canto di ciascun fonema nei testi.
Filtraggio dei dati: i testi allineati e le voci di canto vengono quindi filtrati in base ai punteggi di confidenza in linea.
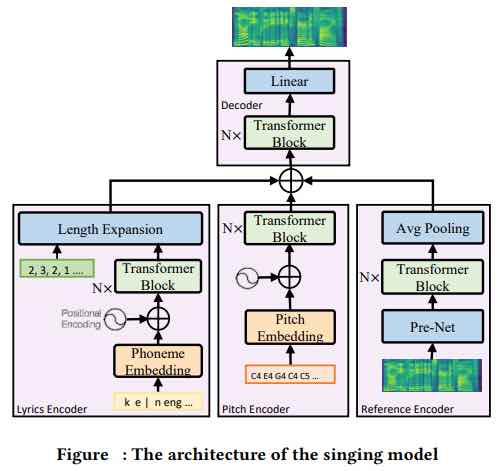
Modellazione del canto: viene creato un trasformatore feed-forward, basato sul modello di canto basato su FastSpeech, che sfrutta un codificatore di riferimento per gestire i dati rumorosi.
I ricercatori hanno progettato un modello di allineamento da testo a canto basato sul riconoscimento vocale automatico per estrarre automaticamente la durata di ciascun fonema nei testi a partire dal livello di frase a grana grossa fino al livello di fonema a grana fine.
Inoltre, hanno progettato un modello di canto multi-cantante multilingue basato su un Transformer feed-forward noto come FastSpeech per generare direttamente spettrogrammi lineari dai testi e sintetizzare voci usando Griffin-Lim, che è un vocoder popolare per ricostruire voci date lineari -spectrograms.
Vantaggi di DeepSinger
DeepSinger presenta numerosi vantaggi rispetto ai precedenti sistemi SVS. Sono menzionati di seguito: –
Secondo i ricercatori, DeepSinger è efficiente in termini di tempo poiché estrae direttamente i dati di allenamento dai siti Web musicali.
Evita qualsiasi sforzo umano per l’etichettatura di allineamento che è una tecnica economica.
DeepSinger è di natura semplice ed efficiente rispetto ai precedenti sistemi SVS.
Può sintetizzare voci di canto in diverse lingue e più cantanti.
Contributi di questa ricerca
I contributi di questo documento sono i seguenti: –
DeepSinger è il primo sistema SVS creato da dati estratti direttamente dal web, senza dati di canto di alta qualità registrati dall’uomo.
Il modello di allineamento da testo a canto evita qualsiasi sforzo umano per l’etichettatura di allineamento e riduce notevolmente i costi di etichettatura.
Il modello di canto basato su FastSpeech è semplice ed efficiente, rimuovendo la complessa modellazione di caratteristiche acustiche nella sintesi parametrica e sfruttando un codificatore di riferimento per catturare il timbro di un cantante da dati di canto rumorosi.
DeepSinger è in grado di sintetizzare voci di canto di alta qualità in più lingue e più cantanti.
Al fine di valutare l’efficacia del DeepSinger System, i ricercatori hanno utilizzato un set di dati di canto estratto dal Web che include 92 ore di dati con 89 cantanti e tre lingue. Secondo i ricercatori, i risultati sperimentali hanno dimostrato che DeepSinger è in grado di sintetizzare voci di canto di alta qualità in termini sia di precisione del tono che di naturalezza della voce.