DeepMind ha recentemente introdotto un nuovo approccio meta-learning che genera un algoritmo di apprendimento di rinforzo noto come Gradiente di politica acquisita (GPL). Secondo i ricercatori, automatizzare la scoperta di regole di aggiornamento dai dati potrebbe portare a algoritmi più efficienti che potrebbero anche essere adattati meglio ad ambienti specifici.
Quell’unica tecnica di apprendimento automatico che può essere paragonata al comportamento psicologico degli animali è l’ apprendimento di rinforzo . L’obiettivo dell’apprendimento per rinforzo è massimizzare i premi cumulativi previsti o i premi medi. Questo algoritmo ha guadagnato molta trazione da ricercatori e sviluppatori negli ultimi anni.
La ricerca nel campo dell’apprendimento per rinforzo è costata anni di ricerca manuale per aggiornare i parametri di un agente secondo una delle diverse regole possibili. L’automazione delle regole aggiornate è sempre stata una sfida significativa in questo settore e i ricercatori hanno cercato di scoprire alternative ai concetti fondamentali dell’apprendimento per rinforzo come le funzioni di valore e l’apprendimento delle differenze temporali. I ricercatori di DeepMind hanno ora affrontato questa sfida utilizzando un nuovo approccio.
Dietro il quadro
Secondo i ricercatori, questo nuovo approccio fa luce su una regola completamente nuova che include sia “cosa prevedere”, come le funzioni di valore e “come imparare da esso”, come il bootstrap interagendo con una serie di ambienti.
Hanno dichiarato : “Questo documento fa un passo verso la scoperta di algoritmi RL generici. Introduciamo un framework di meta-apprendimento che scopre congiuntamente sia “ciò che l’agente dovrebbe prevedere” sia “come utilizzare le previsioni per il miglioramento delle politiche” dai dati generati interagendo con una distribuzione di ambienti “.
L’obiettivo di questo approccio di meta-apprendimento è trovare la regola di aggiornamento ottimale dalla distribuzione dell’ambiente e dei parametri iniziali dell’agente. Rileva automaticamente gli algoritmi di apprendimento del rinforzo dai dati generati dall’interazione con una serie di ambienti.
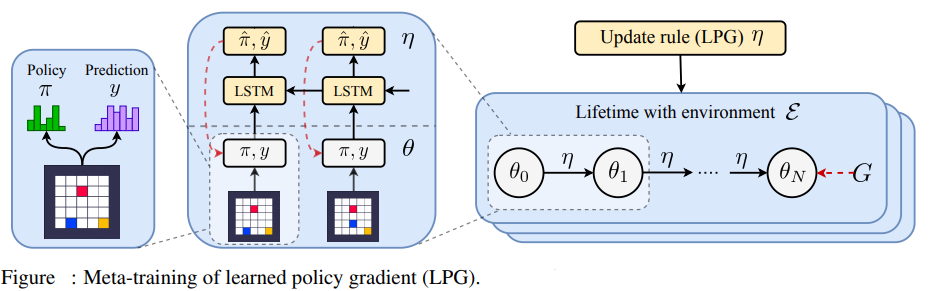
Gradiente di politica appresa (GPL)
Il risultato di questo approccio è l’ algoritmo di apprendimento del rinforzo noto come Gradiente di politica acquisita (GPL). GPL è una regola di aggiornamento parametrizzata da meta-parametri che richiede un
agente per produrre una politica e un vettore di previsione categoriale dimensionale. Questo nuovo algoritmo di apprendimento del rinforzo è una rete LSTM arretrata, che può aggiornare la politica e il vettore di previsione dalla traiettoria dell’agente.
Il GPL consente alla regola di aggiornamento di decidere quale dovrebbe essere la previsione del vettore dell’agente. Il framework di meta-learning scopre tali regole di aggiornamento da più agenti di apprendimento, ognuno dei quali interagisce con un ambiente diverso.
Contributi di questa ricerca
I contributi dei ricercatori a questo progetto sono menzionati di seguito-
Questa ricerca ha fatto il primo tentativo di meta-apprendere una regola di aggiornamento RL completa scoprendo congiuntamente sia cosa prevedere “sia” come avviare “.
L’approccio ha scoperto la propria alternativa al concetto di funzioni di valore.
Scopre un meccanismo di bootstrap per mantenere e usare le sue previsioni.
Se addestrato esclusivamente su ambienti giocattolo, il GPL si generalizza efficacemente con complessi giochi Atari e ottiene prestazioni non banali.
L’approccio ha il potenziale per accelerare il processo di scoperta di nuovi algoritmi di apprendimento per rinforzo.
Avvolgendo
I ricercatori hanno affermato che questa ricerca ha fatto il primo tentativo di meta-apprendere una regola di aggiornamento RL completa scoprendo sia “cosa prevedere” che “come avviare”, sostituendo i concetti RL esistenti come la funzione del valore e l’apprendimento delle differenze temporali. L’algoritmo ha la capacità di scoprire funzioni utili e di usarle in modo efficace per aggiornare la politica degli agenti.
Ad un impatto più ampio, si dice che l’approccio abbia il potenziale per accelerare notevolmente il processo di scoperta di nuovi algoritmi di apprendimento di rinforzo automatizzando il processo di scoperta in modo guidato dai dati. Inoltre, a causa della natura basata sui dati dell’approccio proposto, l’algoritmo risultante può acquisire distorsioni indesiderate nel set di formazione degli ambienti.
Inoltre, l’approccio proposto può anche servire da strumento per aiutare i ricercatori dell’apprendimento per rinforzo a sviluppare e migliorare i loro algoritmi progettati a mano fornendo approfondimenti su come appare una buona regola di aggiornamento a seconda dell’architettura fornita dai ricercatori come input, che potrebbe accelerare la scoperta manuale degli algoritmi RL.