Identificazione delle origini dati deepfake con il tagging basato sull’intelligenza artificiale
Una collaborazione tra ricercatori in Cina, Singapore e Stati Uniti ha prodotto un sistema resiliente per “etichettare” le foto dei volti in modo così robusto che i marcatori identificativi non vengono distrutti durante un processo di formazione deepfake , aprendo la strada a affermazioni sulla proprietà intellettuale che potrebbero intaccare il capacità dei sistemi di generazione di immagini sintetiche di “anonimizzare” dati di origine illegittimamente raschiati.
Il sistema, denominato FakeTagger , utilizza un processo di codifica/decodifica per incorporare informazioni ID visivamente indistinguibili nelle immagini a un livello sufficientemente basso da interpretare le informazioni iniettate come dati essenziali delle caratteristiche facciali, e quindi passare intatte attraverso processi di astrazione , allo stesso modo , ad esempio, come dati dell’occhio o della bocca.
Una panoramica dell’architettura FakeTagger. I dati di origine vengono utilizzati per generare una caratteristica facciale “ridondante”, ignorando gli elementi di sfondo che verranno mascherati attraverso un tipico flusso di lavoro deepfake. Il messaggio è recuperabile all’altro capo del processo, e identificabile attraverso un apposito algoritmo di riconoscimento.
La ricerca proviene dalla School of Cyber Science and Engineering di Wuhan, dal Key Laboratory of Aerospace Information Security and Trusted Computing presso il Ministero della Pubblica Istruzione cinese, dal Gruppo Alibaba negli Stati Uniti, dalla Northeastern University di Boston e dalla Nanyang Technological University di Singapore.
I risultati sperimentali con FakeTagger indicano un tasso di reidentificazione fino a quasi il 95% attraverso quattro tipi comuni di metodologie deepfake: identity swap (es. DeepFaceLab , FaceSwap ); rievocazione del volto; modifica degli attributi; e sintesi totale.
Difetti del rilevamento dei deepfake
Anche se negli ultimi tre anni hanno portato un raccolto di nuovi approcci per deepfake metodologie di identificazione, tutti questi approcci chiave sulle carenze rimediabili di deepfake flussi di lavoro, come ad esempio gli occhi luccichio nei modelli sotto-addestrato, e la mancanza di lampeggiante in precedenti deepfakes con volti insufficientemente diversificati. Man mano che vengono identificate nuove chiavi, i repository di software gratuiti e open source le hanno evitate, deliberatamente o come sottoprodotto dei miglioramenti nelle tecniche di deepfake.
Il nuovo documento osserva che il metodo di rilevamento post-fatto più efficace prodotto dalla più recente competizione di rilevamento dei deepfake (DFDC) di Facebook è limitato al 70% di precisione, in termini di individuazione di deepfake in natura. I ricercatori attribuiscono questo fallimento rappresentativo alla scarsa generalizzazione contro i nuovi e innovativi sistemi GAN e codificatore/decodificatore deepfake e alla qualità spesso degradata delle sostituzioni deepfake.
In quest’ultimo caso, ciò può essere causato da un lavoro di bassa qualità da parte dei deepfaker o da artefatti di compressione quando i video vengono caricati su piattaforme di condivisione che cercano di limitare i costi della larghezza di banda e ricodificano i video a bit rate drasticamente inferiori rispetto agli invii . Ironia della sorte, non solo questa degradazione dell’immagine non interferisce con l’apparente autenticità di un deepfake, ma può effettivamente migliorare l’illusione, dal momento che il video del deepfake è sussunto in un linguaggio visivo comune e di bassa qualità che viene percepito come autentico.
Tag di sopravvivenza come aiuto per l’inversione del modello
L’identificazione dei dati di origine dall’output dell’apprendimento automatico è un campo relativamente nuovo e in crescita, e uno che rende possibile una nuova era di contenzioso basato sulla proprietà intellettuale, poiché le attuali normative permissive sullo screen scraping dei governi (progettate per non soffocare la preminenza della ricerca nazionale nel di fronte a una “corsa agli armamenti” globale dell’IA) si evolvono in una legislazione più severa man mano che il settore viene commercializzato.
Model Inversion si occupa della mappatura e dell’identificazione dei dati di origine dall’output generato dai sistemi di sintesi in una serie di domini, tra cui Natural Language Generation (NLG) e sintesi di immagini. L’inversione del modello è particolarmente efficace per identificare nuovamente i volti sfocati, pixelati o che si sono fatti strada attraverso il processo di astrazione di una Generative Adversarial Network o di un sistema di trasformazione encoder/decoder come DeepFaceLab.
L’aggiunta di tag mirati a immagini facciali nuove o esistenti è un potenziale nuovo aiuto per modellare le tecniche di inversione, con la filigrana in un campo emergente.
Tagging post-fatto
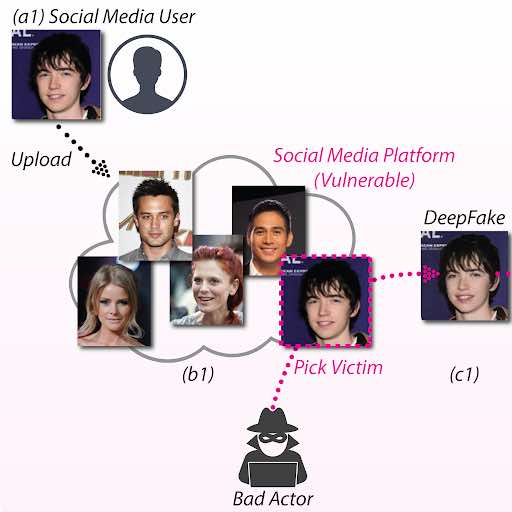
FakeTagger è inteso come un approccio di post-elaborazione. Ad esempio, quando un utente carica una foto su un social network (che di solito comporta un qualche tipo di processo di ottimizzazione e raramente un trasferimento diretto e non alterato dell’immagine originale), l’algoritmo elaborerebbe l’immagine per applicare caratteristiche apparentemente indelebili al viso .
In alternativa, l’algoritmo potrebbe essere applicato a raccolte di immagini storiche, come è accaduto diverse volte negli ultimi vent’anni, poiché i grandi siti di raccolta di immagini commerciali e di foto stock hanno cercato metodi per identificare i contenuti che sono stati riutilizzati senza autorizzazione.
FakeTagger cerca di incorporare caratteristiche ID recuperabili da vari processi deepfake.
Sviluppo e test
I ricercatori hanno testato FakeTagger contro una serie di applicazioni software deepfake attraverso i quattro approcci summenzionati, incluso il repository più utilizzato, DeepFaceLab; Face2Face di Stanford , che può trasferire le espressioni facciali attraverso immagini e identità; e STGAN , che può modificare gli attributi facciali.
I test sono stati effettuati con CelebA-HQ , un popolare repository pubblico raschiato contenente 30.000 immagini di volti di celebrità a varie risoluzioni fino a 1024 x 1024 pixel.
Come base di riferimento, i ricercatori hanno inizialmente testato le tecniche convenzionali di watermarking delle immagini, per vedere se i tag imposti sarebbero sopravvissuti ai processi di formazione dei flussi di lavoro deepfake, ma i metodi hanno fallito in tutti e quattro gli approcci.
I dati incorporati di FakeTagger sono stati iniettati nella fase dell’encoder nelle immagini del set di volti utilizzando un’architettura basata sulla rete convoluzionale U-Net per la segmentazione delle immagini biomediche, rilasciata nel 2015. Successivamente, la sezione del decodificatore del framework viene addestrata per trovare le informazioni incorporate .
Il processo è stato testato in un simulatore GAN che ha sfruttato le suddette applicazioni/algoritmi FOSS, in un’impostazione black box senza alcun accesso discreto o speciale ai flussi di lavoro di ciascun sistema. Segnali casuali sono stati allegati alle immagini delle celebrità e registrati come dati correlati a ciascuna immagine.
In un ambiente a scatola nera, FakeTagger è stato in grado di raggiungere una precisione superiore all’88,95% negli approcci delle quattro applicazioni. In uno scenario a scatola bianca parallela, la precisione è aumentata fino a quasi il 100%. Tuttavia, poiché questo suggerisce iterazioni future del software deepfake che incorpora direttamente FakeTagger, è uno scenario improbabile nel prossimo futuro.
Contare il costo
I ricercatori notano che lo scenario più impegnativo per FakeTagger è la sintesi completa dell’immagine , come la generazione astratta basata su CLIP, poiché in questo caso i dati di addestramento di input sono soggetti ai livelli di astrazione più profondi. Tuttavia, questo non si applica ai flussi di lavoro deepfake che hanno dominato i titoli negli ultimi anni, poiché dipendono dalla riproduzione fedele delle caratteristiche facciali che definiscono l’ID.
Il documento rileva inoltre che gli aggressori avversari potrebbero plausibilmente tentare di aggiungere perturbazioni, come rumore artificiale e grana, al fine di sventare un tale sistema di tagging, anche se ciò potrebbe avere un effetto dannoso sull’autenticità dell’output del deepfake.
Inoltre, notano che FakeTagger deve aggiungere dati ridondanti alle immagini per garantire la sopravvivenza dei tag che incorpora e che ciò potrebbe avere un notevole costo computazionale su larga scala.
Gli autori concludono osservando che FakeTagger potrebbe avere il potenziale per il monitoraggio della provenienza in altri domini, come attacchi di pioggia contraddittori e altri tipi di attacchi basati su immagini, come esposizione contraddittoria , foschia , sfocatura , vignettatura e jittering di colore .