I parametri sono la chiave degli algoritmi di apprendimento automatico. Sono la parte del modello che viene appresa dai dati di addestramento storici. In generale, nel dominio del linguaggio, la correlazione tra il numero di parametri e la sofisticazione ha retto molto bene. Ad esempio, GPT-3 di OpenAI, uno dei più grandi modelli di linguaggio mai addestrati su 175 miliardi di parametri, può fare analogie primitive, generare ricette e persino completare il codice di base.
In quello che potrebbe essere uno dei test più completi di questa correlazione fino ad oggi, i ricercatori di Google hanno sviluppato e confrontato tecniche che sostengono hanno permesso loro di addestrare un modello linguistico contenente più di un trilione di parametri. Dicono che il loro modello da 1,6 trilioni di parametri, che sembra essere il più grande delle sue dimensioni fino ad oggi, ha raggiunto una velocità fino a 4 volte superiore rispetto al precedente modello linguistico sviluppato da Google (T5-XXL).
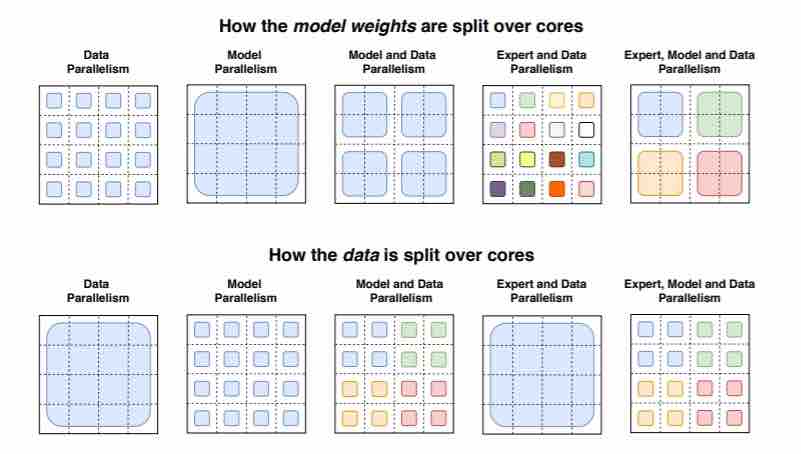
Come notano i ricercatori in un documento che descrive in dettaglio il loro lavoro, la formazione su larga scala è un percorso efficace verso modelli potenti. Architetture semplici, supportate da grandi set di dati e conteggi di parametri, superano algoritmi molto più complicati. Ma sebbene sia efficace, la formazione su larga scala è estremamente intensiva dal punto di vista computazionale. Ecco perché i ricercatori hanno perseguito quello che chiamano Switch Transformer, una tecnica “scarsamente attivata” che utilizza solo un sottoinsieme dei pesi di un modello, oi parametri che trasformano i dati di input all’interno del modello.
Switch Transformer si basa su un mix di esperti, un paradigma del modello di intelligenza artificiale proposto per la prima volta all’inizio degli anni ’90. Il concetto approssimativo è quello di mantenere più esperti, o modelli specializzati in compiti diversi, all’interno di un modello più grande e avere una “rete di gating” che sceglie quali esperti consultare per un dato dato.
La novità dello Switch Transformer è che sfrutta in modo efficiente l’hardware progettato per moltiplicazioni di matrici dense – operazioni matematiche ampiamente utilizzate nei modelli di linguaggio – come le GPU e le unità di elaborazione tensoriale (TPU) di Google. Nella configurazione di formazione distribuita dei ricercatori, i loro modelli suddividono pesi univoci su dispositivi diversi in modo che i pesi aumentino con il numero di dispositivi ma mantenendo una memoria gestibile e un’impronta computazionale su ciascun dispositivo.
In un esperimento, i ricercatori hanno pre-addestrato diversi modelli di Switch Transformer utilizzando 32 core TPU sul Colossal Clean Crawled Corpus, un set di dati di 750 GB di testo estratto da Reddit, Wikipedia e altre fonti web. Hanno incaricato i modelli di prevedere le parole mancanti nei passaggi in cui il 15% delle parole era stato mascherato, così come altre sfide come il recupero del testo per rispondere a un elenco di domande sempre più difficili.
Modello di parametri Google AI trilioni
I ricercatori affermano che il loro modello da 1.6 trilioni di parametri con 2.048 esperti (Switch-C) ha mostrato “nessuna instabilità di allenamento”, in contrasto con un modello più piccolo (Switch-XXL) contenente 395 miliardi di parametri e 64 esperti. Tuttavia, su un benchmark – il Sanford Question Answering Dataset (SQuAD) – Switch-C ha ottenuto un punteggio inferiore (87,7) rispetto a Switch-XXL (89,6), che i ricercatori attribuiscono alla relazione opaca tra qualità di messa a punto, requisiti di calcolo e numero di parametri.
Stando così le cose, Switch Transformer ha portato a guadagni in una serie di attività a valle. Ad esempio, ha consentito una velocità di pre-addestramento di oltre 7 volte utilizzando la stessa quantità di risorse computazionali, secondo i ricercatori, che hanno dimostrato che i modelli sparsi di grandi dimensioni potrebbero essere utilizzati per creare modelli più piccoli e densi ottimizzati su attività con il 30% dei guadagni di qualità del modello più grande. In un test in cui un modello Switch Transformer è stato addestrato per tradurre tra oltre 100 lingue diverse, i ricercatori hanno osservato “un miglioramento universale” in 101 lingue, con il 91% delle lingue che ha beneficiato di una velocità di oltre quattro volte superiore rispetto a un modello di base.
“Sebbene questo lavoro si sia concentrato su modelli estremamente grandi, troviamo anche che i modelli con un minimo di due esperti migliorano le prestazioni mentre si adattano facilmente ai vincoli di memoria delle GPU o TPU comunemente disponibili”, hanno scritto i ricercatori nel documento. “Non siamo in grado di preservare completamente la qualità del modello, ma è possibile ottenere tassi di compressione da 10 a 100 volte distillando i nostri modelli sparsi in modelli densi ottenendo circa il 30% del guadagno di qualità del modello esperto”.
Nel lavoro futuro, i ricercatori prevedono di applicare lo Switch Transformer a “nuove modalità e attraverso diverse modalità”, inclusi immagini e testo. Credono che la scarsità dei modelli possa conferire vantaggi in una gamma di diversi media e modelli multimodali .
Sfortunatamente, il lavoro dei ricercatori non ha tenuto conto dell’impatto di questi grandi modelli linguistici nel mondo reale. I modelli spesso amplificano i pregiudizi codificati in questi dati pubblici; una parte dei dati di formazione non è insolitamente proveniente da comunità con pregiudizi di genere, razza e religiosi pervasivi . La società di ricerca sull’intelligenza artificiale OpenAI osserva che questo può portare a posizionare parole come “cattivo” o “succhiato” vicino a pronomi femminili e “Islam” vicino a parole come “terrorismo”. Altri studi, come quello pubblicato da Intel, MIT, e ricercatori canadesi AI iniziativa CIFAR nel mese di aprile, hanno trovato alti livelli di pregiudizio stereotipato da alcuni dei modelli più popolari, tra cui il BERT di Google e XLNet , di OpenAI GPT-2 , e RoBERTa di Facebook . Secondo il Middlebury Institute of International Studies, questo pregiudizio potrebbe essere sfruttato da attori maliziosi per fomentare discordia diffondendo disinformazione, disinformazione e menzogne vere e proprie che “radicalizzano gli individui in ideologie e comportamenti violenti di estrema destra”.
Non è chiaro se le politiche di Google sulla ricerca pubblicata sull’apprendimento automatico possano aver avuto un ruolo in questo. Reuters ha riferito alla fine dell’anno scorso che i ricercatori dell’azienda sono ora tenuti a consultare i team egali, politici e di pubbliche relazioni prima di approfondire argomenti come l’analisi del volto e del sentimento e le categorizzazioni di razza, genere o affiliazione politica. E all’inizio di dicembre, Google ha licenziato l’ etica dell’IA Timnit Gebru, secondo quanto riferito in parte per un documento di ricerca su modelli linguistici di grandi dimensioni che discuteva dei rischi tra cui l’impatto della loro impronta di carbonio sulle comunità emarginate e la loro tendenza a perpetuare linguaggio offensivo, incitamento all’odio, microaggressioni, stereotipi e altri linguaggi disumanizzanti rivolti a gruppi specifici di persone.