Per la prima volta, un Generative Adversarial Network viene utilizzato per creare set di dati sintetici di immagini di ferite, al fine di ovviare a una mancanza critica di contenuti diversificati e accessibili di questo tipo nelle applicazioni di machine learning per l’ assistenza sanitaria .
Il sistema, denominato WG 2 AN , è una collaborazione tra il Batten College of Engineering & Technology e la società di assistenza sanitaria AI eKare, specializzata nell’applicazione di metodologie di machine learning alla misurazione e identificazione delle ferite.
Il GAN è formato su 100-4000 immagini di ferite croniche stereoscopiche etichettate fornite da eKare, comprese immagini anonime di tipi di lesioni da cause quali pressione, interventi chirurgici, incidenti linfovascolari, diabete e ustioni. Il materiale sorgente variava in dimensioni comprese tra 1224 × 1224 e 2160 × 2160, tutte prese sotto la luce disponibile dai medici.
Per accogliere lo spazio latente disponibile nell’architettura di addestramento del modello, le immagini sono state ridimensionate a 512 × 512 ed estratte dai rispettivi sfondi. Per studiare l’effetto della dimensione del set di dati, sono state implementate esecuzioni di test su batch di 100, 250, 500, 1000, 2000 e 4000 immagini.
L’immagine sopra mostra un dettaglio e una granularità crescenti in base alle dimensioni del set di allenamento contributivo e al numero di epoche eseguite su ciascun passaggio.
WG 2 GAN funziona su PyTorch su una configurazione in stile consumer relativamente snella, con 8 GB di VRAM su una GPU GTX 1080. La formazione ha richiesto tra le 4 e le 58 ore sulla gamma di dimensioni del set di dati da 100-4000 immagini e su una gamma di epoche, su una dimensione del lotto di 64 come compromesso tra precisione e prestazioni. Adam Optimizer viene utilizzato per la prima metà dell’addestramento a una velocità di apprendimento di 0,0002 e si conclude con una velocità di apprendimento a decadimento lineare fino a ottenere una perdita pari a zero.
In alto a sinistra, segmentazione applicata all’area della ferita. Al centro, immagine della ferita vera e propria; in alto a destra, una ferita sintetica di un tipo che può essere generalizzato in un set di dati, basato sulla fonte originale. Sotto, la ferita originale e, a destra, una sintesi della ferita generata da WG2GAN.
In alto a sinistra, segmentazione applicata all’area della ferita. Al centro, immagine della ferita vera e propria; in alto a destra, una ferita sintetica di un tipo che può essere generalizzato in un set di dati, basato sulla fonte originale. Sotto, la ferita originale e, a destra, una sintesi della ferita generata da WG2GAN.
Nei set di dati medici, come in tanti altri settori dell’apprendimento automatico, l’etichettatura è un inevitabile collo di bottiglia. In questo caso, i ricercatori hanno utilizzato un sistema di etichettatura semiautomatico che sfrutta le ricerche precedenti di eKare, che utilizzava modelli di ferite del mondo reale, creati in Play-Doh e colorati approssimativamente per il contesto semantico.
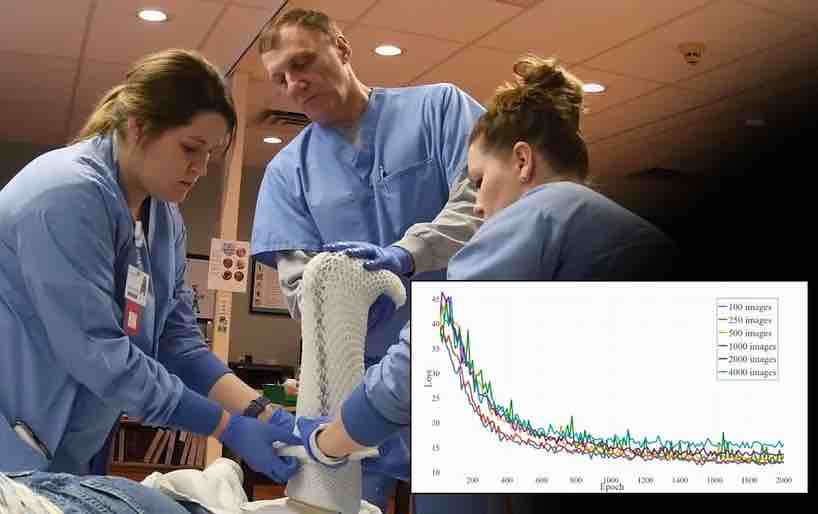
I ricercatori hanno notato un problema che si verifica frequentemente nelle fasi iniziali dell’addestramento, quando un set di dati è piuttosto diversificato e i pesi sono randomizzati: il modello impiega molto tempo (75 epoche) per “stabilizzarsi”:
Laddove i dati sono variegati, entrambi i modelli GAN e codificatore / decodificatore lottano per ottenere la generalizzazione nelle fasi precedenti, come possiamo vedere evidenziato nel grafico sopra dell’addestramento del WG 2 GAN, che tiene traccia della sequenza temporale dell’addestramento dall’inizio alla perdita zero.
È necessario prestare attenzione per garantire che il processo di formazione non si fissi sulle caratteristiche o sulle caratteristiche di una qualsiasi iterazione o epoca, ma piuttosto continui a generalizzare a una perdita media utilizzabile senza produrre risultati che astraggono eccessivamente il materiale di partenza. Nel caso del WG 2 GAN, ciò rischierebbe di creare ferite illimitate, interamente “fittizie”, concatenate tra una gamma troppo ampia di tipi di ferite non correlate, piuttosto che produrre una gamma accurata di variazioni all’interno di un particolare tipo di ferita.
Ambito di controllo in un set di dati di machine learning
I modelli con set di addestramento più leggeri si generalizzano più velocemente ei ricercatori del documento sostengono che le immagini più realistiche potrebbero essere ottenute a meno delle impostazioni massime: un set di dati di 1000 immagini addestrato su 200 epoche.
Sebbene set di dati più piccoli possano ottenere immagini altamente realistiche in meno tempo, anche la gamma di immagini e i tipi di ferite generate saranno necessariamente più limitati. Esiste un delicato equilibrio nei regimi di addestramento del GAN e del codificatore / decodificatore tra il volume e la varietà dei dati di input, la fedeltà delle immagini prodotte e il realismo delle immagini prodotte – questioni di portata e ponderazione che non sono certamente limitate all’immagine medica sintesi.
Squilibri di classe nei set di dati medici
In generale, l’apprendimento automatico del settore sanitario è afflitto non solo dalla mancanza di set di dati , ma anche da squilibri di classe , in cui i dati essenziali su una malattia specifica costituiscono una percentuale così piccola del set di dati che lo ospita che rischia di essere liquidato come dati anomali o di farsi assimilare nel processo di generalizzazione durante la formazione.
Sono stati proposti numerosi metodi per affrontare quest’ultimo problema, come il sottocampionamento o il sovracampionamento . Tuttavia, il problema viene spesso evitato sviluppando set di dati specifici per la malattia che sono interamente legati a un singolo problema medico. Sebbene questo approccio sia efficace caso per caso, contribuisce alla cultura della balcanizzazione nella sfera della ricerca sull’apprendimento automatico medico e probabilmente rallenta il progresso generale nel settore.