L’apprendimento automatico ha mostrato miglioramenti significativi nell’assistenza sanitaria. I ricercatori hanno sviluppato modelli in grado di diagnosticare condizioni critiche come la malattia oculare diabetica o il cancro al seno metastatico. La visione artificiale è stata anche provata per interventi chirurgici assistiti da AR. Ma perché non vediamo più IA nell’assistenza sanitaria?
Le sfide stanno affliggendo la comunità ML. La creazione di algoritmi non è semplice. Queste sfumature sono state discusse brevemente da Rohit Ghosh, il membro fondatore di Qure.ai durante la Deep learning Developers Conference in corso. La Deep Learning Developers Conference (DLDC 2020) è un evento virtuale di due giorni organizzato dall’Association of Data Scientists (AdaSci). Rohit Ghosh, che è uno specialista in ricerca e sviluppo e ha svolto un ruolo fondamentale nello sviluppo della porzione di visione artificiale degli algoritmi di apprendimento profondo di Qure.ai per l’elaborazione delle immagini radiologiche, ha presentato al pubblico varie sfide per quanto riguarda l’imaging medico.
Sfide nell’imaging medico
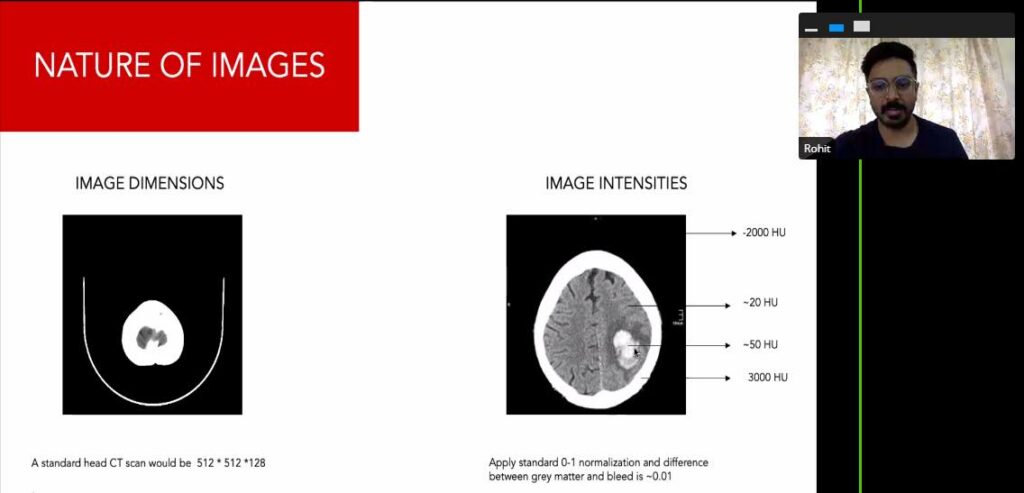
La raccolta dei dati è una delle parti più impegnative di qualsiasi pipeline di machine learning. Tanto più nel caso delle applicazioni mediche. Le lacune nella qualità dei dati si traducono in diagnosi errate. Le dimensioni e le intensità delle immagini delle scansioni fornite ai modelli ML dovrebbero soddisfare determinati parametri di riferimento per ottenere una precisione a livello umano. In questo discorso di quasi un’ora, Ghosh ha sottolineato il significato della dimensionalità e quanto siano fondamentali per soluzioni affidabili.
Mancanza di dataset open source
Potremmo aver visto set di dati con milioni di immagini di fiori e altri oggetti banali e quotidiani. Ma, quando si tratta di immagini mediche, i set di dati più grandi contengono solo poche centinaia di migliaia di immagini. Ghosh ha spiegato che gli algoritmi costruiti su Qure.ai potrebbero richiedere almeno 3 milioni di immagini per funzionare bene. La mancanza di set di dati open source è un ostacolo per gli sviluppatori di algoritmi.
Mancanza di trasferimento di apprendimento
Il transfer learning ha cambiato il modo in cui facciamo ML. Tuttavia, ci sono ancora alcune domande urgenti che disturbano l’apprendimento del trasferimento in ML:
Quanto del compito originale ha dimenticato il modello?
Perché i modelli grandi non cambiano tanto quanto i modelli piccoli?
Possiamo ottenere di più dalle statistiche sul peso pre-allenato?
I risultati sono simili ad altri compiti, come la segmentazione?
Oltre a queste sfide ben documentate, in questo discorso, Ghosh ha sottolineato quanto sia difficile trasferire l’apprendimento tra le due parti del corpo e aggiunto a questa sfida è la mancanza di problemi di pre-allenamento. Ogni caso di studio potrebbe presentare problemi specifici. Detto questo, Ghosh ha anche convenuto che ogni soluzione nell’IA medica non deve essere all’avanguardia. Deve solo essere elegante in modo che possa affrontare i problemi del mondo reale in tempo reale.
Sfida di interpretabilità
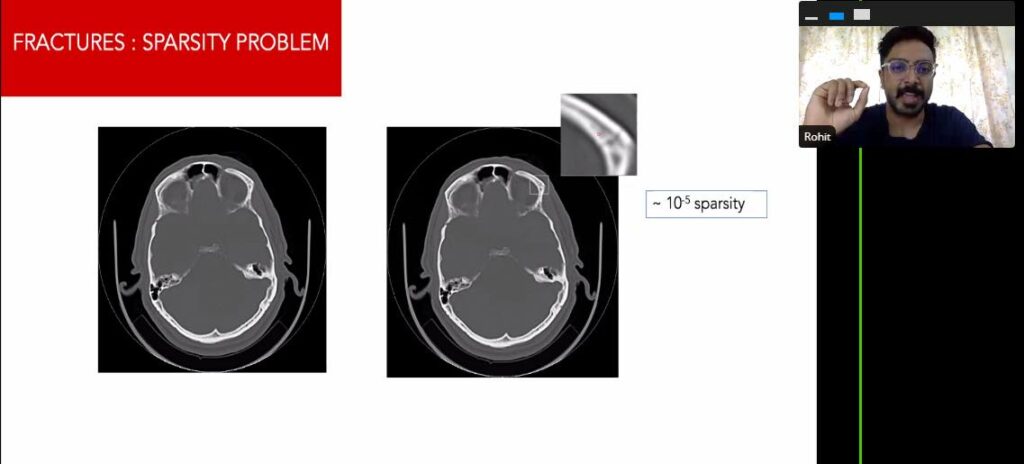
L’interpretabilità in ML è attualmente un’area di ricerca attiva. I problemi si estendono anche all’imaging medico. Solo in questo caso, una decisione errata può rivelarsi fatale. Ghosh ha spiegato come le fratture del cranio potrebbero essere scambiate per suture. Ha paragonato questo come trovare un ago in un pagliaio. I problemi di scarsità sono specifici dell’imaging medico e richiedono modelli migliori e conoscenze specifiche del dominio per un processo decisionale adeguato.
La nuova iniziativa basata sull’apprendimento automatico di Google per la scoperta accelerata dei farmaci
L’esperienza del dominio o anche la conoscenza della diagnosi specifica, ha affermato Ghosh, è un problema di vecchia data e questo è ciò che ostacola il progresso dell’IA in ambito sanitario. È impossibile per un laureato in informatica costruire algoritmi che abbiano lo stesso scopo degli esperti medici. La collaborazione interdisciplinare è fondamentale per il futuro.
Oltre a quelle sopra menzionate, alcune altre sfide che hanno afflitto la comunità AI sono:
Elevati costi di esercizio.
Trovare il giusto gruppo di ricercatori con conoscenze interdisciplinari.
Raccolta di dati sufficienti per evitare pregiudizi.
Mantenere i dati privati (ad esempio: Alexa suggerisce di cali ascoltando i suoni della tosse).
Il superamento di queste sfide richiede molte modifiche dal livello di base. Un buon punto di partenza può essere un’aggressiva collaborazione e consapevolezza interdisciplinare. Gli operatori sanitari dovrebbero essere incentivati a conoscere la provenienza, la cura, l’integrazione e la governance dei dati sanitari, l’etica dell’IA e sistemi o strumenti autonomi per accelerare la trasformazione nel mondo della medicina.