Supponi di aver mai provato a replicare un documento di apprendimento automatico all’avanguardia o decente. In tal caso, potresti esserti imbattuto in problemi di pacchetti e librerie, problemi di versione, hardware e molte altre sfide, suggerendo che la riproducibilità in ML è un problema serio.
Joelle Pineau , una ricercatrice di ML, ha portato l’attenzione di tutta la comunità sulla riproducibilità. In un’intervista pubblicata da Nature l’anno scorso, Pineau li ha affrontati in modo dettagliato.
Anche un programma di riproducibilità è stato introdotto a neurIPS 2019 che ha richiesto ai ricercatori di considerare quanto segue:
una politica di invio del codice,
una sfida per la riproducibilità a livello di comunità e
un elenco di controllo per la riproducibilità dell’apprendimento automatico
Recentemente, Grigori Fursin, uno scienziato informatico, ha pubblicato delle liste di controllo da tenere a mente se i ricercatori si preoccupano della riproducibilità.
In un recente discorso , Fursin ha condiviso la sua esperienza nella riproduzione di oltre 150 sistemi e documenti ML durante la valutazione degli artefatti presso ASPLOS, MLSys, CGO, PPoPP e Supercomputing. “Il nostro obiettivo a lungo termine è aiutare i ricercatori a condividere le loro nuove tecniche di ML come pacchetti pronti per la produzione insieme a documenti pubblicati e partecipare a benchmarking collaborativi e riproducibili, co-progettazione e confronto di stack ML / software / hardware efficienti”, ha affermato.
Informazioni su Artifact
Per rendere più facile per i revisori, l’accesso agli artefatti dovrebbe essere chiaro:
Indica se clonare il repository da GitHub , GitLab, BitBucket o qualsiasi servizio simile
Download del pacchetto da un sito Web pubblico o privato
Consenti l’accesso agli artefatti tramite una macchina privata con software preinstallato quando è richiesto l’accesso a hardware raro o viene utilizzato software proprietario
Fursin consiglia inoltre di descrivere lo spazio su disco approssimativo richiesto dopo aver decompresso l’artefatto in modo da evitare pacchetti software non necessari per le immagini della VM.
Dipendenze
Cambiare qualsiasi cosa cambia tutto o il principio CACE è una delle euristiche per la gestione dei prodotti software. Questo si riferisce alla dipendenza di ogni modifica che apportiamo in una pipeline . I ricercatori dovrebbero descrivere qualsiasi hardware specifico e funzionalità specifiche richieste per valutare artefatti come fornitore, CPU / GPU / FPGA, numero di processori / core, interconnessione, memoria, contatori hardware, sistemi operativi e pacchetti software.
“Questo è particolarmente importante se condividi il tuo codice sorgente e deve essere compilato o se ti affidi a qualche software proprietario che non puoi includere nel tuo pacchetto. In tal caso, ti consigliamo vivamente di descrivere come ottenere e installare tutti i software, i set di dati e i modelli di terze parti “, ha scritto Fursin.
Set di dati, modelli e installazione
Se i set di dati sono di grandi dimensioni o proprietari, è consigliabile aggiungere dettagli su come scaricare il set di dati. Se proprietario, ai revisori dovrebbe essere fornito un sottoinsieme alternativo pubblico per la valutazione. Lo stesso vale anche per i modelli. Se i modelli di terze parti non sono inclusi nei pacchetti (ad esempio, sono molto grandi o proprietari), fornire i dettagli su come scaricarli e installarli, descrivere le procedure di configurazione per gli artefatti.
Flusso di lavoro e valutazione dell’esperimento
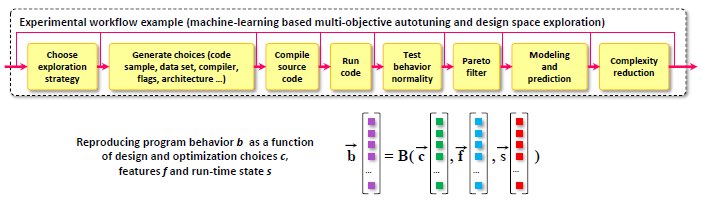
Descrivi il flusso di lavoro sperimentale e come viene implementato, invocato e personalizzato (se necessario), ovvero alcuni script del sistema operativo, notebook IPython / Jupyter, flusso di lavoro CK portatile, ecc. Descrivi inoltre tutti i passaggi necessari per valutare gli artefatti utilizzando il flusso di lavoro sopra. Descrivere il risultato atteso e la variazione massima consentita dei risultati empirici (particolarmente importante per i numeri di prestazioni e le accelerazioni).
Personalizzazione dell’esperimento
La personalizzazione non è sempre interessante. Questa raccomandazione è più un’opzione ma non sempre irrilevante. Se possibile, descrivere come personalizzare il flusso di lavoro, ovvero se è possibile utilizzare diversi set di dati, benchmark, applicazioni reali, modelli predittivi, ambiente software (compilatori, librerie, sistemi run-time), hardware, ecc. Inoltre, descrivere se è possibile parametrizzare il flusso di lavoro (qualsiasi cosa sia applicabile come cambiare il numero di thread, applicare diverse ottimizzazioni, frequenza CPU / GPU, scenario di autotuning, topologia del modello, ecc.).