Il compito dei compilatori è tradurre i linguaggi di programmazione scritti dagli esseri umani in eseguibili binari dall’hardware del computer. I compilatori vengono eseguiti su sistemi ampi, complessi, eterogenei, non deterministici e in continua evoluzione. L’ottimizzazione dei compilatori è difficile perché il numero di ottimizzazioni possibili è enorme. La progettazione di euristiche che tengano conto di tutte queste considerazioni alla fine diventa difficile. Di conseguenza, molte ottimizzazioni del compilatore non sono aggiornate o sono state regolate male.
Una delle sfide principali è selezionare la giusta trasformazione del codice per un dato programma, che richiede una valutazione efficace della qualità di una possibile opzione di compilazione. Ad esempio, sapere come una trasformazione del codice influirà sulle prestazioni finali è una di queste opzioni.
Un decennio fa, è stato introdotto il machine learning per migliorare l’automazione dell’ottimizzazione dello spazio. Ciò ha consentito agli autori di compilatori di sviluppare senza doversi preoccupare delle architetture o delle specifiche del programma. Gli algoritmi erano in grado di apprendere l’euristica dai risultati delle ricerche precedenti. Ciò ha contribuito a ottimizzare il processo nella corsa successiva in un unico scatto. La compilazione basata sull’apprendimento automatico è ora un’area di ricerca e nell’ultimo decennio questo campo ha generato un grande interesse accademico.
Per saperne di più sullo stato attuale del machine learning e sulle sue implicazioni per i compilatori, i ricercatori dell’Università di Edimburgo e Facebook AI hanno collaborato per esaminare il ruolo dell’apprendimento automatico in relazione ai compilatori.
I compilatori hanno due compiti: traduzione e ottimizzazione. I programmi vengono prima tradotti correttamente in binario. Successivamente, devono trovare la traduzione più efficiente possibile. Pertanto, la stragrande maggioranza delle pratiche di ricerca e ingegneria è focalizzata sull’ottimizzazione . L’idea alla base dell’ottimizzazione dei compilatori è di ridurre al minimo o massimizzare alcuni attributi di un programma per computer eseguibile come la riduzione al minimo del tempo di esecuzione di un programma, dei requisiti di memoria e del consumo energetico.
È possibile creare macchine per apprendere come ottimizzare un compilatore per farlo funzionare più velocemente. L’apprendimento automatico è ideale per prendere qualsiasi decisione di ottimizzazione del codice in cui l’impatto sulle prestazioni dipende dalla piattaforma sottostante.
Il vantaggio dell’approccio basato su ML, hanno affermato i ricercatori , Wang e Boyle, è che l’intero processo di creazione del modello può essere facilmente ripetuto ogni volta che il compilatore deve scegliere come target una nuova architettura hardware, sistema operativo o dominio applicativo.
C’erano alcune implementazioni del deep learning per i compilatori. Uno di questi era una rete neurale profonda utilizzata per prevedere direttamente il valore euristico corretto per alcune ottimizzazioni in OpenCL. Hanno usato LSTM per questo, che ha permesso loro di comprendere in qualche modo la struttura del programma, ad esempio se una variabile è stata dichiarata in passato. I risultati sono migliorati rispetto alle precedenti funzionalità costruite a mano. Questa ricerca è stata seguita dall’incorporazione di rappresentazioni basate su grafici. I ricercatori hanno pensato che si sarebbe adattato meglio ai linguaggi di programmazione. Le istruzioni di un programma possono essere rappresentate come i bordi del grafico, raffiguranti la relazione tra le variabili.
Il flusso di dati è fondamentale per praticamente ogni ottimizzazione nel compilatore. I modelli dovrebbero essere in grado di ragionare su programmi complessi. Perché ciò accadesse, hanno scritto i ricercatori, erano necessarie rappresentazioni migliori e grafici RNN che corrispondessero al modello del flusso di dati.
In questo lavoro, gli autori affrontano la domanda: dove sta andando questo campo? Cosa dobbiamo fare nei prossimi anni? Il processo di ottimizzazione è difficile e diventerà ancora più difficile.
Cosa riserva il futuro
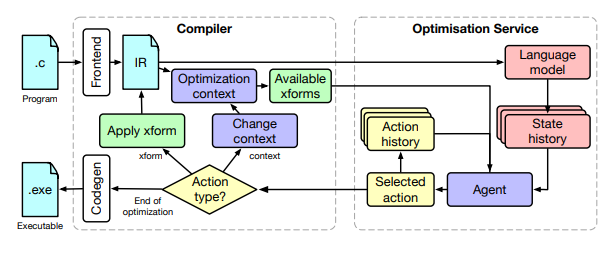
Andando avanti, i ricercatori stanno scommettendo molto sull’apprendimento per rinforzo per compilatori migliori. L’illustrazione sopra è un’architettura per il compilatore governata dai principi dell’apprendimento per rinforzo. Qui, i sistemi RL hanno il compito di esaminare le ottimizzazioni su altre funzioni, blocchi di base e singole istruzioni.
Previsione del tasso di cambio utilizzando la rete neurale ricorrente LSTM
Per ogni contesto, il compilatore determina una serie di trasformazioni applicabili e valide che passa a un agente RL per effettuare la sua scelta. L’agente sceglie l’azione successiva in base allo stato corrente del programma e alla cronologia delle azioni e degli stati che ha visto.
Il sistema RL intraprenderà azioni che aumenteranno la probabile ricompensa futura, che sarà l’accelerazione trovata applicando la sequenza di azioni al codice.
Tuttavia, gli autori ammettono anche che questo problema è più ampio di quelli a cui viene tipicamente applicato l’apprendimento per rinforzo. Lo spazio statale è enorme, così come lo spazio d’azione. La valutazione della ricompensa può richiedere molto tempo e il programma deve essere compilato in un binario ed eseguito con input rappresentativi abbastanza tempo per fornire tempistiche statisticamente valide.
I compilatori moderni sono software multimilionario che possono richiedere anni per essere padroneggiati. Per sfruttare il ML per compilatori efficienti, i ricercatori hanno pochi suggerimenti:
Scrittori di compilatori per creare compilatori modulari che supportano la compilazione iterativa e l’apprendimento automatico da zero.
I ricercatori di machine learning dovrebbero inventare modelli adatti alla natura ricorrente e basata sul flusso dei programmi.
Consenti a ogni scelta di ottimizzazione di essere esposta tramite API rilevabili con cui la ricerca iterativa e l’apprendimento automatico possono interagire.