I ricercatori propongono un modello nuovo e più efficace per il riconoscimento vocale automatico
Il nuovo framework incentrato sui consumatori migliora il riconoscimento vocale automatico includendo informazioni sul contesto, una soluzione migliorata per le videoconferenze e le interviste dal vivo
Assistenti vocali popolari come Siri e Amazon Alexa hanno introdotto il riconoscimento vocale automatico (ASR) al grande pubblico. Nonostante decenni di lavoro, i modelli ASR lottano con coerenza e affidabilità, specialmente in ambienti rumorosi. I ricercatori cinesi hanno sviluppato un framework che migliora efficacemente le prestazioni dell’ASR per il caos degli ambienti acustici quotidiani.
I ricercatori dell’Università di scienza e tecnologia di Hong Kong e WeBank hanno proposto un nuovo framework – il pre-training fonetico-semantico (PSP) e hanno dimostrato la robustezza del loro nuovo modello rispetto a set di dati vocali sintetici altamente rumorosi.
Il loro studio è stato pubblicato su CAAI Artificial Intelligence Research il 28 agosto.
“La robustezza è una sfida di lunga data per ASR”, ha affermato Xueyang Wu del Dipartimento di Informatica e Ingegneria dell’Università di Scienza e Tecnologia di Hong Kong. “Vogliamo aumentare la robustezza del sistema ASR cinese con un basso costo”.
ASR utilizza l’apprendimento automatico e altre tecniche di intelligenza artificiale per tradurre automaticamente il parlato in testo per usi come sistemi ad attivazione vocale e software di trascrizione. Ma le nuove applicazioni incentrate sui consumatori richiedono sempre più che il riconoscimento vocale funzioni meglio: gestisca più lingue e accenti e funzioni in modo più affidabile in situazioni di vita reale come le videoconferenze e le interviste dal vivo.
Tradizionalmente, l’addestramento dei modelli acustici e linguistici che compongono l’ASR richiede grandi quantità di dati specifici del rumore, che possono essere proibitivi in termini di tempo e costi.
Il modello acustico (AM) trasforma le parole in “telefoni”, che sono sequenze di suoni di base. Il modello linguistico (LM) decodifica i telefoni in frasi in linguaggio naturale, di solito con un processo in due fasi: un LM veloce ma relativamente debole genera una serie di frasi candidate e un LM potente ma computazionalmente costoso seleziona la frase migliore tra i candidati.
“I modelli di apprendimento tradizionali non sono robusti contro i rumorosi output dei modelli acustici, in particolare per le parole polifoniche cinesi con pronuncia identica”, ha affermato Wu. “Se il primo passaggio della decodifica del modello di apprendimento non è corretto, è estremamente difficile recuperare il secondo passaggio”.
Il quadro PSP recentemente proposto semplifica il recupero di parole classificate erroneamente. Pre-addestrando un modello che traduce gli output dell’AM direttamente in una frase insieme alle informazioni di contesto complete, i ricercatori possono aiutare il LM a riprendersi in modo efficiente dagli output rumorosi dell’AM.
Il framework PSP consente al modello di migliorare attraverso un regime di pre-formazione chiamato curriculum consapevole del rumore che introduce gradualmente nuove competenze, iniziando facilmente e passando gradualmente a compiti più complessi.
“La parte più cruciale del nostro metodo proposto, Noise-aware Curriculum Learning, simula il meccanismo con cui gli esseri umani riconoscono una frase da un discorso rumoroso”, ha detto Wu.
Il riscaldamento è la prima fase, in cui i ricercatori pre-addestrano un trasduttore da telefono a parola su una sequenza telefonica pulita, che viene tradotta solo da dati di testo senza etichetta, per ridurre il tempo di annotazione. Questa fase “riscalda” il modello, inizializzando i parametri di base per mappare le sequenze telefoniche alle parole.
Nella seconda fase, l’apprendimento auto-supervisionato, il trasduttore apprende da dati più complessi generati da tecniche e funzioni di addestramento auto-supervisionato. Infine, il risultante trasduttore da telefono a parola è messo a punto con i dati vocali del mondo reale.
I ricercatori hanno dimostrato sperimentalmente l’efficacia della loro struttura su due set di dati di vita reale raccolti da scenari industriali e rumore sintetico. I risultati hanno mostrato che il framework PSP migliora efficacemente la pipeline ASR tradizionale, riducendo i tassi di errore relativo dei caratteri del 28,63% per il primo set di dati e del 26,38% per il secondo.
Nelle fasi successive, i ricercatori studieranno metodi di pre-allenamento PSP più efficaci con set di dati spaiati più ampi, cercando di massimizzare l’efficacia del pre-allenamento per LM rumorosi.
Altri contributori includono Rongzhong Lian, Di Jiang, Yuanfeng Song, Weiwei Zhao e Qian Xu e Qiang Yang di WeBank Co. Ltd. Qian Xu e Qiang Yang sono anche affiliati all’Università di scienza e tecnologia di Hong Kong.
CAAI Artificial Intelligence Research è una nuova rivista sponsorizzata congiuntamente dall’Associazione cinese per l’intelligenza artificiale (CAAI) e dalla Tsinghua University. Questo è il primo articolo pubblicato sulla rivista.
Informazioni sulla ricerca sull’intelligenza artificiale CAAI
CAAI Artificial Intelligence Research è una rivista peer-reviewed sponsorizzata congiuntamente dall’Associazione cinese per l’intelligenza artificiale (CAAI) e dalla Tsinghua University. La rivista mira a riflettere i risultati all’avanguardia nel campo dell’intelligenza artificiale e della sua applicazione, inclusa l’intelligenza della conoscenza, l’intelligenza percettiva, l’apprendimento automatico, l’intelligenza comportamentale, il cervello e la cognizione, i chip e le applicazioni AI, ecc. Originale articoli di ricerca e revisione da tutto il mondo sono i benvenuti per una rigorosa revisione tra pari e un supporto editoriale professionale.
A proposito di SciOpen
SciOpen è una risorsa professionale ad accesso aperto per la scoperta di contenuti scientifici e tecnici pubblicata dalla Tsinghua University Press e dai suoi partner editoriali, fornendo alla comunità editoriale accademica tecnologia innovativa e capacità leader di mercato. SciOpen fornisce servizi end-to-end per l’invio di manoscritti, revisione tra pari, hosting di contenuti, analisi e gestione dell’identità e consulenza di esperti per garantire lo sviluppo di ogni rivista offrendo una gamma di opzioni in tutte le funzioni come Layout diario, Servizi di produzione, Servizi editoriali, Marketing e promozioni, funzionalità online, ecc. Digitalizzando il processo di pubblicazione, SciOpen amplia la portata, approfondisce l’impatto e accelera lo scambio di idee.
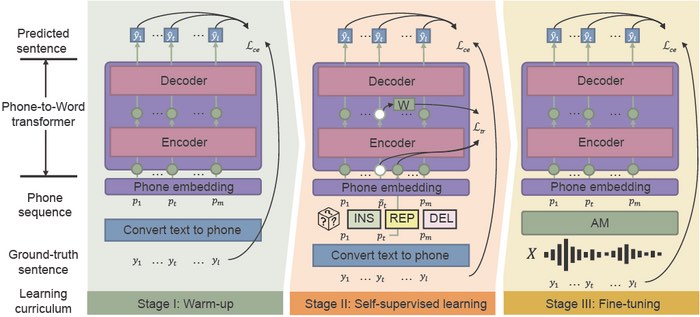
Il framework di pre-formazione fonetico-semantica (PSP) utilizza l’apprendimento del “curriculum sensibile al rumore” per migliorare efficacemente le prestazioni dell’ASR in ambienti rumorosi.
integrando riscaldamento, apprendimento auto-supervisionato e messa a punto.
CREDITO
Ricerca sull’intelligenza artificiale CAAI, Tsinghua University Press