Un consorzio di ricerca cinese ha sviluppato tecniche per portare capacità di editing e compositing a uno dei settori di ricerca sulla sintesi di immagini più in voga dell’ultimo anno: Neural Radiance Fields (NeRF). Il sistema è denominato ST-NeRF (Spatio-Temporal Coherent Neural Radiance Field).
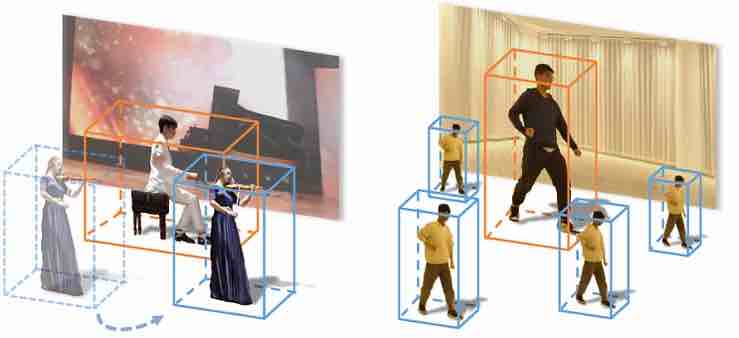
Quello che sembra essere una panoramica fisica della telecamera nell’immagine qui sotto è in realtà solo un utente che “scorre” i punti di vista sul contenuto video che esiste in uno spazio 4D. Il POV non è vincolato alle prestazioni delle persone rappresentate nel video, i cui movimenti possono essere visualizzati da qualsiasi parte di un raggio di 180 gradi.
Ogni sfaccettatura all’interno del video è un elemento discretamente catturato, composto insieme in una scena coesa che può essere esplorata dinamicamente.
Le sfaccettature possono essere duplicate liberamente all’interno della scena o ridimensionate:
Inoltre, il comportamento temporale di ogni sfaccettatura può essere facilmente alterato, rallentato, eseguito all’indietro o manipolato in qualsiasi numero di modi, aprendo la strada per filtrare le architetture e un livello estremamente elevato di interpretabilità.
Non è necessario eseguire il rotoscopio degli artisti o degli ambienti o che gli artisti eseguano i loro movimenti alla cieca e fuori dal contesto della scena prevista. Invece, le riprese vengono acquisite in modo naturale tramite una serie di 16 videocamere che coprono 180 gradi:
ST-NeRF è un’innovazione sulla ricerca nei Neural Radiance Fields ( NeRF ), un framework di apprendimento automatico in cui l’acquisizione di più punti di vista viene sintetizzata in uno spazio virtuale navigabile mediante una formazione approfondita (sebbene l’acquisizione di un singolo punto di vista sia anche un sottosettore della ricerca NeRF).
L’interesse per NeRF è diventato intenso negli ultimi nove mesi e un elenco di documenti NeRF derivati o esplorativi gestito da Reddit attualmente elenca sessanta progetti.
Formazione conveniente
Il documento è una collaborazione tra ricercatori della Shanghai Tech University e DGene Digital Technology , ed è stato accettato con un certo entusiasmo da Open Review .
ST-NeRF offre una serie di innovazioni rispetto alle iniziative precedenti negli spazi video navigabili derivati dal ML. Non da ultimo, raggiunge un alto livello di realismo con solo 16 telecamere. Sebbene DyNeRF di Facebook utilizzi solo due fotocamere in più, offre un arco navigabile molto più limitato.
Oltre a non avere la capacità di modificare e comporre singole sfaccettature, DyNeRF è particolarmente costoso in termini di risorse computazionali. Al contrario, i ricercatori cinesi affermano che il costo di formazione per i loro dati è compreso tra $ 900- $ 3.000, rispetto ai $ 30.000 per il modello di generazione video all’avanguardia DVDGAN e sistemi intensivi come DyNeRF.
I revisori hanno anche notato che ST-NeRF rappresenta un’importante innovazione nel disaccoppiare il processo di apprendimento del movimento dal processo di sintesi delle immagini. Questa separazione è ciò che consente l’editing e il compositing, con approcci precedenti restrittivi e lineari al confronto.
Sebbene 16 telecamere siano un array molto limitato per un semicerchio visivo così completo, i ricercatori sperano di ridurre ulteriormente questo numero nel lavoro successivo attraverso l’uso di sfondi statici pre-scansionati proxy e più approcci di modellazione delle scene basati sui dati. Sperano anche di incorporare capacità di reilluminazione , una recente innovazione nella ricerca NeRF.
Affrontare le limitazioni di ST-NeRF
Nel contesto di documenti accademici CS che tendono a cestinare l’effettiva usabilità di un nuovo sistema in un paragrafo finale usa e getta, anche i limiti che i ricercatori riconoscono per ST-NeRF sono insoliti.
Osservano che il sistema attualmente non può individuare e rendere separatamente oggetti particolari in una scena, perché le persone nel filmato sono segmentate in entità individuali tramite un sistema progettato per riconoscere gli esseri umani e non gli oggetti – un problema che sembra facilmente risolvibile con YOLO e simili framework, con il lavoro più duro di estrarre il video umano già completato.
Sebbene i ricercatori notino che attualmente non è possibile generare slow motion, sembra che ci sia poco per impedirne l’implementazione utilizzando le innovazioni esistenti nell’interpolazione dei frame come DAIN e RIFE .
Come con tutte le implementazioni NeRF, e in molti altri settori della ricerca sulla visione artificiale, ST-NeRF può fallire in casi di grave occlusione, dove il soggetto è temporaneamente oscurato da un’altra persona o da un oggetto e può essere difficile da tracciare continuamente o con precisione riacquistare in seguito. Come altrove, questa difficoltà potrebbe dover attendere soluzioni a monte. Nel frattempo, i ricercatori ammettono che è necessario un intervento manuale in questi frame occlusi.
Infine, i ricercatori osservano che le procedure di segmentazione umana attualmente si basano su differenze di colore, il che potrebbe portare alla collazione involontaria di due persone in un blocco di segmentazione – un ostacolo non limitato a ST-NeRF, ma intrinseco alla libreria utilizzata e che potrebbe forse essere risolto mediante analisi del flusso ottico e altre tecniche emergenti.