Creazione di un modello linguistico in stile GPT per una singola domanda
I ricercatori cinesi hanno sviluppato un metodo economico per creare sistemi di elaborazione del linguaggio naturale in stile GPT-3, evitando la spesa sempre più proibitiva di tempo e denaro coinvolti nella formazione di set di dati ad alto volume – una tendenza in crescita che altrimenti rischia di relegare alla fine questo settore dell’IA ai giocatori FAANG e agli investitori di alto livello.
Il framework proposto è chiamato Task-Driven Language Modeling (TLM). Invece di addestrare un modello enorme e complesso su un vasto corpus di miliardi di parole e migliaia di etichette e classi, TLM addestra invece un modello molto più piccolo che incorpora effettivamente una query direttamente all’interno del modello.
A sinistra, un tipico approccio iperscala a modelli linguistici ad alto volume; a destra, il metodo snello di TLM per esplorare un ampio corpus linguistico in base all’argomento o alla domanda. Fonte: https://arxiv.org/pdf/2111.04130.pdf
In effetti, viene prodotto un algoritmo o modello di PNL unico per rispondere a una singola domanda, invece di creare un modello linguistico generale enorme e ingombrante in grado di rispondere a una più ampia varietà di domande.
Nel testare TLM, i ricercatori hanno scoperto che il nuovo approccio ottiene risultati simili o migliori rispetto ai modelli linguistici pre-addestrati come RoBERTa-Large e ai sistemi NLP iperscala come GPT-3 di OpenAI , TRILLION Parameter Switch Transformer Model di Google , HyperClover coreano , AI21 Jurassic 1 di Labs e Megatron-Turing NLG 530B di Microsoft .
Nelle prove di TLM su otto set di dati di classificazione in quattro domini, gli autori hanno inoltre scoperto che il sistema riduce i FLOP di addestramento ( operazioni in virgola mobile al secondo ) richiesti di due ordini di grandezza. I ricercatori sperano che il TLM possa “democratizzare” un settore che sta diventando sempre più d’élite, con modelli di PNL così grandi da non poter essere realisticamente installati localmente, e invece sedersi, nel caso di GPT-3, dietro le API costose e ad accesso limitato di OpenAI e, ora, Microsoft Azure .
Gli autori affermano che la riduzione del tempo di formazione di due ordini di grandezza riduce i costi di formazione di oltre 1.000 GPU per un giorno a sole 8 GPU in 48 ore.
Il nuovo rapporto si intitola NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework e proviene da tre ricercatori della Tsinghua University di Pechino e da un ricercatore della società di sviluppo AI con sede in Cina Recurrent AI, Inc.
Risposte inaccessibili
Il costo della formazione di modelli linguistici efficaci e universali si caratterizza sempre più come un potenziale “limite termico” alla misura in cui la PNL performante e accurata può realmente diffondersi nella cultura.
Statistiche sulla crescita delle sfaccettature nelle architetture dei modelli NLP, da un rapporto del 2020 di A121 Labs. Fonte: https://arxiv.org/pdf/2004.08900.pdf
Nel 2019 un ricercatore ha calcolato che costa $ 61.440 USD addestrare il modello XLNet (riferito all’epoca per battere BERT nelle attività NLP) per 2,5 giorni su 512 core su 64 dispositivi, mentre si stima che GPT-3 sia costato $ 12 milioni per l’addestramento – 200 volte la spesa per l’addestramento del suo predecessore, GPT-2 (sebbene recenti stime affermino che potrebbe essere addestrato ora per soli $ 4.600.000 sulle GPU cloud più economiche) .
Sottoinsiemi di dati in base alle esigenze di query
Invece, la nuova architettura proposta cerca di derivare classificazioni, etichette e generalizzazioni accurate utilizzando una query come una sorta di filtro per definire un sottoinsieme di informazioni da un ampio database linguistico che verrà addestrato, insieme alla query, al fine di fornire risposte su un argomento limitato.
Gli autori affermano:
‘TLM è motivato da due idee chiave. In primo luogo, gli esseri umani padroneggiano un compito utilizzando solo una piccola parte della conoscenza del mondo (ad esempio, gli studenti devono solo ripassare alcuni capitoli, tra tutti i libri del mondo, per stiparsi per un esame).
‘Ipotizziamo che ci sia molta ridondanza nel grande corpus per un compito specifico. In secondo luogo, la formazione su dati etichettati supervisionati è molto più efficiente in termini di dati per le prestazioni a valle rispetto all’ottimizzazione dell’obiettivo di modellazione linguistica su dati non etichettati. Sulla base di queste motivazioni, TLM utilizza i dati dell’attività come query per recuperare un piccolo sottoinsieme del corpus generale. Questo è seguito dall’ottimizzazione congiunta di un obiettivo del compito supervisionato e di un obiettivo di modellazione del linguaggio utilizzando sia i dati recuperati che i dati del compito.’
Oltre a rendere accessibile la formazione sui modelli di PNL altamente efficace, gli autori vedono una serie di vantaggi nell’utilizzo di modelli di PNL basati su attività. Per uno, i ricercatori possono godere di una maggiore flessibilità, con strategie personalizzate per la lunghezza della sequenza, la tokenizzazione, l’ottimizzazione degli iperparametri e le rappresentazioni dei dati.
I ricercatori prevedono anche lo sviluppo di futuri sistemi ibridi che scambino una limitata pre-formazione di un PLM (che altrimenti non è prevista nell’attuale implementazione) con una maggiore versatilità e generalizzazione rispetto ai tempi di formazione. Considerano il sistema un passo avanti per il progresso dei metodi di generalizzazione zero-shot all’interno del dominio.
Test e risultati
Il TLM è stato testato su sfide di classificazione in otto attività su quattro domini: scienze biomediche, notizie, recensioni e informatica. Le attività sono state suddivise in categorie ad alta e bassa risorsa. Le attività con risorse elevate includevano oltre 5.000 dati di attività, come AGNews e RCT , tra gli altri; le attività a bassa risorsa includevano ChemProt e ACL-ARC , nonché il set di dati di rilevamento delle notizie HyperPartisan .
I ricercatori hanno sviluppato due set di formazione denominati Corpus-BERT e Corpus-RoBERTa, quest’ultimo dieci volte più grande del primo. Gli esperimenti hanno confrontato i modelli generali Pretrained Language BERT (da Google) e RoBERTA (da Facebook) alla nuova architettura.
Il documento osserva che sebbene TLM sia un metodo generale e dovrebbe essere più limitato nell’ambito e nell’applicabilità rispetto a modelli all’avanguardia più ampi e di volume più elevato, è in grado di eseguire metodi di regolazione fine adattativi al dominio.
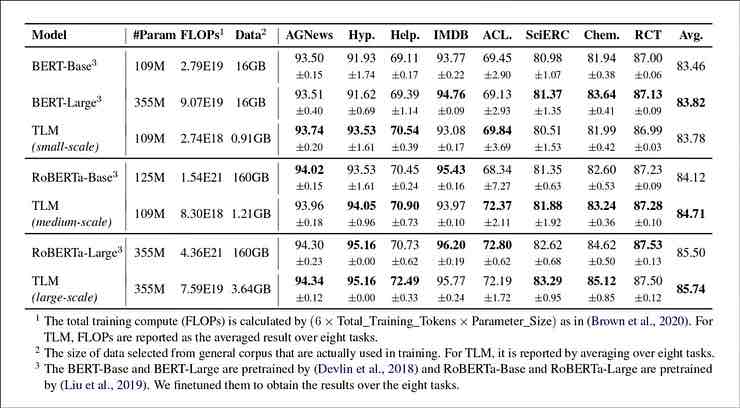
Risultati dal confronto delle prestazioni del TLM con i set basati su BERT e RoBERTa. I risultati elencano un punteggio F1 medio su tre diverse scale di allenamento ed elencano il numero di parametri, il calcolo totale dell’allenamento (FLOP) e la dimensione del corpus di allenamento.
Gli autori concludono che il TLM è in grado di ottenere risultati comparabili o migliori dei PLM, con una sostanziale riduzione dei FLOP necessari e richiedendo solo 1/16 del corpus di formazione. Su scale medie e grandi, TLM apparentemente può migliorare le prestazioni di 0,59 e 0,24 punti in media, riducendo al contempo le dimensioni dei dati di addestramento di due ordini di grandezza.
‘Questi risultati confermano che il TLM è estremamente accurato e molto più efficiente dei PLM. Inoltre, TLM ottiene maggiori vantaggi in termini di efficienza su scala più ampia. Ciò indica che i PLM su larga scala potrebbero essere stati formati per memorizzare conoscenze più generali che non sono utili per un’attività specifica.’