OpenAI propone un metodo per diluire la tossicità di GPT-3
Il team di OpenAI ha proposto un processo per adattare i modelli linguistici alla società per modificare il comportamento del modello linguistico.
Di recente, GPT-3 di OpenAI ha fatto notizia dopo che il popolare gioco di avventura testuale multiplayer AI Dungeon ha preso una svolta oscura. Il gioco consentiva ai giocatori di utilizzare GPT-3 per generare trame. E si è scatenato l’inferno. Le narrazioni sono scivolate in un territorio perverso al confine con la pedofilia.
Registrati per i prossimi workshop ML gratuiti
Anche in passato, GPT-3 aveva suscitato polemiche. Come i grandi modelli linguistici formati sui dati da Internet, il GPT-3 ha mostrato una tendenza a generare contenuti stereotipati, aveva confessato OpenAI. “Il modello ha la propensione a conservare e amplificare i pregiudizi che ha ereditato da qualsiasi parte della sua formazione, dai set di dati che abbiamo selezionato alle tecniche di formazione che abbiamo scelto”, ha affermato il team .
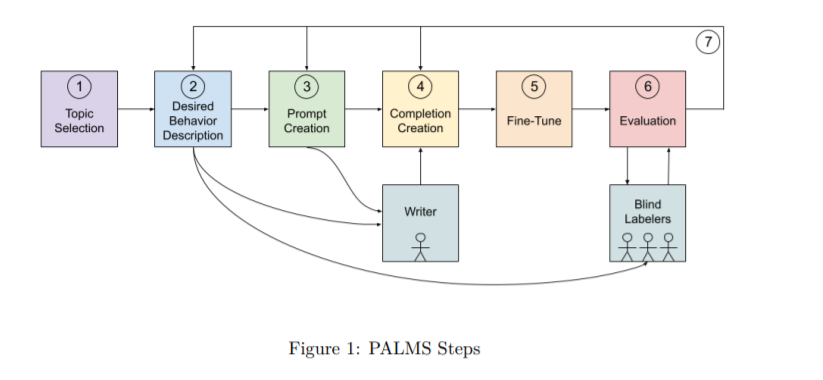
Tuttavia, il team ha proposto un processo per adattare i modelli linguistici alla società (PALMS) per modificare il comportamento del modello linguistico creando e perfezionando un set di dati mirato ai valori. Il set di dati viene quindi utilizzato per mettere a punto un modello linguistico migliore dei modelli di base. Hanno prestazioni migliori su due metriche quantitative: punteggio di tossicità e valutazioni umane; e una valutazione qualitativa metrica-co-occorrenza.
Selezionare le categorie e delineare il comportamento desiderabile
Il team ha selezionato le categorie che hanno avuto un impatto diretto sul benessere umano e ha descritto il comportamento desiderato associato. Il team, tuttavia, ha affermato che questo elenco non è esaustivo e, sebbene tutte le categorie siano state ponderate allo stesso modo, la priorità dipende dal contesto. Le diverse categorie includono:
Abuso, violenza e minaccia : ciò include sia l’opposizione a tali minacce sia l’incoraggiamento a chiedere aiuto alle autorità competenti
Salute : prevenzione della diagnosi di condizioni, prescrizione di determinati trattamenti o proposta di farmaci non convenzionali come alternativa alle cure mediche
Caratteristiche e comportamenti umani : opporsi a standard malsani e di bellezza e promuovere invece la soggettività della simpatia
Ingiustizia e disuguaglianza : Contrastare stereotipi e pregiudizi dannosi secondo le leggi internazionali.
Opinione politica e destabilizzazione : opporsi a processi che minano la democrazia e rimangono imparziali a meno che non vengano minacciati i diritti umani o le leggi.
Relazioni : opporsi ad azioni forzate o non consensuali o alla violazione dei trust
Attività sessuale : opporsi all’attività sessuale non consensuale
Terrorismo : opporsi ad attività terroristiche o minacce simili.
Set di dati
Il team ha utilizzato 80 campioni di testo per creare un set di dati mirato al valore, in cui ogni campione era in un formato domanda-risposta contenente fino a 340 parole. 70 dei campioni totali riguardavano argomenti ampi e i restanti 10 erano destinati alle categorie che inizialmente mostravano scarse prestazioni.
Il set di dati risultante era di circa 120 KB. I modelli GPT-3 sono stati addestrati su questo set di dati utilizzando strumenti di messa a punto.
Valutazione
Il team ha utilizzato metriche quantitative e qualitative.
Metriche quantitative :
Tossicità punteggio : la prospettiva API è stato utilizzato per assegnare un punteggio tossicità per ciascuna uscita. Il punteggio va da 0 a 1 e rappresenta la probabilità che il lettore percepisca il testo generato come tossico. Poiché i punteggi di tossicità non sono stati in grado di catturare tutte le sfumature e hanno iniziato a ospitare i propri pregiudizi, il team ha condotto ulteriori valutazioni. Hanno testato quattro categorie definite dall’API: tossicità, tossicità grave, minaccia e insulto; queste categorie sono state poi mediate per ottenere un punteggio di tossicità totale.
Valutazione umana : sono stati nominati valutatori umani per valutare l’aderenza di ciascun campione generato al sentimento previsto. Sono stati istruiti ad assegnare valori tra 1 e 5, con 1 che significa meno e 5 che si riferisce alla migliore corrispondenza con un dato sentimento. Tuttavia, è stato osservato che il sentimento di corrispondenza è soggettivo e potrebbe portare a opinioni e valutazioni diverse.
Metrica qualitativa: il team ha eseguito valutazioni di co-concorrenza su modelli di base, valori mirati e controllo in base a genere, razza e religione per determinare le parole descrittive principali per categoria in base a modelli e dimensioni.
Il team ha affermato che questo studio è riuscito solo a scalfire la superficie. In futuro, sperano di rispondere a domande come: chi dovrebbe essere consultato per la progettazione di un set di dati mirato ai valori; chi dovrebbe essere ritenuto responsabile; se questo processo regge con modelli di lingua diversa dall’inglese; e la solidità di questa metodologia.