PREVISIONE PERCENTUALE DI CLIC (CTR) DELL’ANNUNCIO MEDIANTE L’APPRENDIMENTO PER RINFORZO
apprendimento di rinforzo in Pyton
Ci sono quasi tutti i siti Web su Internet che visualizzano annunci pubblicitari. Le aziende che desiderano pubblicizzare i propri prodotti scelgono questi siti Web come mezzo di pubblicità. La sfida è che se l’azienda ha una gamma di versioni pubblicitarie, che tra queste versioni possono ottenere il tasso di conversione più elevato, ovvero il numero massimo di clic sull’annuncio.
In questo articolo, discuteremo dell’apprendimento del rinforzo in Python per la previsione della percentuale di clic (CTR) delle pubblicità sul web. Vedremo l’implementazione pratica di Upper Confidence Bound (UCB), un metodo di rinforzo dell’apprendimento applicato in questo compito. Usando questa implementazione, si può essere in grado di trovare la migliore versione dell’annuncio da una serie di versioni disponibili che possono ottenere un numero massimo di clic dai visitatori sul sito Web.
Il metodo Upper Confidence Bound (UCB)
L’algoritmo Upper Confidence Bound (UCB) appartiene alla famiglia di algoritmi di Reinforcement Learning. Questo metodo viene applicato nella selezione dell’azione dove utilizza l’incertezza nelle stime del valore dell’azione per bilanciare esplorazione e sfruttamento. Questo metodo è comunemente usato per risolvere il problema del bandito multi-braccio.
Il set di dati
In questo esperimento, abbiamo utilizzato il set di dati di ottimizzazione CTR degli annunci disponibile pubblicamente su Kaggle . Questo set di dati comprende la risposta di 10.000 visitatori a 10 annunci pubblicitari visualizzati su una piattaforma web. Queste 10 pubblicità sono in realtà le 10 versioni di annunci dello stesso prodotto. Le risposte sono rappresentate in termini di premi dati a quei 10 annunci dai visitatori. Se il visitatore ha fatto clic su un annuncio, il premio è 1 e se il visitatore ha ignorato l’annuncio, il premio è 0. Ora, in base a questi premi, l’attività è identificare quale tra i 10 annunci ha il CTR più alto in modo che l’annuncio con il tasso di conversione più elevato deve essere posizionato sulla piattaforma web.
Implementazione di Upper Confidence Bound (UCB)
In questo apprendimento di rinforzo nell’implementazione di Python, confronteremo due approcci: selezione casuale di annunci e selezione utilizzando il metodo UCB in modo da poter concludere l’efficacia del metodo UCB. Innanzitutto, dobbiamo importare le librerie richieste e quindi il set di dati che abbiamo scaricato da Kaggle.
L’importazione delle librerie
importa numpy come np
import matplotlib.pyplot come plt
import panda come pd
Importazione del set di
dati dataset = pd.read_csv (‘Ads_CTR_Optimisation.csv’)
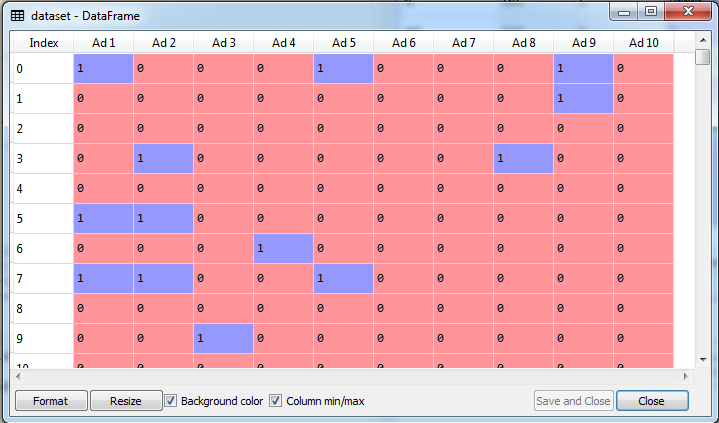
set di dati clic web ad
Come possiamo vedere il set di dati nella figura sopra, comprende i valori 1 o 0 per 10 annunci visualizzati sul sito Web. Ogni riga del set di dati rappresenta un visitatore del sito Web. Se il visitatore ha fatto clic sull’annuncio, il valore per quell’annuncio è 1 e se il visitatore ha ignorato l’annuncio, il valore per quell’annuncio è 0. Nel set di dati ci sono 10.000 di tali record.
Utilizzando il metodo di selezione casuale
Per vedere la differenza, in primo luogo, dobbiamo vedere come funziona la selezione casuale delle versioni degli annunci. Dal set di 10 versioni di annunci, un annuncio viene selezionato a caso e visualizzato al visitatore.
Implementazione della selezione
casuale importazione casuale
N = 10000
d = 10
ads_selected = []
total_reward = 0
per n nell’intervallo (0, N):
ad = random.randrange (d)
ads_selected.append (annuncio)
premio = dataset.values [n , ad]
total_reward = total_reward +ward
Visualizzazione dei risultati
plt.hist (ads_selected)
plt.title (‘Istogramma delle selezioni degli annunci’)
plt.xlabel (‘Annunci’)
plt.ylabel (‘Numero di volte in cui ogni annuncio è stato selezionato’ )
plt.show ()
Una volta eseguito lo snippet di codice sopra riportato, l’algoritmo sopra seleziona un annuncio a caso e viene visualizzato prima del visitatore. Se il visitatore fa clic sull’annuncio, viene aggiunto il premio 1 e se il visitatore lo ignora, viene aggiunto lo 0 premiato. Vedi nello screenshot qui sotto questa selezione casuale di annunci.
selezione casuale di annunci web
Come possiamo vedere nella figura sopra, per il primo utente è stato visualizzato il secondo annuncio (tenere presente gli indici in Python) e è stato aggiunto lo 0 premiato. Per il secondo utente, è stato selezionato il 5 ° annuncio ed è stato aggiunto il premio 1. Allo stesso modo, questa selezione casuale e l’aggiunta della ricompensa continuano fino all’ultimo, 10.000esimo visitatore. In questo modo, il valore della ricompensa totale viene calcolato in modo iterativo.
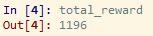
ricompensa dell’apprendimento per rinforzo
Quindi, come possiamo vedere, la ricompensa totale usando il metodo di selezione casuale è 1196. Ora, visualizziamo attraverso l’istogramma il numero di volte in cui è stato fatto clic su ogni annuncio.
inseriamo un istogramma di selezione casuale
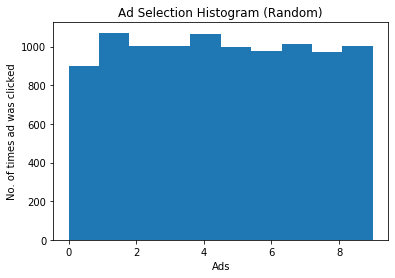
Tieni presente che l’intero processo di selezione casuale degli annunci, incluso l’istogramma sopra e la ricompensa totale, varierà ad ogni esecuzione del programma.
Utilizzando il metodo UCB
Nella sezione precedente abbiamo visto la selezione casuale di annunci e premi ricevuti. Ora vedremo l’implementazione di Upper Confidence bound (UCB) nello stesso compito. Si prega di fare riferimento alle formule nell’articolo di cui sopra per una migliore comprensione.
Upper Confidence Limite
dell’importazione associato
N = 10000
d = 10
ads_selected = []
numbers_of_selections = [0] * d
sums_of_rewards = [0] * d
total_reward = 0
per n nell’intervallo (0, N):
ad = 0
max_upper_bound = 0
per i nell’intervallo (0, d):
if (numbers_di_selezioni [i]> 0):
average_reward = sums_of_rewards [i] / numbers_of_selections [i]
delta_i = math.sqrt (3/2 * math.log (n + 1) / numbers_of_selections [i])
upper_bound = average_reward + delta_i
else:
upper_bound = 1e400
se upper_bound> max_upper_bound:
max_upper_bound = upper_bound
ad = i
ads_selected.append (annuncio)
numbers_of_selections [annuncio] = numbers_of_selections [annuncio] + 1
premio = dataset.values [n, annuncio]
sums_of_rewards [annuncio] = sums_of_rewards [annuncio] + premio
total_reward = total_reward + premio
Visualizzazione dei risultati
plt.hist (ads_selected)
plt.title (‘Istogramma delle selezioni degli annunci’)
plt.xlabel (‘Annunci’)
plt.ylabel (‘Numero di volte in cui ogni annuncio è stato selezionato’)
plt.show ()
Quando verrà eseguito lo snippet di codice sopra riportato, per prima cosa vedremo la selezione di annunci da visualizzare prima di ogni visitatore.
apprendimento di rinforzo ucb nella selezione di annunci python
Per il primo visitatore, viene visualizzato il primo annuncio e viene aggiunto il premio 1. Questo processo continua come abbiamo visto nella sezione precedente. Per gli ultimi visitatori, puoi vedere quel 4 ° come viene visualizzato la maggior parte delle volte. Questo perché la quarta pubblicità viene per lo più premiata positivamente dai visitatori. Quindi l’algoritmo ha seguito questa tendenza e visualizza la quarta pubblicità per la maggior parte del tempo.
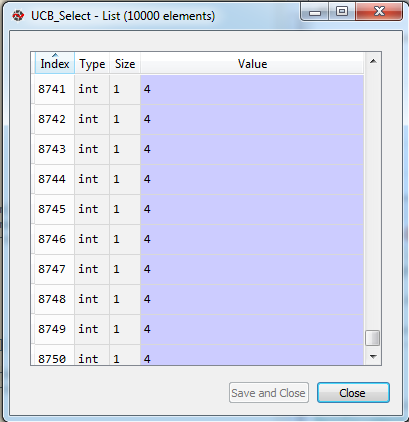
apprendimento di rinforzo ucb nella selezione di annunci python
La stessa tendenza può essere vista nell’istogramma indicato di seguito in cui il 4 ° annuncio ha il maggior numero di clic.
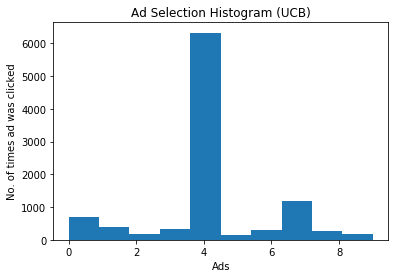
apprendimento di rinforzo ucb nella selezione di annunci python
Infine, vedremo la ricompensa totale quando si utilizza l’algoritmo UCB.
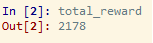
ricompensa nell’apprendimento di rinforzo
La ricompensa totale ricevuta usando l’algoritmo UCB è quasi il doppio della ricompensa totale ricevuta nella selezione casuale. Infine, possiamo concludere che l’algoritmo Upper Confidence Bound (UCB) aiuta a trovare l’annuncio migliore da una serie di versioni dell’annuncio da visualizzare ai visitatori in modo da ottenere il massimo clic e il più alto tasso di conversione. Utilizzando questo numero di clic su ciascuno degli annunci e utilizzando il numero di impressioni, si può facilmente scoprire la percentuale di clic (CTR) di questi annunci. Il CTR può essere ottenuto come (Numero totale di clic / Impressione totale) x 100.
Spero che questa implementazione di Reinforcement Learning in Python ti aiuti a imparare come aiuta nell’analisi predittiva.