La visione del computer viene applicata in una varietà di applicazioni in tutti i domini e grazie al deep learning che fornisce continuamente nuovi framework da utilizzare nello spazio di visione del computer. Ad oggi, ci possono essere più di centinaia di modelli di apprendimento profondo che hanno dimostrato le loro capacità nel gestire milioni di immagini e produrre risultati accurati. Ogni modello di apprendimento profondo ha un’architettura specifica ed è addestrato in quel modo specifico. Le reti neurali convoluzionali sono uno dei popolari modelli di deep learning che hanno una vasta gamma di applicazioni nel campo della visione artificiale.
Esiste una varietà di architetture della rete neurale convoluzionale (CNN). AlexNet è una delle varianti della CNN che viene anche definita rete neurale convoluzionale profonda. In questo articolo, discuteremo dell’architettura e dell’implementazione di AlexNet utilizzando la libreria Keras senza utilizzare l’approccio di apprendimento del trasferimento. Alla fine, valuteremo le prestazioni di questo modello in classifica.
AlexNet
AlexNet è un modello di apprendimento profondo ed è una variante della rete neurale convoluzionale. Questo modello è stato proposto da Alex Krizhevsky come suo lavoro di ricerca . Il suo lavoro è stato supervisionato da Geoffery E. Hinton, un nome noto nel campo della ricerca sull’apprendimento profondo. Alex Krizhevsky ha partecipato alla Sfida di riconoscimento visivo su larga scala ImageNet (ILSVRC2012) nel 2012, dove ha utilizzato il modello AlexNet e ha ottenuto un errore top-5 del 15,3%, oltre 10,8 punti percentuali in meno rispetto al secondo classificato.
Architettura di AlexNet
L’AlexNet proposto da Alex Krizhevsky nel suo lavoro ha otto livelli, inclusi cinque livelli convoluzionali seguiti da tre livelli completamente collegati. Alcuni strati convoluzionali del modello sono seguiti da livelli di pool massimo. Come funzione di attivazione, la funzione ReLU viene utilizzata dalla rete che mostra prestazioni migliorate rispetto alle funzioni sigmoid e tanh.

architettura del modello alexnet
La rete è composta da un kernel o filtri con dimensioni 11 x 11, 5 x 5, 3 x 3, 3 x 3 e 3 x 3 per i suoi cinque strati convoluzionali rispettivamente. Il resto dei parametri della rete può essere regolato in base alle prestazioni di allenamento.
AlexNet che utilizza l’apprendimento del trasferimento che utilizza i pesi della rete pre-formata sul set di dati ImageNet ha mostrato prestazioni eccezionali. Ma in questo articolo, non useremo i pesi pre-allenati e semplicemente definiremo la CNN secondo l’architettura proposta.
Implementazione in Keras
Qui, implementeremo Alexnet in Keras secondo la descrizione del modello fornita nel lavoro di ricerca. Si noti che non lo useremo come modello pre-addestrato.
Questo codice è stato implementato in Google Colab e il file .py è stato scaricato.
– * – coding: utf-8 – * –
“” “AlexNet.ipynb Generato
automaticamente da Colaboratory.
Il file originale si trova in
https://colab.research.google.com/drive/14eAKHD0zCHJpw5uxxxxxxxxxxxxx
“” “
Nel primo passo, definiremo la rete AlexNet usando la libreria Keras. I parametri della rete verranno mantenuti secondo le descrizioni precedenti, ovvero 5 livelli convoluzionali con dimensione del kernel 11 x 11, 5 x 5, 3 x 3, 3 x 3 rispettivamente, 3 livelli completamente collegati, ReLU come funzione di attivazione a tutti i livelli tranne quello di output. Poiché testeremo questo modello nella classificazione CIFAR10, a livello di output definiremo un livello Dense con 10 nodi.
Importazione di librerie
import keras
da keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
import numpy as np
np.random.seed (1000)
Instantiation
AlexNet = Sequential ()
1 ° strato convoluzionale
AlexNet.add (Conv2D (filtri = 96, input_shape = (32,32,3), kernel_size = (11,11), strides = (4,4), padding = ‘same’))
AlexNet.add (BatchNormalization ())
AlexNet.add (Activation (‘relu’))
AlexNet.add (MaxPooling2D (pool_size = (2,2), strides = (2,2), padding = ‘same’))
2 ° strato convoluzionale
AlexNet.add (Conv2D (filtri = 256, kernel_size = (5, 5), strides = (1,1), padding = ‘same’))
AlexNet.add (BatchNormalization ())
AlexNet.add (Attivazione (‘relu’))
AlexNet.add (MaxPooling2D (pool_size = (2,2), strides = (2,2), padding = ‘same’))
3 ° strato convoluzionale
AlexNet.add (Conv2D (filtri = 384, kernel_size = (3,3), strides = (1,1), padding = ‘same’))
AlexNet.add (BatchNormalization ())
AlexNet.add (Attivazione ( ‘Relu’))
4 ° strato convoluzionale
AlexNet.add (Conv2D (filtri = 384, kernel_size = (3,3), strides = (1,1), padding = ‘same’))
AlexNet.add (BatchNormalization ())
AlexNet.add (Attivazione ( ‘Relu’))
5 ° strato convoluzionale
AlexNet.add (Conv2D (filtri = 256, kernel_size = (3,3), strides = (1,1), padding = ‘same’))
AlexNet.add (BatchNormalization ())
AlexNet.add (Attivazione (‘relu’))
AlexNet.add (MaxPooling2D (pool_size = (2,2), strides = (2,2), padding = ‘same’))
Passaggio su un livello completamente connesso
AlexNet.add (Flatten ())
1 ° livello completamente connesso
AlexNet.add (denso (4096, input_shape = (32,32,3,)))
AlexNet.add (BatchNormalization ())
AlexNet .add (Activation (‘relu’))
Aggiungi Dropout per impedire il
sovradimensionamento di AlexNet.add (Dropout (0.4))
2 ° livello completamente connesso
AlexNet.add (denso (4096))
AlexNet.add (BatchNormalization ())
AlexNet.add (Activation (‘relu’))
Add Dropout
AlexNet.add (Dropout (0.4))
3 ° livello completamente connesso
AlexNet.add (denso (1000))
AlexNet.add (BatchNormalization ())
AlexNet.add (Activation (‘relu’))
Add Dropout
AlexNet.add (Dropout (0.4))
Output Layer
AlexNet.add (Dense (10))
AlexNet.add (BatchNormalization ())
AlexNet.add (Attivazione (‘softmax’))
Model Riepilogo
AlexNet.summary ()

alexnet in keras
Una volta definito il modello, compileremo questo modello e useremo Adam come ottimizzatore. Potremmo usare anche la discesa gradiente stocastica (sgd).
Compilazione del modello
AlexNet.compile (loss = keras.losses.categorical_crossentropy, optimizer = ‘adam’, metrics = [‘accuratezza’])
Ora, poiché siamo pronti con il nostro modello, controlleremo le sue prestazioni in classifica. Allo stesso modo, useremo il set di dati CIFAR10 che è un punto di riferimento popolare nella classificazione delle immagini. Il set di dati CIFAR-10 è un set di dati di immagini disponibile al pubblico fornito dal Canadian Institute for Advanced Research (CIFAR). Si compone di 60000 immagini a colori 32 × 32 in 10 classi, con 6000 immagini per classe. Le 10 diverse classi rappresentano aerei, automobili, uccelli, gatti, cervi, cani, rane, cavalli, navi e camion. In questo set di dati sono presenti 50000 immagini di allenamento e 10000 immagini di test.
Per ulteriori informazioni sul set di dati CIFAR10 e la sua preelaborazione per una rete neurale convoluzionale, leggi il mio articolo ” Apprendimento di trasferimento per la classificazione di immagini multi-classe utilizzando la rete neurale convoluzionale profonda “.
La libreria Keras per il set
di
dati CIFAR da keras.dataset import cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data ()
Train-validation-test split
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split (x_train, y_train, test_size = .3)
Dimensione del set di dati CIFAR10
print ((x_train.shape, y_train.shape))
print ((x_val.shape, y_val.shape))
print ((x_test.shape, y_test.shape))

cifar 10
Onehot Codifica delle etichette.
da sklearn.utils.multiclass importa unique_labels
da keras.utils importa in_categorical
Poiché abbiamo 10 classi dovremmo aspettarci che la forma [1] di y_train, y_val e y_test cambi da 1 a 10
y_train = to_categorical (y_train)
y_val = to_categorical (y_val)
y_test = to_categorical (y_test)
Verificare la dimensione dopo una
stampa con
codifica a caldo ((x_train.shape, y_train.shape)) print ((x_val.shape, y_val.shape))
print ((x_test.shape, y_test.shape))
cifar 10
Image Data Augmentation
da keras.preprocessing.image import ImageDataGenerator
train_generator = ImageDataGenerator (rotation_range = 2, horizontal_flip = True, zoom_range = .1)
val_generator = ImageDataGenerator (rotation_range = 2, horizontal_flip = True, zoom_range = .1)
test_generator = ImageDataGenerator (rotation_range = 2, horizontal_flip = True, zoom_range = .1)
Adattamento dell’aumento definito sopra ai dati
train_generator.fit (x_train)
val_generator.fit (x_val)
test_generator.fit (x_test)
Dopo aver preelaborato il set di dati CIFAR10, siamo ora pronti per addestrare il nostro modello AlexNet definito. In questo esperimento utilizzeremo la ricottura del tasso di apprendimento. La ricottura del tasso di apprendimento riduce il tasso di apprendimento dopo un certo numero di epoche se il tasso di errore non cambia. Qui, attraverso questa tecnica, monitoreremo l’accuratezza della validazione e se sembra essere un plateau in 3 epoche, ridurrà il tasso di apprendimento di 0,01.
Learning Annealer dei tassi
da keras.callbacks import ReduceLROnPlateau
lrr = ReduceLROnPlateau (monitor = ‘val_acc’, factor = .01, pazienza = 3, min_lr = 1e-5)
Per formare il modello, definiremo di seguito il numero di epoche, il numero di lotti e il tasso di apprendimento.
Definizione dei parametri
batch_size = 100
epoche = 100
learn_rate = .001
Ora, formeremo il nostro modello AlexNet definito.
Training del modello
AlexNet.fit_generator (train_generator.flow (x_train, y_train, batch_size = batch_size), epochs = epochs, steps_per_epoch = x_train.shape [0] // batch_size, validation_data = val_generator.flow = x_ batch, val ), validation_steps = 250, callbacks = [lrr], verbose = 1)


formazione alexnet formazione alexnet
Dopo una formazione di successo, visualizzeremo le sue prestazioni.
import matplotlib.pyplot come plt
Stampa della perdita di addestramento e convalida
f, ax = plt.subplots (2,1) # Crea 2 sottotrame sotto 1 colonna
Assegnazione della prima sottotrama per rappresentare graficamente la perdita di allenamento e la perdita di convalida
ax [0] .plot (AlexNet.history.history [‘perdita’], color = ‘b’, label = ‘Perdita di allenamento’)
ax [0] .plot ( AlexNet.history.history [‘val_loss’], color = ‘r’, label = ‘Perdita di convalida’)
Stampa dell’accuratezza dell’allenamento e dell’accuratezza della convalida
ax [1] .plot (AlexNet.history.history [‘accuratezza’], color = ‘b’, label = ‘Training Accuracy’)
ax [1] .plot (AlexNet.history. history [‘val_accuracy’], color = ‘r’, label = ‘Precisione di convalida’)
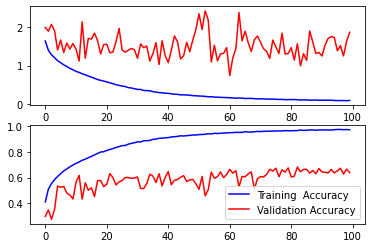
plt.legend ()
prestazioni di allenamento alexnet
Vedremo le prestazioni della classificazione usando matrici di confusione non normalizzate e normalizzate. A tal fine, per prima cosa, definiremo una funzione attraverso la quale verranno tracciate le matrici di confusione.
Definizione della funzione per il diagramma della matrice di confusione
def plot_confusion_matrix (y_true, y_pred, classes,
normalize = False,
title = None,
cmap = plt.cm.Blues):
se non titolo:
se normalizza:
title = ‘Matrice di confusione normalizzata’
altro:
titolo = “Matrice di confusione, senza normalizzazione”
# Calcola matrice di confusione
cm = matrice di confusione (y_true, y_pred) se normalizza:
cm = cm.astype (‘float’) / cm.sum (axis = 1) [:, np.newaxis]
print (“Matrix di confusione normalizzata”)
altro :
print (‘Matrice di confusione, senza normalizzazione’)
Stampa Matrice confusione
fig, ax = plt.subplots (figsize = (7,7))
im = ax.imshow (cm, interpolazione = 'più vicino', cmap = cmap)
ax.figure.colorbar (im, ax = ax)
# Vogliamo mostrare tutti i tick ...
ax.set (xticks = np.arange (cm.shape [1]),
yticks = np.arange (cm.shape [0]), xticklabels = classi, yticklabels = classi, title = title, ylabel = ‘Etichetta vera’, xlabel = ‘Etichetta prevista’)
# Ruota le etichette dei tick e imposta il loro allineamento.
plt.setp (ax.get_xticklabels (), rotazione = 45, ha = "destra",
rotation_mode = "anchor")
# Passa sopra le dimensioni dei dati e crea annotazioni di testo.
fmt = '.2f' se normalizza altrimenti 'd'
trebbia = cm.max () / 2.
per i nell'intervallo (cm.shape [0]):
per j nell'intervallo (cm.shape [1]):
ax. testo (j, i, formato (cm [i, j], fmt),
ha = "center", va = "center",
color = "white" se cm [i, j]> trebbia "nero")
fig .tight_layout ()
restituisce axnp.set_printoptions (precisione = 2)
Nel prossimo passo, prediremo le etichette di classe per le immagini di prova utilizzando il modello AlexNet addestrato.
Facendo la previsione
y_pred = AlexNet.predict_classes (x_test)
y_true = np.argmax (y_test, axis = 1)
Plotting della matrice di confusione
da sklearn.metrics import confusion_matrix
confusion_mtx = confusion_matrix (y_true, y_pred)
class_names = [‘aereo’, ‘automobile’, ‘uccello’, ‘gatto’, ‘cervo’, ‘cane’, ‘rana’, ‘cavallo’, ‘nave’, ‘camion’]
Tracciamento della matrice di confusione non normalizzata plot_confusion_matrix (y_true, y_pred, classes = class_names, title = ‘Matrice di confusione, senza normalizzazione’)
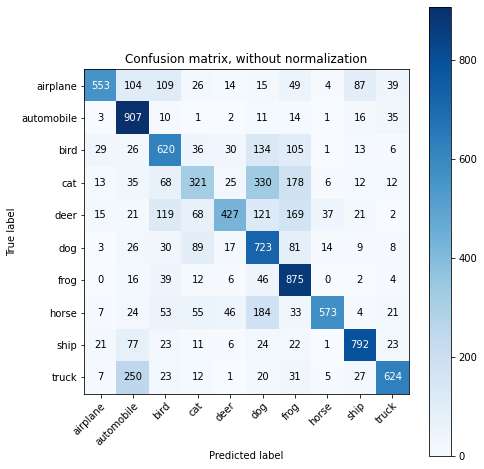
matrice di confusione
Stampa della matrice di confusione normalizzata
plot_confusion_matrix (y_true, y_pred, classes = class_names, normalize = True, title = ‘Matrix di confusione normalizzata’)
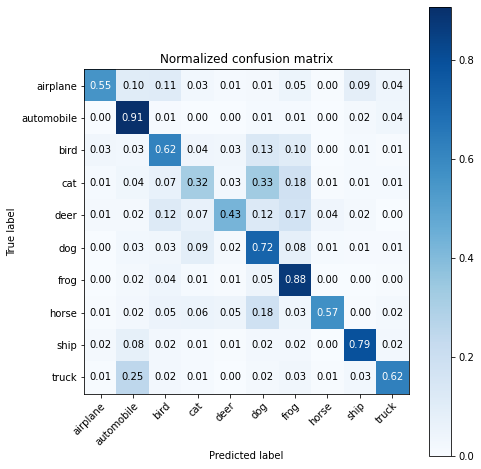
matrice di confusione
Il punteggio medio di accuratezza nella classificazione dei dati di test non visti sarà ottenuto ora.
Accuratezza
di classificazione da sklearn.metrics import accurate_score
acc_score = accurate_score (y_true, y_pred)
print (‘Accuracy Score =’, acc_score)

punteggio di precisione alexnet
Come possiamo vedere sopra, analizzando le matrici di confusione e il punteggio di precisione, le prestazioni di AlexNet non sono molto buone e il punteggio di precisione medio è del 64,8%. Questo perché non abbiamo utilizzato l’approccio di apprendimento del trasferimento. Il nostro scopo principale in questo articolo era dimostrare l’architettura del modello AlexNet e come può essere definito usando la libreria Keras. Nel prossimo articolo, useremo il modello AlexNet in cui viene applicato l’apprendimento del trasferimento utilizzando i pesi pre-allenati.