I ricercatori rilasciano il set di dati Melinda per addestrare i sistemi di intelligenza artificiale all’analisi dei metodi di studio
La cura degli studi biologici è un processo importante ma laborioso eseguito dai ricercatori nei settori delle scienze della vita. Tra gli altri compiti, i curatori devono riconoscere i metodi sperimentali, identificando i protocolli sottostanti che mettono in rete le cifre pubblicate negli articoli di ricerca. In altre parole, i “biocuratori” devono prendere in considerazione cifre, didascalie e altro e prendere decisioni su come sono stati derivati. Ciò richiede un’etichettatura attenta, che non scala bene quando gli esperimenti classificano il totale in centinaia o migliaia.
Alla ricerca di una soluzione, i ricercatori dell’Università della California, Los Angeles; l’Università della California meridionale; Intuit; e la Chan Zuckerberg Initiative ha sviluppato un set di dati chiamato Multimodal Biomedical Experiment Method Classification (“Melinda” in breve) contenente 5.371 record di dati etichettati, tra cui 2.833 cifre da documenti biomedici accoppiati con didascalie di testo corrispondenti. L’idea era di vedere se i modelli di apprendimento automatico all’avanguardia potevano curare studi e revisori umani confrontando quei modelli su Melinda.
L’identificazione automatica dei metodi negli studi pone delle sfide ai sistemi di intelligenza artificiale. Uno è fondare i concetti visivi sul linguaggio; la maggior parte degli algoritmi multimodali si basa su moduli di rilevamento di oggetti per la messa a terra di concetti visivi e linguistici di granularità più fine. Tuttavia, poiché richiede uno sforzo extra da parte degli esperti e quindi è più costoso, le immagini scientifiche spesso mancano di annotazioni di oggetti di verità fondamentale. Ciò danneggia le prestazioni dei modelli di rilevamento pre-addestrati perché le etichette sono il modo in cui imparano a fare classificazioni.
MELINDA
In Melinda, ogni data entry è composta da una figura, una didascalia associata e un’etichetta del metodo di esperimento dal database IntACt. IntAct memorizza in un’ontologia etichette annotate manualmente per i tipi di metodi di esperimento accoppiati con identificatori di figure e l’ID del documento contenente le figure. I documenti – 1.497 in totale – provenivano dall’Open Access PubMed Central, un archivio di riviste di scienze della vita disponibili gratuitamente.
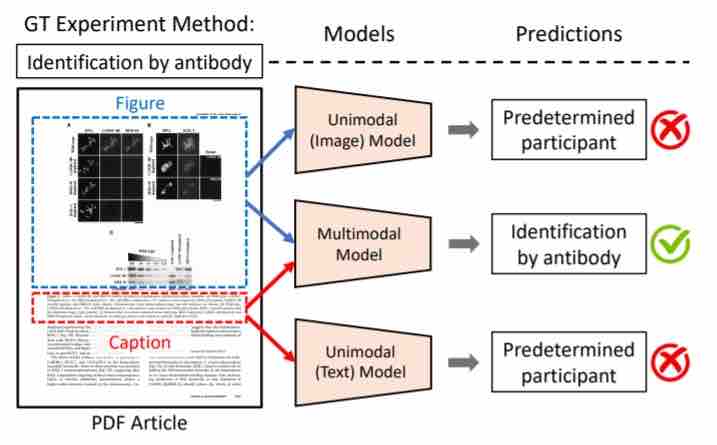
Negli esperimenti, i ricercatori hanno confrontato diversi modelli di visione, linguaggio e multimodali con Melinda. Nello specifico, hanno esaminato modelli unimodali che prendono un’immagine (solo immagine) o una didascalia (solo didascalia) come input e modelli multimodali che accettano entrambi.
I risultati suggeriscono che, nonostante il fatto che i modelli multimodali abbiano generalmente dimostrato prestazioni superiori rispetto agli altri, c’è spazio per miglioramenti. Il modello multimodale con le migliori prestazioni, VL-BERT, ha raggiunto una precisione compresa tra il 66,49% e il 90,83%, molto lontano dalla precisione del 100% di cui sono capaci i revisori umani.
I ricercatori sperano che il rilascio di Melinda motiva i progressi nei modelli multimodali, in particolare nelle aree dei domini a basse risorse e la dipendenza dai rilevatori di oggetti preaddestrati. “Il set di dati Melinda potrebbe servire come un buon banco di prova per il benchmarking”, hanno scritto in un documento che descrive il loro lavoro. “Il riconoscimento [compito] è fondamentalmente multimodale [e impegnativo], in cui la giustificazione dei metodi sperimentali prende in considerazione sia le cifre che le didascalie.”